OpenDelta
v0.3.2
매개 변수 효율적인 튜닝을위한 오픈 소스 프레임 워크 (델타 튜닝).
개요 • 설치 • 기본 사용 • 문서 • 성능 •
OpenDelta는 매개 변수 효율적인 튜닝 방법 ( 델타 튜닝 으로 더빙)을위한 툴킷으로, 사용자는 대부분의 매개 변수를 동결 상태로 유지하면서 업데이트 할 소량 매개 변수를 유연하게 지정 (또는 추가) 할 수 있습니다. Opendelta를 사용하면 사용자는 접두사 조정, 어댑터, LORA 또는 기타 유형의 델타 튜닝을 선호하는 PTM으로 쉽게 구현할 수 있습니다.
Opendelta의 최신 버전은 Python == 3.8.13, pytorch == 1.12.1, Transformers == 4.22.2에서 테스트됩니다. 다른 버전도 지원 될 것입니다. 자신의 패키지 버전을 사용할 때 버그가 발생하면 문제를 제기하십시오. 가능한 한 빨리 살펴 보겠습니다.
Opendelta를 사용하여 PLM (예 : 바트)을 수정하는 데모. 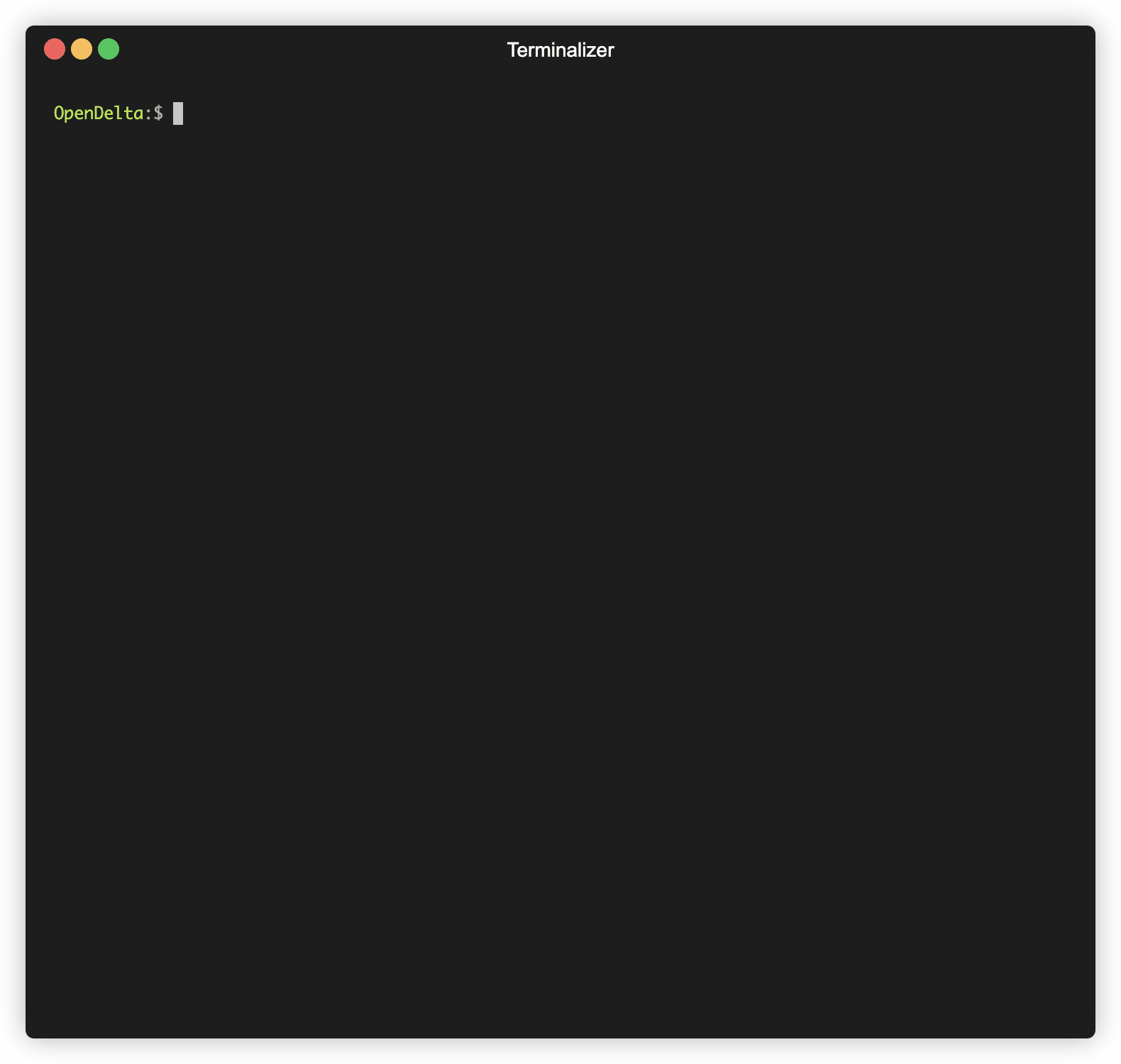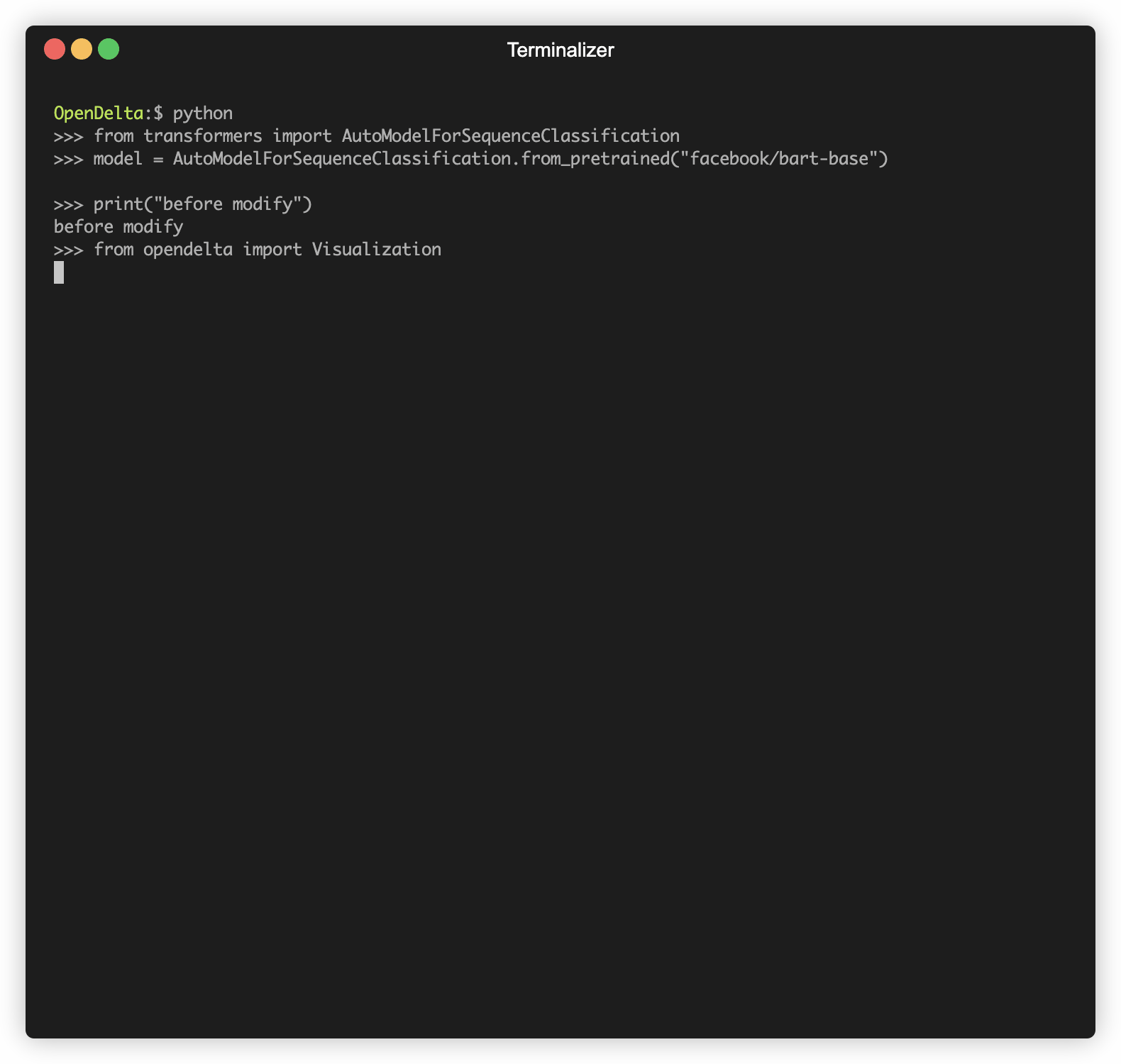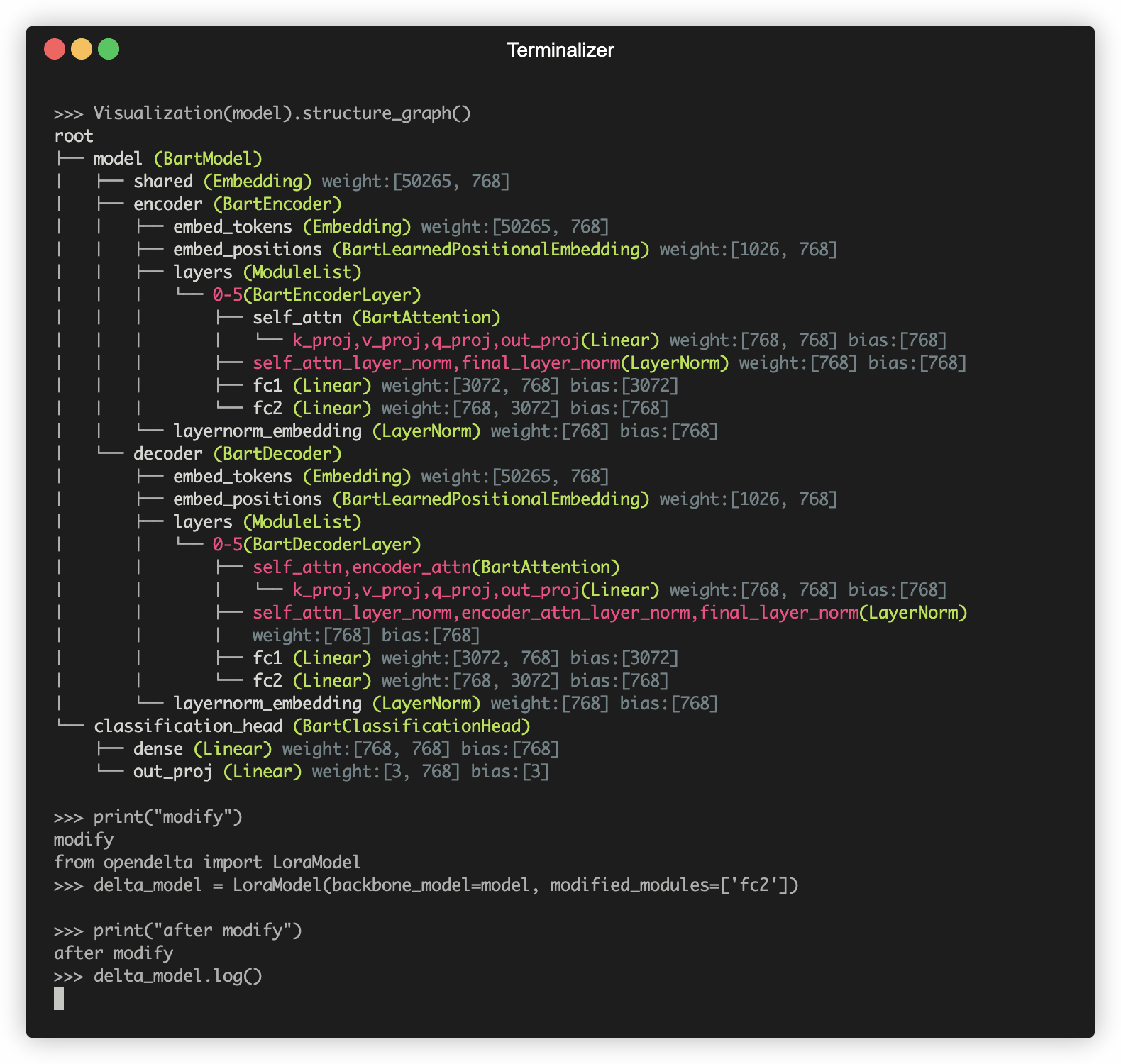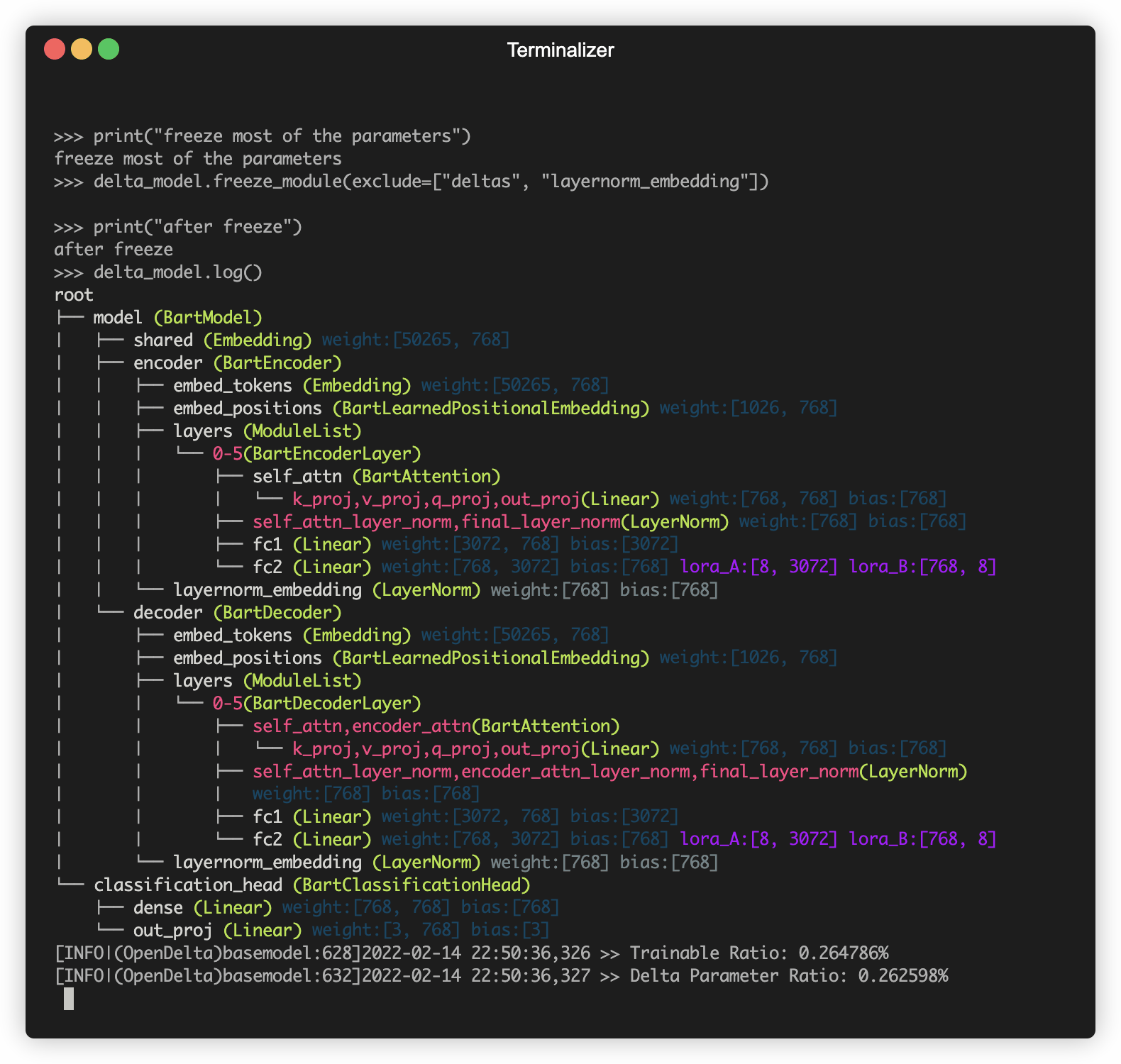
conda create -n opendelta_env python=3.8
conda activate opendelta_envpip install git+https://github.com/thunlp/OpenDelta.git또는 최신 PIP 버전 설치 (더 안정)
pip install opendelta또는 소스에서 빌드하십시오
git clone [email protected]:thunlp/OpenDelta.git
cd OpenDelta
python setup.py install
# python setup.py develop # if you want to do some modifications on the code for your research:
다음 코드와 의견은 Opendelta의 주요 기능을 안내합니다. Colab의 Must_try.py 및 Must_try.ipynb에도 있습니다.
# use transformers as usual.
from transformers import AutoModelForSeq2SeqLM , AutoTokenizer
t5 = AutoModelForSeq2SeqLM . from_pretrained ( "t5-large" )
t5_tokenizer = AutoTokenizer . from_pretrained ( "t5-large" )
# A running example
inputs_ids = t5_tokenizer . encode ( "Is Harry Potter written by J.K. Rowling" , return_tensors = "pt" )
t5_tokenizer . decode ( t5 . generate ( inputs_ids )[ 0 ])
# >>> '<pad><extra_id_0>? Is it Harry Potter?</s>'
# use existing delta models
from opendelta import AutoDeltaModel , AutoDeltaConfig
# use existing delta models from DeltaCenter
delta = AutoDeltaModel . from_finetuned ( "thunlp/Spelling_Correction_T5_LRAdapter_demo" , backbone_model = t5 )
# freeze the whole backbone model except the delta models.
delta . freeze_module ()
# visualize the change
delta . log ()
t5_tokenizer . decode ( t5 . generate ( inputs_ids )[ 0 ])
# >>> <pad> Is Harry Potter written by J.K. Rowling?</s>
# Now save merely the delta models, not the whole backbone model, to tmp/
delta . save_finetuned ( ".tmp" )
import os ; os . listdir ( ".tmp" )
# >>> The state dict size is 1.443 MB
# >>> We encourage users to push their final and public models to delta center to share them with the community!
# reload the model from local url and add it to pre-trained T5.
t5 = AutoModelForSeq2SeqLM . from_pretrained ( "t5-large" )
delta1 = AutoDeltaModel . from_finetuned ( ".tmp" , backbone_model = t5 )
import shutil ; shutil . rmtree ( ".tmp" ) # don't forget to remove the tmp files.
t5_tokenizer . decode ( t5 . generate ( inputs_ids )[ 0 ])
# >>> <pad> Is Harry Potter written by J.K. Rowling?</s>
# detach the delta models, the model returns to the unmodified status.
delta1 . detach ()
t5_tokenizer . decode ( t5 . generate ( inputs_ids )[ 0 ])
# >>> '<pad><extra_id_0>? Is it Harry Potter?</s>'
# use default configuration for customized wrapped models which have PLMs inside. This is a common need for users.
import torch . nn as nn
class WrappedModel ( nn . Module ):
def __init__ ( self , inner_model ):
super (). __init__ ()
self . inner = inner_model
def forward ( self , * args , ** kwargs ):
return self . inner ( * args , ** kwargs )
wrapped_model = WrappedModel ( WrappedModel ( t5 ))
# say we use LoRA
delta_config = AutoDeltaConfig . from_dict ({ "delta_type" : "lora" })
delta2 = AutoDeltaModel . from_config ( delta_config , backbone_model = wrapped_model )
delta2 . log ()
# >>> root
# -- inner
# -- inner
# ...
# ... lora_A:[8,1024], lora_B:[1024,8]
delta2 . detach ()
# use a not default configuration
# say we add lora to the last four layer of the decoder of t5, with lora rank=5
delta_config3 = AutoDeltaConfig . from_dict ({ "delta_type" : "lora" , "modified_modules" :[ "[r]decoder.*((20)|(21)|(22)|(23)).*DenseReluDense.wi" ], "lora_r" : 5 })
delta3 = AutoDeltaModel . from_config ( delta_config3 , backbone_model = wrapped_model )
delta3 . log ()Pytorch를 기반으로 한 백본 모델에서 Opendelta를 사용하려고 시도 할 수 있습니다.
그러나 백본 모델의 서브 모듈의 인터페이스가 지원되지 않을 가능성이 적습니다. 따라서 Opendelta가 지원할 수있는 일반적으로 사용되는 일부 모델을 확인했습니다.
우리는 점점 더 많은 새로운 모델을 계속 테스트 할 것입니다.
자신의 백본 모델에 Opendelta를 성공적으로 적용하면 풀 요청이 환영됩니다.
@article { hu2023opendelta ,
title = { OpenDelta: A Plug-and-play Library for Parameter-efficient Adaptation of Pre-trained Models } ,
author = { Hu, Shengding and Ding, Ning and Zhao, Weilin and Lv, Xingtai and Zhang, Zhen and Liu, Zhiyuan and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2307.03084 } ,
year = { 2023 }
} @article { ding2022delta ,
title = { Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models } ,
author = { Ding, Ning and Qin, Yujia and Yang, Guang and Wei, Fuchao and Yang, Zonghan and Su, Yusheng and Hu, Shengding and Chen, Yulin and Chan, Chi-Min and Chen, Weize and others } ,
journal = { arXiv preprint arXiv:2203.06904 } ,
year = { 2022 }
}

