OpenDelta
v0.3.2
Un marco de código abierto para la sintonización con eficiencia de parámetros (ajuste delta).
Descripción general • Instalación • Uso básico • Docios • Rendimiento •
Opendelta es un conjunto de herramientas para los métodos de sintonización con eficiencia de parámetros (lo llamamos como sintonización delta ), por el cual los usuarios pueden asignar (o agregar) parámetros de cantidad pequeña para actualizar mientras mantienen la mayoría de los parámetros congelados. Al usar Opendelta, los usuarios pueden implementar fácilmente el ajuste de prefijo, los adaptadores, Lora o cualquier otro tipo de ajuste delta con PTM preferidos.
La última versión de Opendelta se prueba en Python == 3.8.13, Pytorch == 1.12.1, Transformers == 4.22.2. Es probable que otras versiones también sean compatibles. Si encuentra errores cuando usa sus propias versiones de paquete, plantee un problema, lo investigaremos lo antes posible.
Una demostración de usar Opendelta para modificar el PLM (por ejemplo, BART). 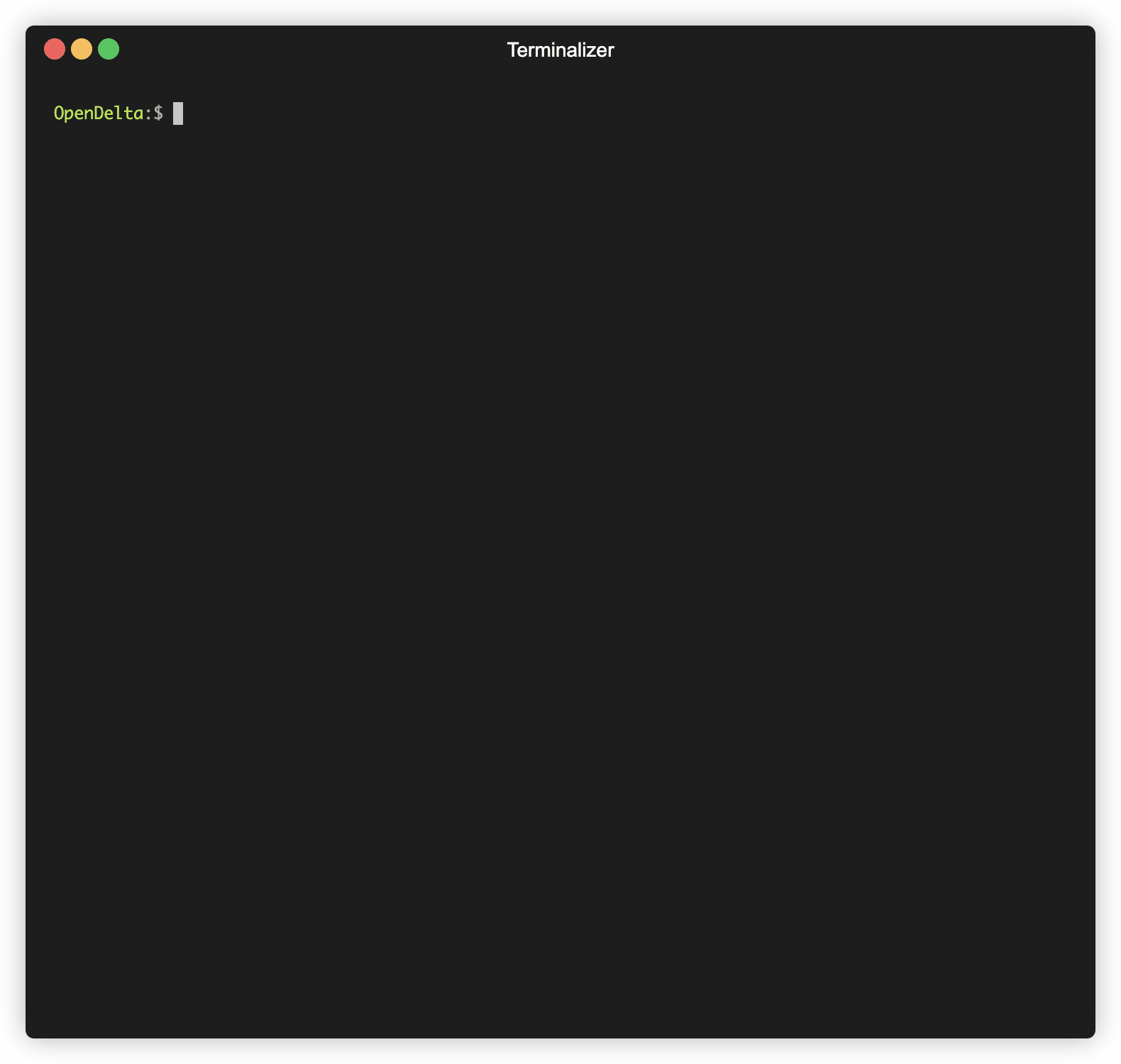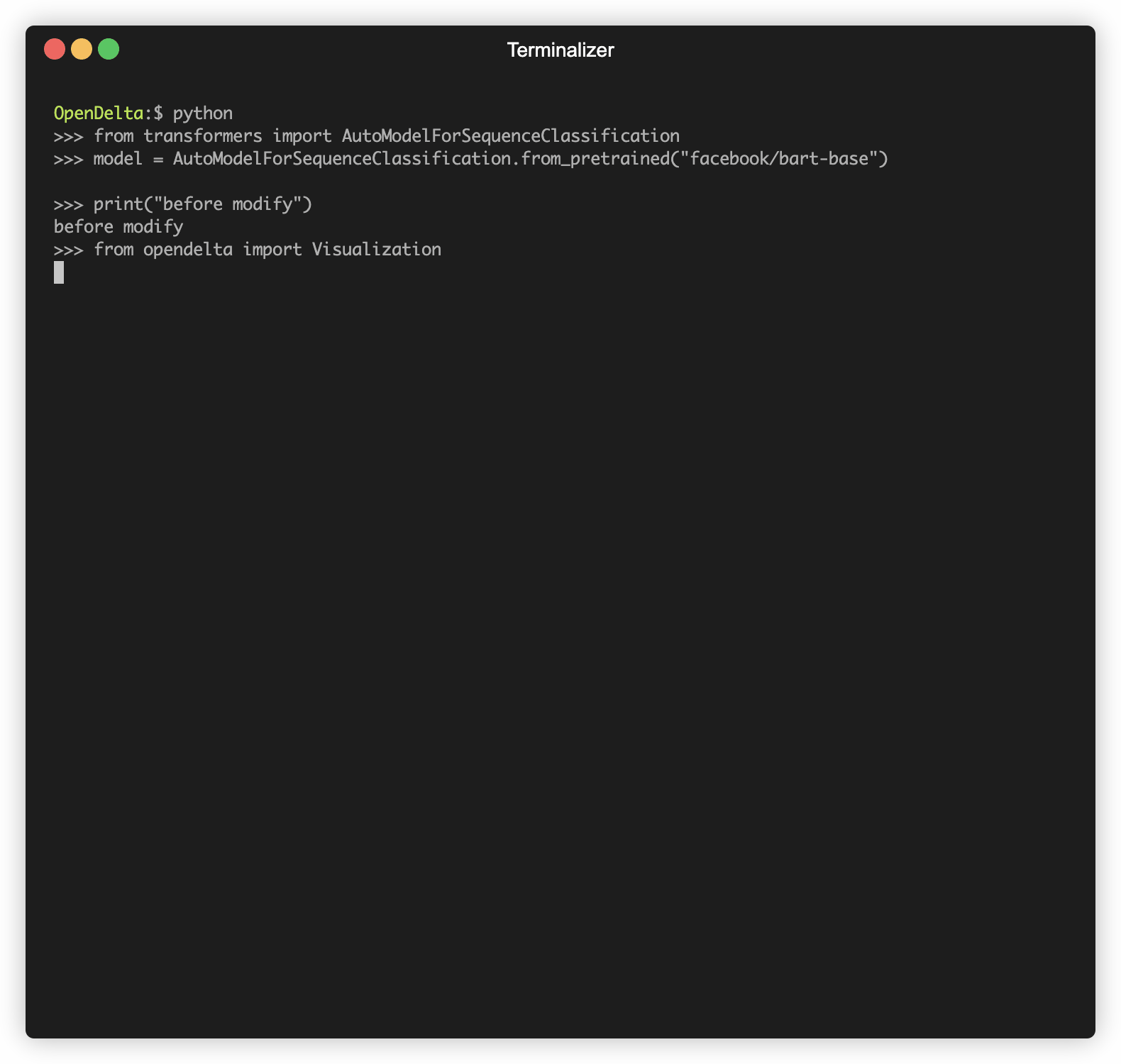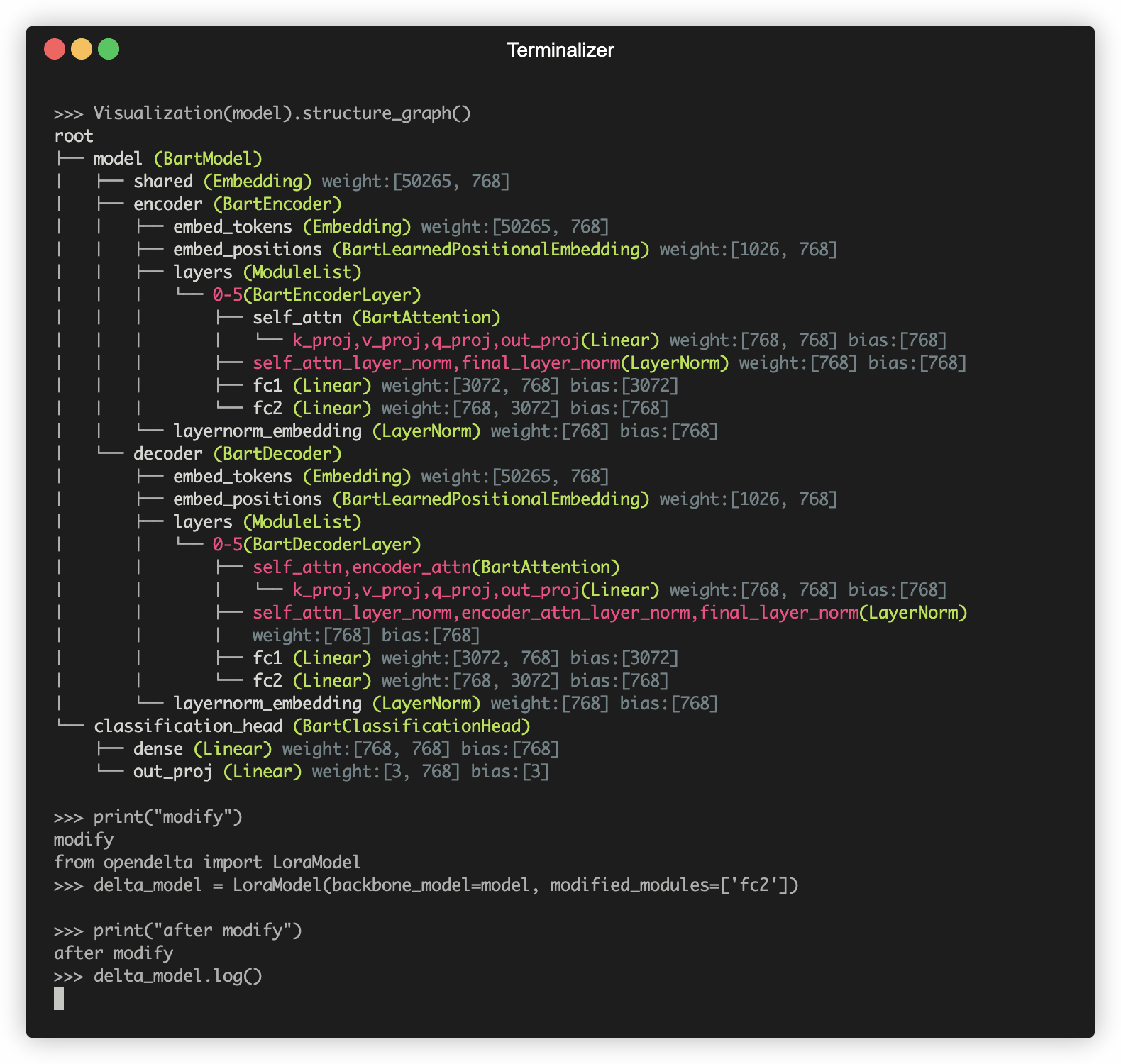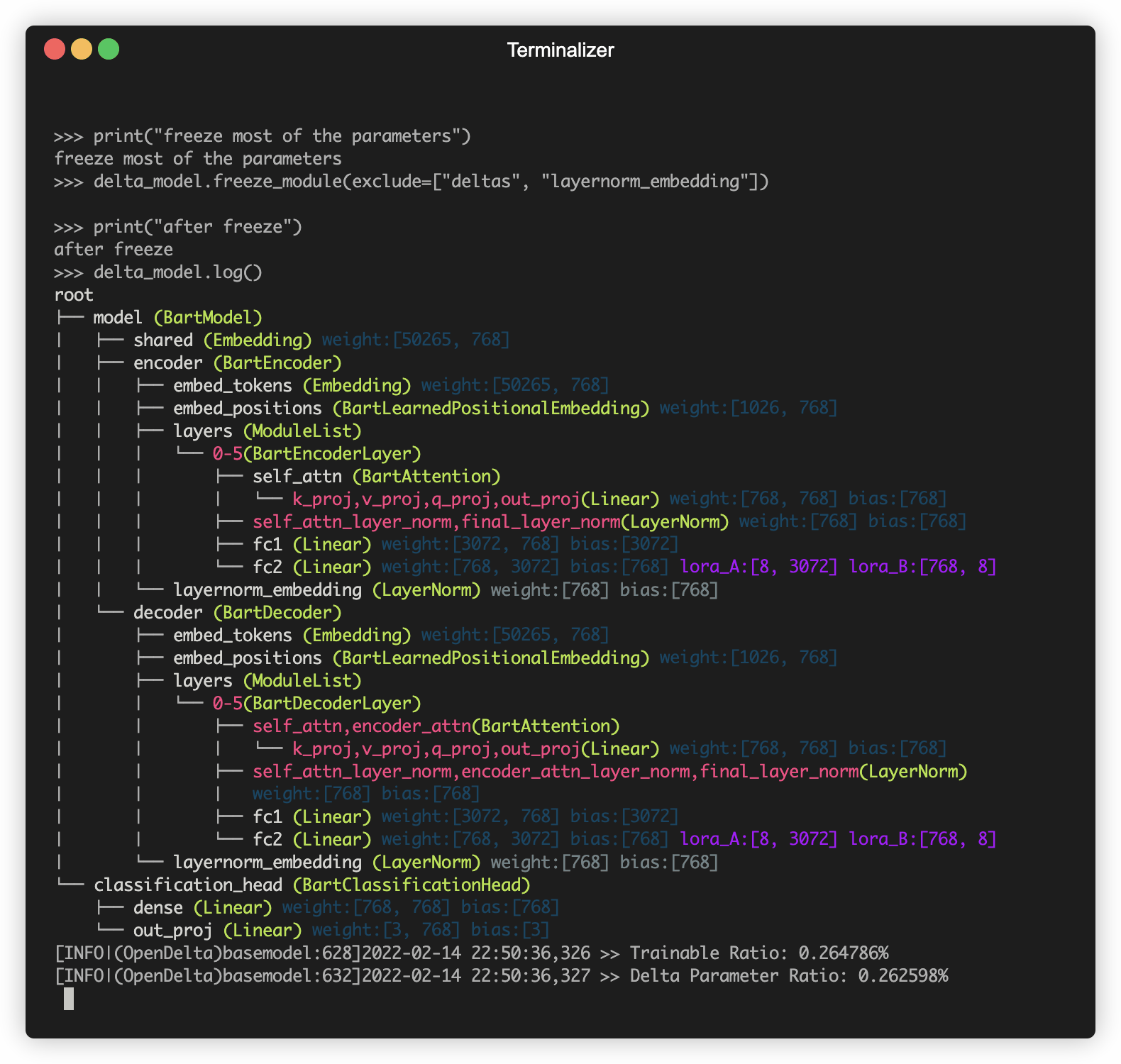
conda create -n opendelta_env python=3.8
conda activate opendelta_envpip install git+https://github.com/thunlp/OpenDelta.gito instalar la última versión de PIP (más estable)
pip install opendeltao construir desde la fuente
git clone [email protected]:thunlp/OpenDelta.git
cd OpenDelta
python setup.py install
# python setup.py develop # if you want to do some modifications on the code for your research:
Los siguientes códigos y comentarios lo guían a través de la funcionalidad clave de Opendelta. También está en must_try.py y must_try.ipynb en colab.
# use transformers as usual.
from transformers import AutoModelForSeq2SeqLM , AutoTokenizer
t5 = AutoModelForSeq2SeqLM . from_pretrained ( "t5-large" )
t5_tokenizer = AutoTokenizer . from_pretrained ( "t5-large" )
# A running example
inputs_ids = t5_tokenizer . encode ( "Is Harry Potter written by J.K. Rowling" , return_tensors = "pt" )
t5_tokenizer . decode ( t5 . generate ( inputs_ids )[ 0 ])
# >>> '<pad><extra_id_0>? Is it Harry Potter?</s>'
# use existing delta models
from opendelta import AutoDeltaModel , AutoDeltaConfig
# use existing delta models from DeltaCenter
delta = AutoDeltaModel . from_finetuned ( "thunlp/Spelling_Correction_T5_LRAdapter_demo" , backbone_model = t5 )
# freeze the whole backbone model except the delta models.
delta . freeze_module ()
# visualize the change
delta . log ()
t5_tokenizer . decode ( t5 . generate ( inputs_ids )[ 0 ])
# >>> <pad> Is Harry Potter written by J.K. Rowling?</s>
# Now save merely the delta models, not the whole backbone model, to tmp/
delta . save_finetuned ( ".tmp" )
import os ; os . listdir ( ".tmp" )
# >>> The state dict size is 1.443 MB
# >>> We encourage users to push their final and public models to delta center to share them with the community!
# reload the model from local url and add it to pre-trained T5.
t5 = AutoModelForSeq2SeqLM . from_pretrained ( "t5-large" )
delta1 = AutoDeltaModel . from_finetuned ( ".tmp" , backbone_model = t5 )
import shutil ; shutil . rmtree ( ".tmp" ) # don't forget to remove the tmp files.
t5_tokenizer . decode ( t5 . generate ( inputs_ids )[ 0 ])
# >>> <pad> Is Harry Potter written by J.K. Rowling?</s>
# detach the delta models, the model returns to the unmodified status.
delta1 . detach ()
t5_tokenizer . decode ( t5 . generate ( inputs_ids )[ 0 ])
# >>> '<pad><extra_id_0>? Is it Harry Potter?</s>'
# use default configuration for customized wrapped models which have PLMs inside. This is a common need for users.
import torch . nn as nn
class WrappedModel ( nn . Module ):
def __init__ ( self , inner_model ):
super (). __init__ ()
self . inner = inner_model
def forward ( self , * args , ** kwargs ):
return self . inner ( * args , ** kwargs )
wrapped_model = WrappedModel ( WrappedModel ( t5 ))
# say we use LoRA
delta_config = AutoDeltaConfig . from_dict ({ "delta_type" : "lora" })
delta2 = AutoDeltaModel . from_config ( delta_config , backbone_model = wrapped_model )
delta2 . log ()
# >>> root
# -- inner
# -- inner
# ...
# ... lora_A:[8,1024], lora_B:[1024,8]
delta2 . detach ()
# use a not default configuration
# say we add lora to the last four layer of the decoder of t5, with lora rank=5
delta_config3 = AutoDeltaConfig . from_dict ({ "delta_type" : "lora" , "modified_modules" :[ "[r]decoder.*((20)|(21)|(22)|(23)).*DenseReluDense.wi" ], "lora_r" : 5 })
delta3 = AutoDeltaModel . from_config ( delta_config3 , backbone_model = wrapped_model )
delta3 . log ()Puede intentar usar Opendelta en cualquier modelo de columna vertebral basado en Pytorch.
Sin embargo, con pequeñas posibilidades de que la interfaz de los submódulos del modelo de columna vertebral no sea compatible. Por lo tanto, verificamos algunos modelos de uso común que Opendelta seguramente admitirá.
Seguiremos probando más y más modelos emergentes.
Las solicitudes de extracción son bienvenidas cuando aplica con éxito Opendelta en su propio modelo de columna vertebral.
@article { hu2023opendelta ,
title = { OpenDelta: A Plug-and-play Library for Parameter-efficient Adaptation of Pre-trained Models } ,
author = { Hu, Shengding and Ding, Ning and Zhao, Weilin and Lv, Xingtai and Zhang, Zhen and Liu, Zhiyuan and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2307.03084 } ,
year = { 2023 }
} @article { ding2022delta ,
title = { Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models } ,
author = { Ding, Ning and Qin, Yujia and Yang, Guang and Wei, Fuchao and Yang, Zonghan and Su, Yusheng and Hu, Shengding and Chen, Yulin and Chan, Chi-Min and Chen, Weize and others } ,
journal = { arXiv preprint arXiv:2203.06904 } ,
year = { 2022 }
}

