TextGAN PyTorch
1.0.0
Textganは、一般的なテキスト生成モデルやカテゴリテキスト生成モデルを含む、生成敵対的ネットワーク(GAN)ベースのテキスト生成モデルのPytorchフレームワークです。 TextGanは、GANベースのテキスト生成モデルの研究をサポートするベンチマークプラットフォームとして機能します。ほとんどのGANベースのテキスト生成モデルはTensorflowによって実装されているため、TextganはPytorchに慣れている人がテキスト生成フィールドをより速く入力するのに役立ちます。
私の実装で間違いがある場合は、私に知らせてください!また、他のモデルを追加したい場合は、このリポジトリにお気軽に貢献してください。
インストールするには、 pip install -r requirements.txtを実行します。Txt。 CUDAの問題の場合は、公式のPytorch Get Guide Guideに相談してください。
Stable Release and Unzip:http://kheafield.com/code/kenlm.tar.gzをダウンロードしてください
ブースト> = 1.42.0とBJAMが必要です
sudo apt-get install libboost-all-devbrew install boost; brew install bjamKenlmディレクトリ内で実行します。
mkdir -p build
cd build
cmake ..
make -j 4 pip install https://github.com/kpu/kenlm/archive/master.zip
Kenlmの詳細については、https://github.com/kpu/kenlmおよびhttp://kheafield.com/code/kenlm/を参照してください。
git clone https://github.com/williamSYSU/TextGAN-PyTorch.git
cd TextGAN-PyTorchImage COCO 、 EMNLP NEWs 、 Movie Review 、 Amazon Review )をこちらからダウンロードできます。 cd run
python3 run_[model_name].py 0 0 # The first 0 is job_id, the second 0 is gpu_id
# For example
python3 run_seqgan.py 0 0インストラクター
各モデルについて、ラーンプロセス全体がinstructor/oracle_data/seqgan_instructor.pyで定義されます。 (たとえば、合成データ実験でseqganを取ります)。 init_model()やoptimize()などの基本的な関数は、 instructor.pyのベースクラスBasicInstructorで定義されています。新しいGANベースのテキスト生成モデルを追加する場合は、 instructor/oracle_dataの下に新しいインストラクターを作成し、モデルのトレーニングプロセスを定義してください。
視覚化
utils/visualization.pyを使用して、モデルの損失やメトリックスコアを含むログファイルを視覚化します。 log_file_listでログファイルをカスタマイズしますlen(color_list)ログファイル名は.txtを除外する必要があります。
ロギング
TextGan-Pytorchは、Pythonのloggingモジュールを使用して、発電機の損失やメートルスコアなどの実行プロセスを記録します。視覚化の便利さのために、 log/log_****_****.txtとsave/**/log.txt 。さらに、コードは、モデルの状態のdictと、 ./save/**/models **/modelsおよび./save/**/samples in log stepのバッチサイズのジェネレーターのサンプルを自動的に保存します。ここで、 **ハイパーパラメーターに依存します。
ランニング信号
辞書ファイルrun_signal.txtに基づいて、クラスSignal ( utils/helpers.pyを参照してください)でトレーニングプロセスを簡単に制御できます。
Signalを使用するには、ローカルファイルrun_signal.txtを編集し、 pre_sig Fasleに設定するだけで、プログラムはトレーニング前のプロセスを停止し、次のトレーニングフェーズに足を踏み入れます。現在のトレーニングで十分だと思われる場合は、トレーニングを早期に停止するのが便利です。
GPUを自動的に選択します
config.pyでは、プログラムは、 nvidia-smiでGPU-Utilが最小のGPUデバイスを自動的に選択します。この機能はデフォルトで有効になっています。 GPUデバイスを手動で選択する場合は、 run_[run_model].pyの--device argsを除外して、コマンド付きのGPUデバイスを指定してください。
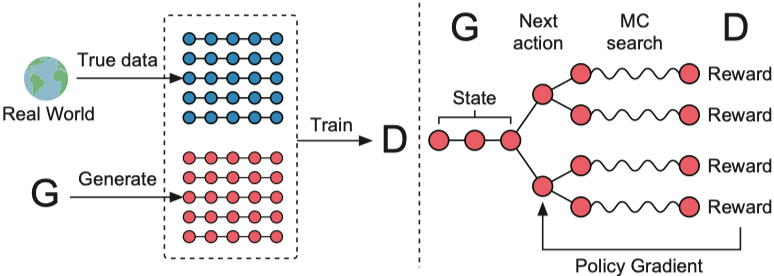
ファイルを実行:run_seqgan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
構造(seqganから)
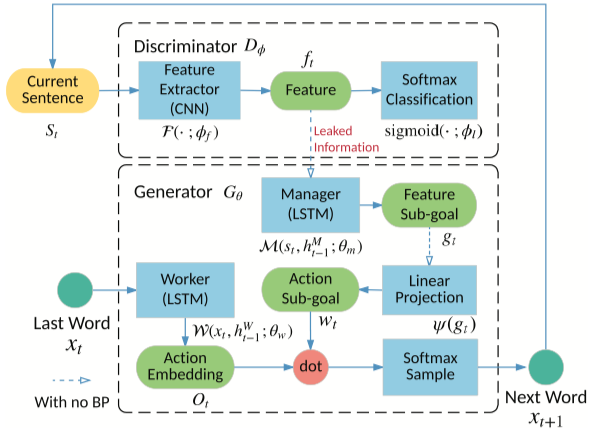
実行ファイル:run_leakgan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
構造(Leakganから)
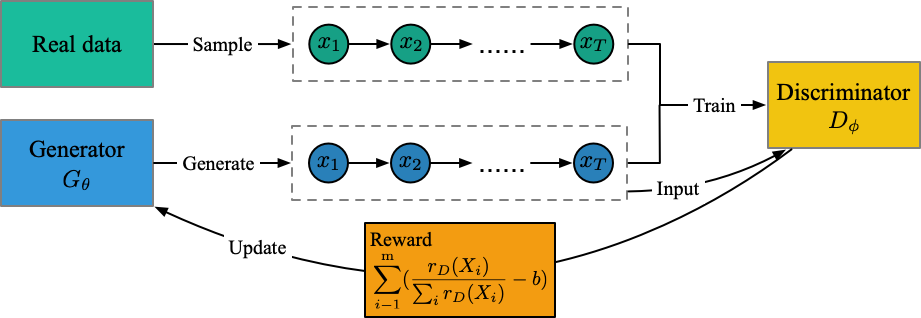
実行ファイル:run_maligan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
構造(私の理解から)
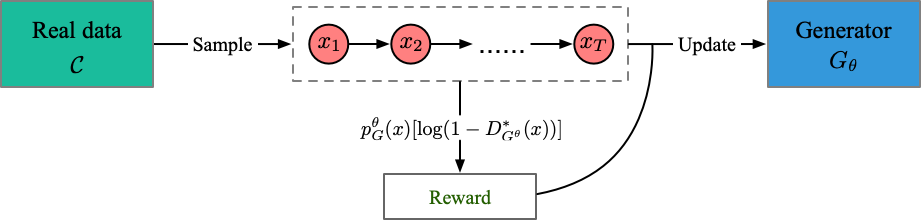
ファイルを実行:run_jsdgan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター(識別子なし)
構造(私の理解から)
ファイルを実行:run_relgan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
構造(私の理解から)
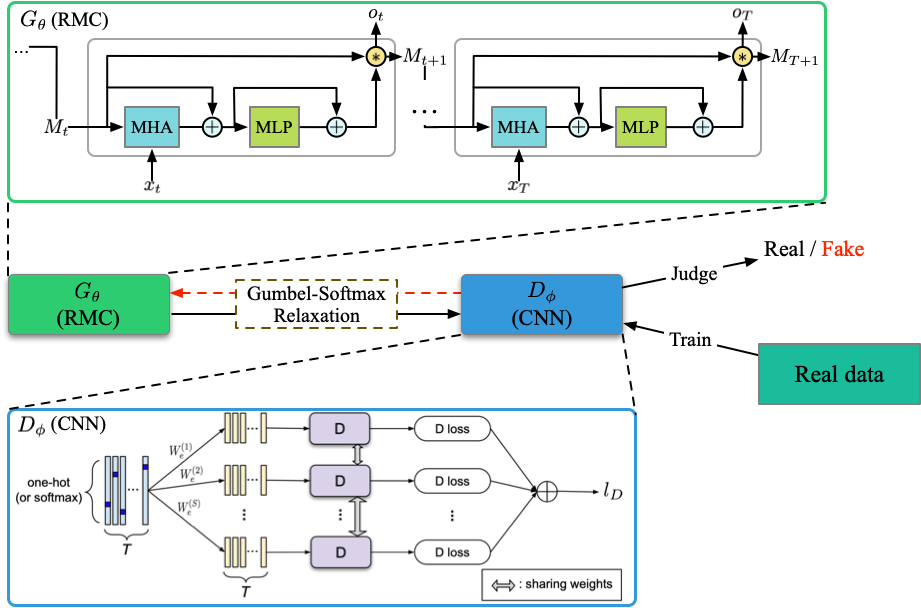
実行ファイル:run_dpgan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
構造(DPGANから)
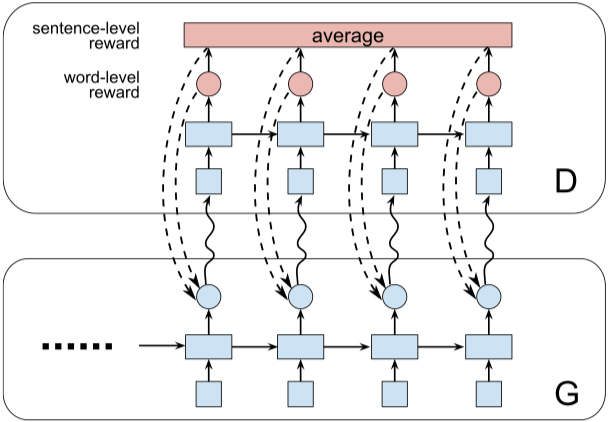
実行ファイル:run_dgsan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
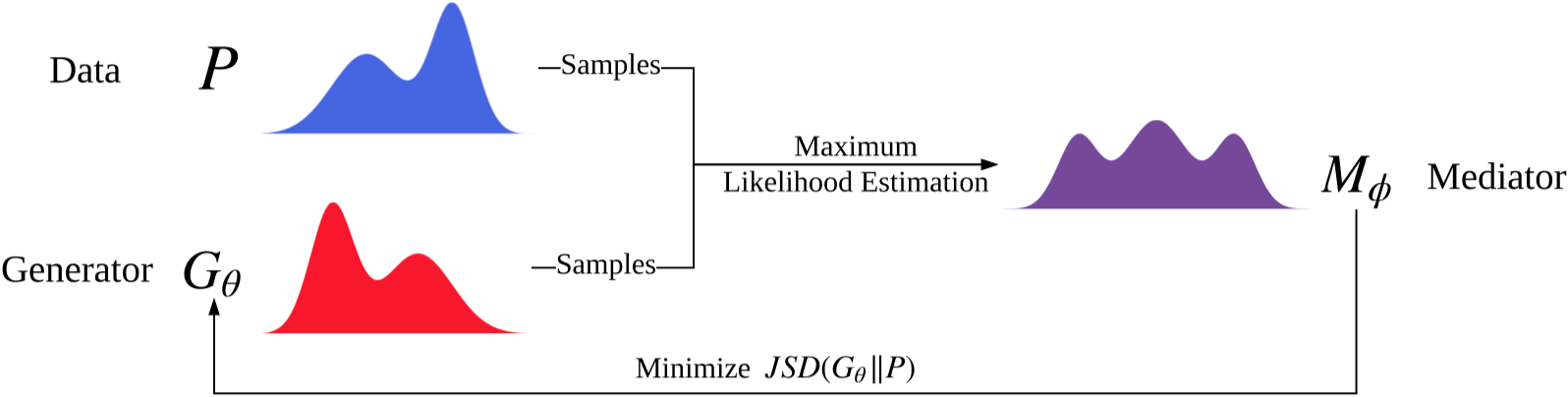
実行ファイル:run_cot.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
構造(ベッドから)
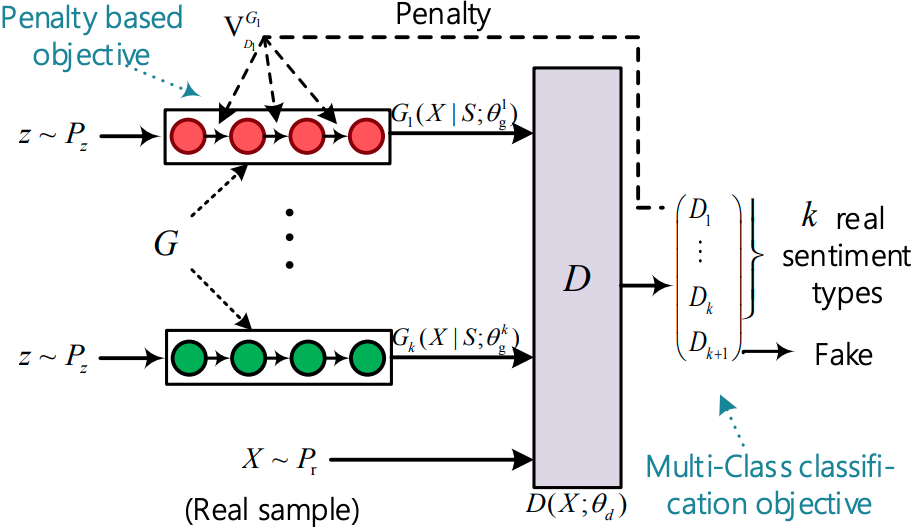
ファイルを実行:run_sentigan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
構造(センティガンから)
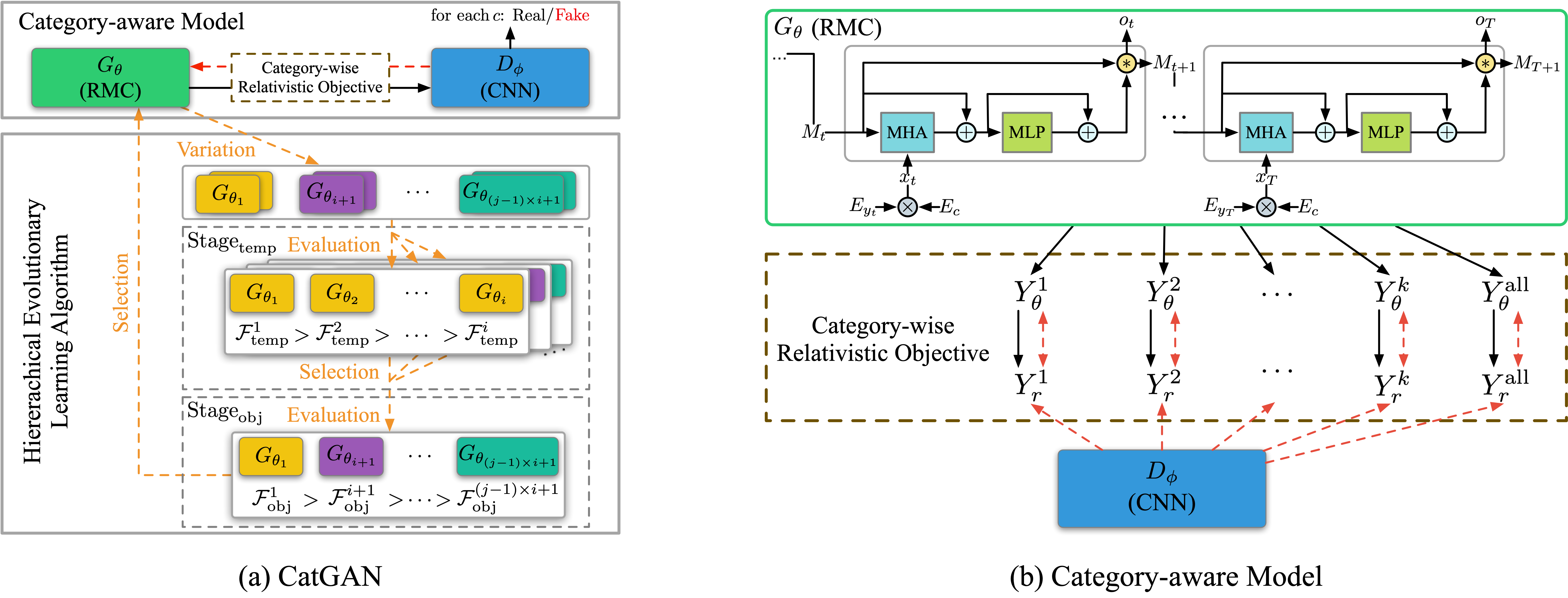
ファイルを実行:run_catgan.py
インストラクター:oracle_data、real_data
モデル:ジェネレーター、識別器
構造(キャットガンから)
MIT LINCENSE


