tts german pytorch
1.0.0
ThorstenMüllerのThorsten – 2022.10およびThorsten-21.06-emotional Datasetsで訓練されたFastPitch(ARXIV)。
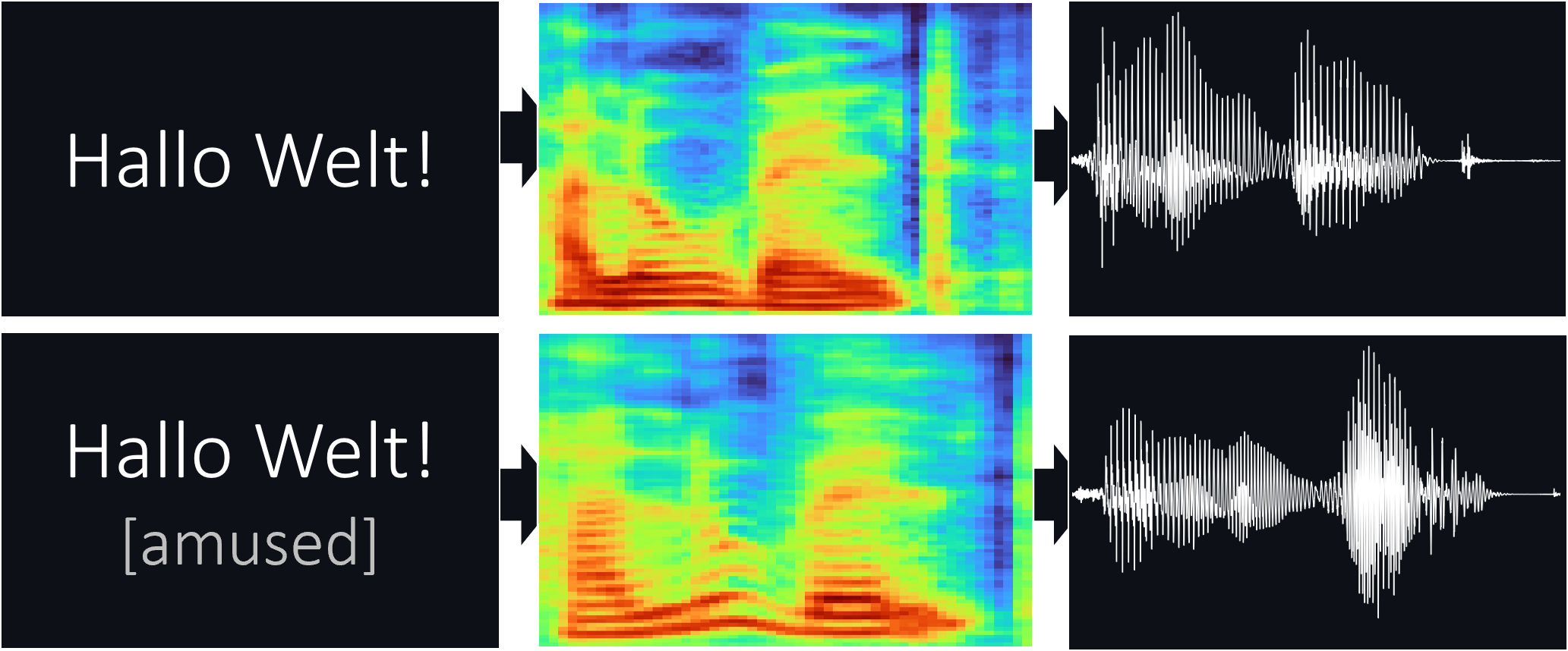
ここでいくつかのオーディオサンプルを聴くことができます。
必要なパッケージ: torch torchaudio pyyaml phonemizer
ここを参照して、 phonemizerとespeak-ngバックエンドをインストールしてください。
〜トレーニング用: librosa matplotlib tensorboard
〜デモアプリの場合: fastapi "uvicorn[standard]"
FastPitchモデルリンクの前提条件の重みをダウンロードします。
Hifi-Gan Vocoder Weights(リンク)をダウンロードします。それらをpretrained/hifigan-thor-v1に入れるか、 configs/basic.yamlの次の行を編集します。
# vocoder
vocoder_state_path : pretrained/hifigan-thor-v1/hifigan-thor.pth
vocoder_config_path : pretrained/hifigan-thor-v1/config.json models.fastpitchのFastPitchは、テキストからメルへの推論を簡素化するラッパーです。 FastPitch2Waveモデルには、直接テキストからスピーチへの推論のためのHIFI-GANボコーダーが含まれています。
from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_de.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "Hallo Welt!" ) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_de.pth' )
model = model . cuda ()
wave = model . tts ( "Hallo Welt!" )
wave_list = model . tts ([ "null" , "eins" , "zwei" , "drei" , "vier" , "fünf" ])WebアプリはFastapiライブラリを使用します。アプリを実行するには、次のパッケージが必要です。
FASTAPI:バックエンドAPIの場合| Uvicorn:アプリを提供するため
インストール: pip install fastapi "uvicorn[standard]"
実行: python app.py
プレビュー:
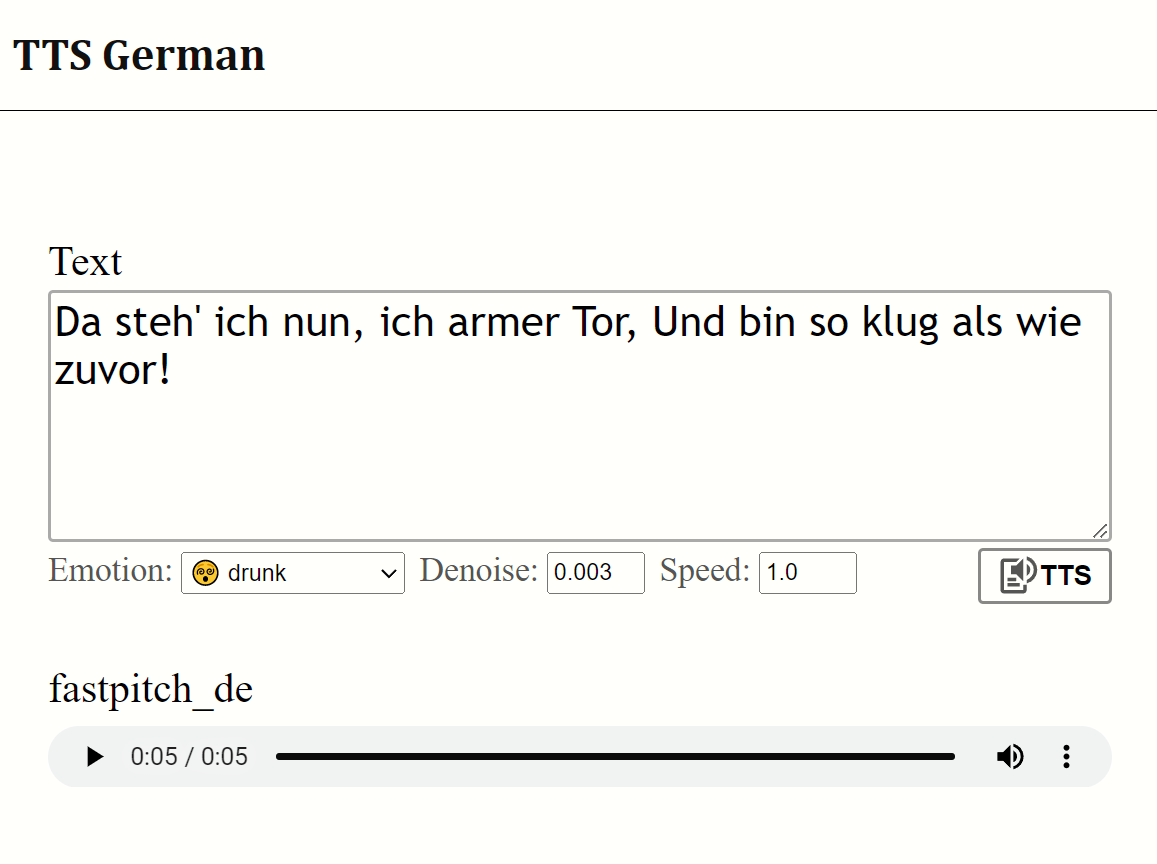
高品質のデータセットについては、ThorstenMüllerに感謝します。
FastPitchファイルは、Nvidiaのdeeplearningexamplesに由来しています


