TNN
v0.3.0
中文版本

TNN:Tencent Youtu Labによって供給された高性能で軽量のニューラルネットワーク推論フレームワークが開いています。また、クロスプラットフォーム、高性能、モデルの圧縮、コードカスタマイズなど、多くの優れた利点があります。 TNNフレームワークは、元のRapidNetおよびNCNNフレームワークに基づいて、モバイルデバイスのサポートとパフォーマンスの最適化をさらに強化します。同時に、業界の主流のオープンソースフレームワークの高性能と優れたスケーラビリティ特性を指し、X86およびNV GPUのサポートを拡大します。携帯電話では、TNNは、モバイルQQ、Weishi、Pituなどの多くのアプリケーションで使用されています。 Tencent Cloud AIの基本的な加速フレームワークとして、TNNは多くの企業の実装に加速サポートを提供しています。 TNN推論フレームワークのさらなる改善を促進するために、誰もが共同構築に参加することを歓迎します。
| 顔の検出(炎症) | 顔のアライメント (Tencent Youtu Labから) | 髪のセグメンテーション (Tencent Guangying Labから) |
|---|---|---|
モデルリンク:Tflite TNN | モデルリンク:TNN | モデルリンク:TNN |
| 推定のポーズ (TencentGuangliuから) | 推定のポーズ (blazepose) | 中国のOCR |
|---|---|---|
モデルリンク:TNN | モデルリンク:Tflite TNN | モデルリンク:onnx tnn |
| オブジェクト検出(Yolov5s) | オブジェクト検出(mobilenetv2-ssd) | 読解 |
|---|---|---|
モデルリンク:onnx tnn |  モデルリンク:Tensorflow TNN | モデルリンク:onnx tnn |
中国のOCRデモは、中国語_liteプロジェクトのTNN実装です。それは軽量で、傾斜、回転、垂直のテキスト認識をサポートします。
各デモのサポートを次の表に示します。 ✅をクリックして、各デモの入り口コードを見つけることができます。
| デモ | アーム | opencl | 金属 | Huawei npu | Apple NPU | x86 | cuda |
|---|---|---|---|---|---|---|---|
| 顔の検出(炎症) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| オブジェクト検出(Yolov5s) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 顔のアライメント | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 髪のセグメンテーション | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 推定のポーズ (TencentGuangliuから) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| ポーズ推定(ブレズポース) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 中国のOCR | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| 読解 | ✅ | ✅ |
TNNを使用するのは非常に簡単です。訓練されたモデルがある場合、モデルは3つのステップでターゲットプラットフォームに展開できます。
訓練されたモデルをTNNモデルに変換します。 Tensorflow、Pytorch、またはCaffeを使用しているかどうかにかかわらず、このステップを完了するのに役立つ豊富なツールを提供します。コンバージョンを簡単に完了できます。詳細なハンズオンチュートリアルは、TNNモデルの作成方法でご覧いただけます。
モデルの変換が終了した場合、2番目のステップは、ターゲットプラットフォームのTNNエンジンをコンパイルすることです。ハードウェアサポートに従って、ARM/OPENCL/NPU/X86/CUDAなどのさまざまな加速ソリューションから選択できます。これらのプラットフォームには、TNNがコンパイルする便利なワンクリックスクリプトを提供します。詳細な手順については、TNNのコンパイル方法を参照してください。
最後のステップは、コンパイルされたTNNエンジンを使用して推論することです。アプリケーション内でTNNにプログラムコールを行うことができます。私たちは、あなたが完了するのを助けるためのリファレンスとして、リッチで詳細なデモを提供します。
現在、TNNはさまざまな主要なビジネスで開始されており、その次の特性は広く称賛されています。
計算最適化
低精度の計算加速
メモリの最適化
TNN上の主流モデルのパフォーマンス:ベンチマークデータ
TNNアーキテクチャ図:
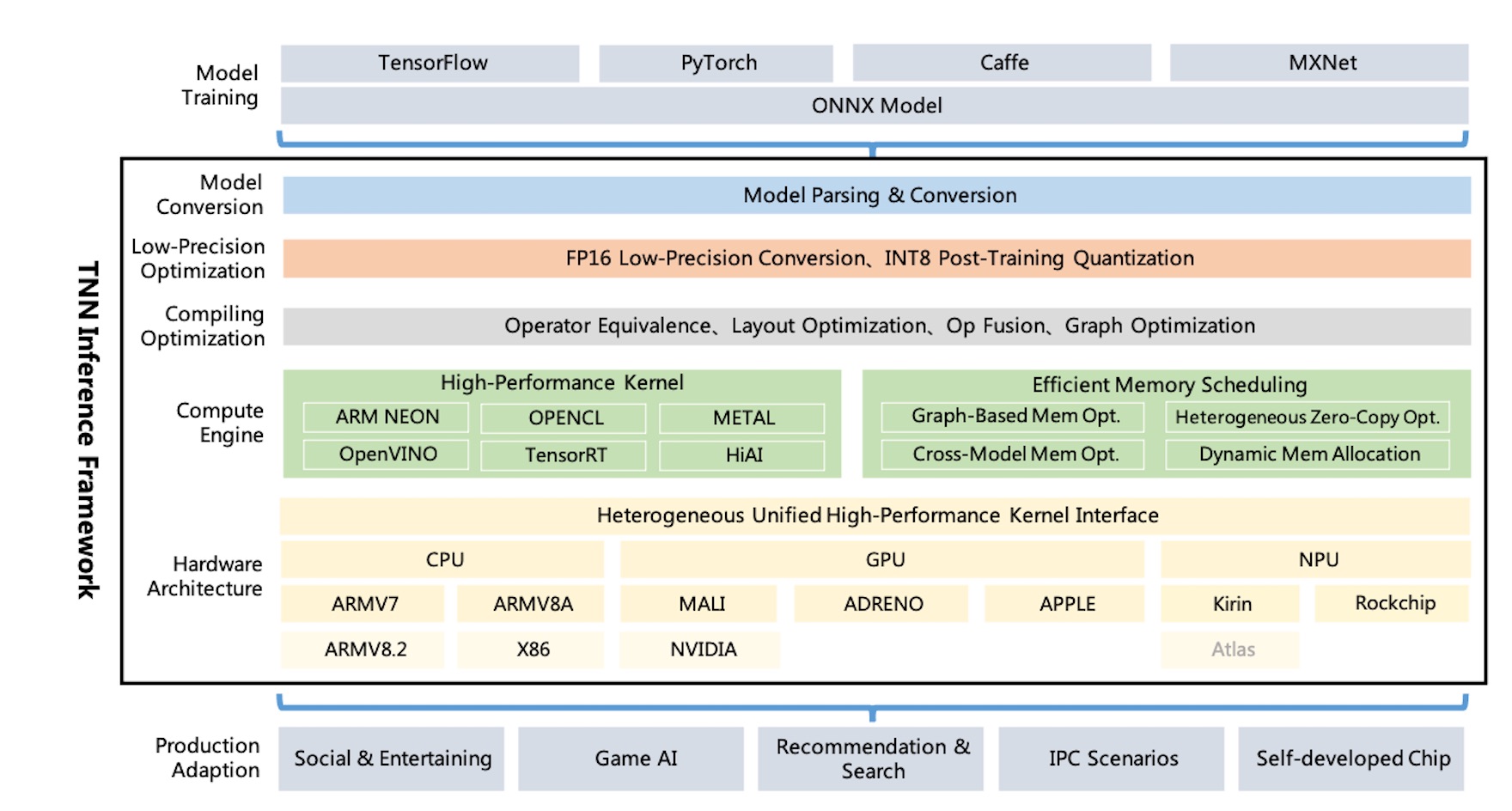
TNNは、ONNXを通じてTensorflow、Pytorch、MxNet、Caffe、およびその他のトレーニングフレームワークをサポートし、ONNXオープンソースソサエティの継続的な改善を活用しています。現在、TNNは、必要な主流のCNNのほとんどで構成される100以上のONNX演算子をサポートしています。
TNNは、主流のオペレーティングシステム(Android、iOS、埋め込みLinux、Windows、Linux)で実行され、ARM CPU、X86 GPU、NPUハードウェアプラットフォームと互換性があります。
TNNは、モデル分析、グラフ構造、グラフ最適化、低レベルのハードウェア適応、高性能カーネルなどのコンポーネントを要約および分離するモジュラー設計によって構築されます。 「ファクトリモード」を使用してデバイスを登録および構築するため、より多くのハードウェアと加速ソリューションをサポートするコストを最小限に抑えようとします。
モバイルダイナミックライブラリのサイズは約400kbであり、基本的な画像変換操作を提供します。これは軽量で便利です。 TNNは、プラットフォーム間でユニファイドモデルとインターフェイスを使用し、1つのパラメーターのみを構成することで簡単に切り替えることができます。
TNNは次のプロジェクトを参照しました:
誰もが参加して、業界で最高の推論フレームワークを構築することを歓迎します。
テクニカルディスカッションQQグループ:704900079回答:TNN
QRコードをスキャンして、TNNディスカッショングループに参加します。



