k8sgpt
v0.3.46

k8sgpt 、Kubernetesクラスターをスキャンし、診断、および単純な英語でのトリアージングの問題をスキャンするためのツールです。
SREエクスペリエンスがアナライザーに成文化されており、最も関連性の高い情報を引き出してAIで充実させるのに役立ちます。
Openai、Azure、Cohere、Amazon Bedrock、Google Gemini、Local Modelsとの統合から統合されています。
$ brew install k8sgptまたは
brew tap k8sgpt-ai/k8sgpt
brew install k8sgpt32ビット:
sudo rpm -ivh https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.46/k8sgpt_386.rpm
64ビット:
sudo rpm -ivh https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.46/k8sgpt_amd64.rpm
32ビット:
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.46/k8sgpt_386.deb
sudo dpkg -i k8sgpt_386.deb
64ビット:
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.46/k8sgpt_amd64.deb
sudo dpkg -i k8sgpt_amd64.deb
32ビット:
wget https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.46/k8sgpt_386.apk
apk add --allow-untrusted k8sgpt_386.apk
64ビット:
wget https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.46/k8sgpt_amd64.apk
apk add --allow-untrusted k8sgpt_amd64.apk
==> Installing k8sgpt from k8sgpt-ai/k8sgpt Error: The following formula cannot be installed from a bottle and must be
built from the source. k8sgpt Install Clang or run brew install gcc.
提案されているようにGCCをインストールすると、問題は持続します。したがって、ビルド必須パッケージをインストールする必要があります。
sudo apt-get update
sudo apt-get install build-essential
Kubernetesクラスター内にインストールするには、ここで入手できるインストール手順を備えたk8sgpt-operatorを使用してください
この動作モードは、クラスターの継続的な監視に最適であり、PrometheusやAlertmanagerなどの既存の監視と統合できます。
k8sgpt generateを実行してブラウザリンクを開いて生成することでこれを行うことができますk8sgpt auth addを実行して、k8sgptに設定します。--passwordフラグを使用して、パスワードを直接提供できます。k8sgpt filtersを実行して、アナライザーが使用するアクティブフィルターを管理します。デフォルトでは、分析中にすべてのフィルターが実行されます。k8sgpt analyzeを実行して、スキャンを実行します。k8sgpt analyze --explainを使用して、問題のより詳細な説明を取得します。k8sgpt analyze --with-doc (説明フラグの有無にかかわらず)を実行して、Kubernetesから公式のドキュメントを取得します。 K8SGPTは、アナライザーを使用してトリアージとクラスターの問題を診断します。組み込まれたアナライザーのセットがありますが、独自のアナライザーを書くことができます。
デフォルトのアナライザーでスキャンを実行します
k8sgpt generate
k8sgpt auth add
k8sgpt analyze --explain
k8sgpt analyze --explain --with-doc
リソースでフィルタリングします
k8sgpt analyze --explain --filter=Service
名前空間でフィルター
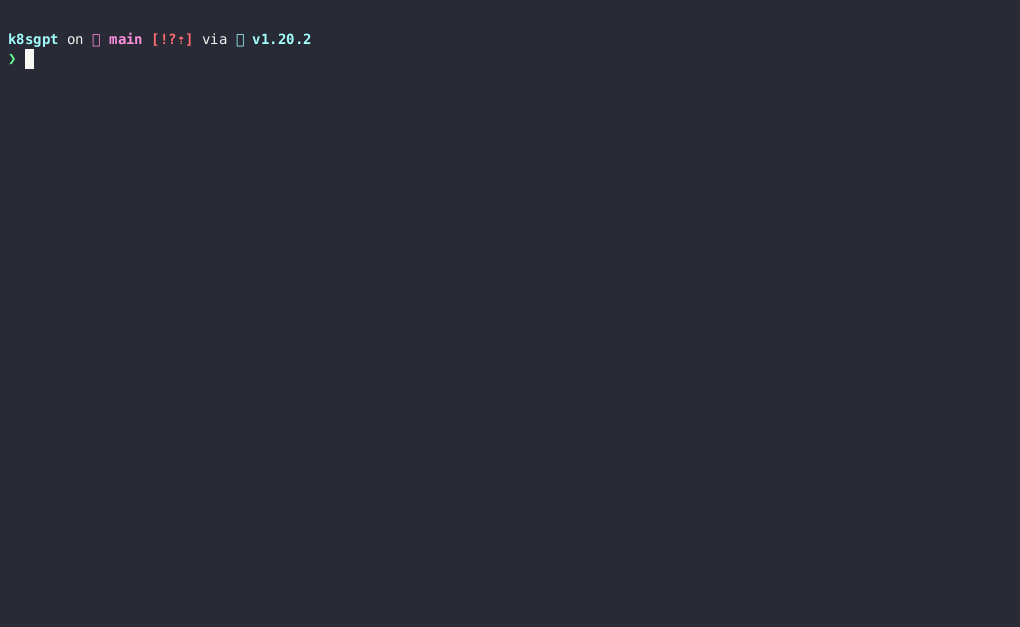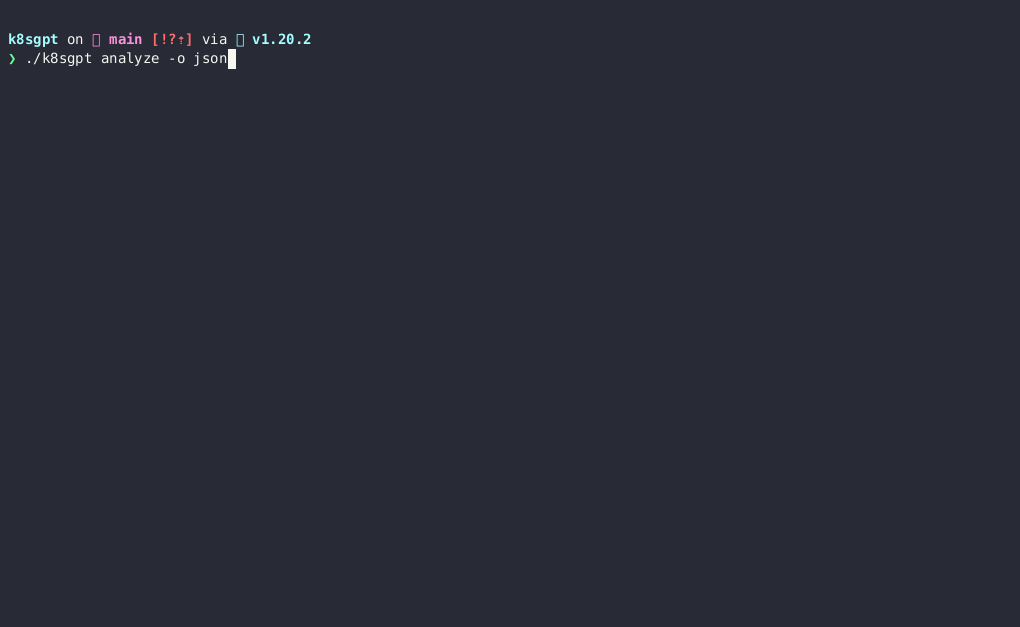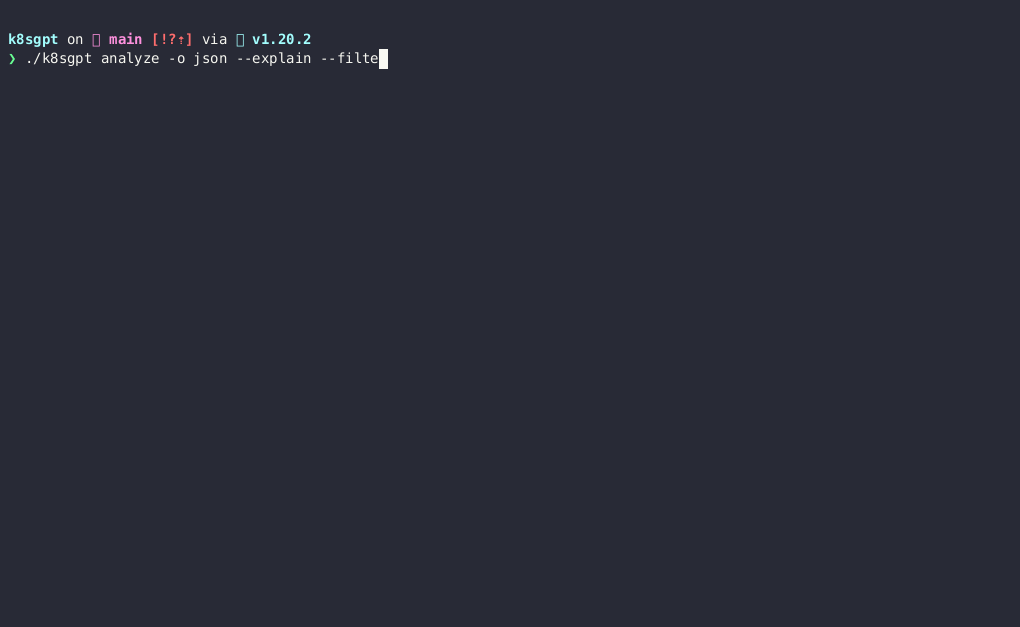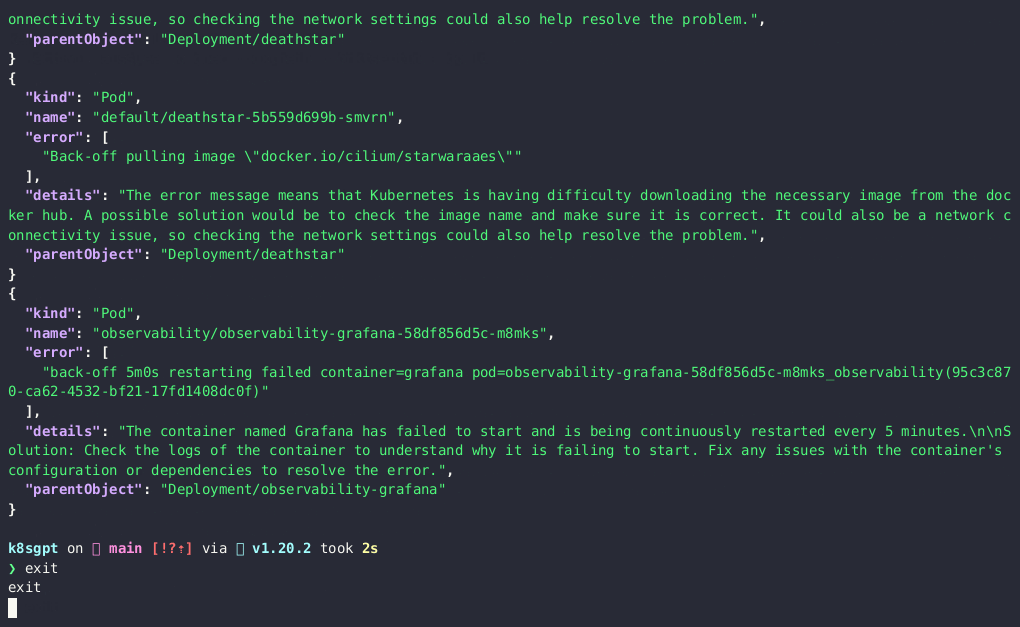
k8sgpt analyze --explain --filter=Pod --namespace=default
JSONへの出力
k8sgpt analyze --explain --filter=Service --output=json
説明中に匿名化します
k8sgpt analyze --explain --filter=Service --output=json --anonymize
フィルターをリストします
k8sgpt filters list
デフォルトのフィルターを追加します
k8sgpt filters add [filter(s)]
k8sgpt filters add Servicek8sgpt filters add Ingress,Podデフォルトフィルターを削除します
k8sgpt filters remove [filter(s)]
k8sgpt filters remove Servicek8sgpt filters remove Ingress,Pod構成されたバックエンドをリストします
k8sgpt auth list
構成されたバックエンドを更新します
k8sgpt auth update $MY_BACKEND1,$MY_BACKEND2..
構成されたバックエンドを削除します
k8sgpt auth remove -b $MY_BACKEND1,$MY_BACKEND2..
統合をリストします
k8sgpt integrations list
統合をアクティブにします
k8sgpt integrations activate [integration(s)]
統合を使用します
k8sgpt analyze --filter=[integration(s)]
統合を無効にします
k8sgpt integrations deactivate [integration(s)]
サーブモード
k8sgpt serve
サーブモードの分析
grpcurl -plaintext -d '{"namespace": "k8sgpt", "explain" : "true"}' localhost:8080 schema.v1.ServerAnalyzerService/Analyze
{
"status": "OK"
}
カスタムヘッダーによる分析
k8sgpt analyze --explain --custom-headers CustomHeaderKey:CustomHeaderValue
印刷分析統計
k8sgpt analyze -s
The stats mode allows for debugging and understanding the time taken by an analysis by displaying the statistics of each analyzer.
- Analyzer Ingress took 47.125583ms
- Analyzer PersistentVolumeClaim took 53.009167ms
- Analyzer CronJob took 57.517792ms
- Analyzer Deployment took 156.6205ms
- Analyzer Node took 160.109833ms
- Analyzer ReplicaSet took 245.938333ms
- Analyzer StatefulSet took 448.0455ms
- Analyzer Pod took 5.662594708s
- Analyzer Service took 38.583359166s
診断情報
診断情報を収集するには、次のコマンドを使用して、ローカルディレクトリにdump_<timestamp>_jsonを作成します。
k8sgpt dump
K8SGPTはk8sgpt analyze --explain選択したLLM、生成AIプロバイダーを使用します。 --backendフラグを使用して、構成されたプロバイダーを指定できます(デフォルトではopenaiです)。
k8sgpt auth listを使用して、利用可能なプロバイダーをリストできます。
Default:
> openai
Active:
Unused:
> openai
> localai
> ollama
> azureopenai
> cohere
> amazonbedrock
> amazonsagemaker
> google
> huggingface
> noopai
> googlevertexai
> ibmwatsonxai
各プロバイダーの構成と使用方法に関する詳細なドキュメントについては、こちらをご覧ください。
新しいデフォルトプロバイダーを設定します
k8sgpt auth default -p azureopenai
Default provider set to azureopenai
このオプションを使用すると、AIバックエンドに送信される前にデータが匿名化されます。分析の実行中、 k8sgpt機密データ(Kubernetesオブジェクト名、ラベルなど)を取得します。このデータは、AIバックエンドに送信されたときにマスクされ、ソリューションがユーザーに返されたときにデータを解除するために使用できるキーに置き換えられます。
Error: HorizontalPodAutoscaler uses StatefulSet/fake-deployment as ScaleTargetRef which does not exist.Error: HorizontalPodAutoscaler uses StatefulSet/tGLcCRcHa1Ce5Rs as ScaleTargetRef which does not exist.The Kubernetes system is trying to scale a StatefulSet named tGLcCRcHa1Ce5Rs using the HorizontalPodAutoscaler, but it cannot find the StatefulSet. The solution is to verify that the StatefulSet name is spelled correctly and exists in the same namespace as the HorizontalPodAutoscaler.The Kubernetes system is trying to scale a StatefulSet named fake-deployment using the HorizontalPodAutoscaler, but it cannot find the StatefulSet. The solution is to verify that the StatefulSet name is spelled correctly and exists in the same namespace as the HorizontalPodAutoscaler.注:匿名化は現在、イベントには適用されません。
匿名化は現在、イベントには適用されません。
PODのようないくつかのアナライザーでは、事前に不明なイベントメッセージをAIバックエンドにフィードします。したがって、当面はそれらを隠していません。
以下は、データがマスクされているアナライザーのリストです。
以下は、データがマスクされていないアナライザーのリストです。
*注記:
K8GPTは、イベントアナライザー以外の識別情報を送信しないため、上記のアナライザーをマスクしません。
イベントアナライザーのマスキングは、この問題に見られるように、近い将来にスケジュールされます。パターンを理解し、ポッド名、名前空間などのイベントの敏感な部分をマスクできるように、さらなる研究を行う必要があります。
以下は、マスクされていないフィールドのリストです。
*注記:
k8sgpt $XDG_CONFIG_HOME/k8sgpt/k8sgpt.yamlファイルに設定データを保存します。データは、OpenAIキーを含むプレーンテキストに保存されます。
構成ファイルの場所:
| OS | パス |
|---|---|
| macos | 〜/library/application support/k8sgpt/k8sgpt.yaml |
| Linux | 〜/.config/k8sgpt/k8sgpt.yaml |
| Windows | %LocalAppData%/K8SGPT/K8SGPT.YAML |
リモートキャッシュの追加
AWS_ACCESS_KEY_IDおよびAWS_SECRET_ACCESS_KEY環境変数として必要です。k8sgpt cache add s3 --region <aws region> --bucket <name>k8sgpt cache add s3 --bucket <name> --endpoint <http://localhost:9000>k8sgpt cache add s3 --bucket <name> --endpoint <https://localhost:9000> --insecurek8sgpt cache add azure --storageacc <storage account name> --container <container name>GOOGLE_APPLICATION_CREDENTIALS環境変数として必要です。k8sgpt cache add gcs --region <gcp region> --bucket <name> --projectid <project id>キャッシュアイテムのリスト
k8sgpt cache list
キャッシュからオブジェクトをパージする注:このコマンドを使用してオブジェクトをパージすると、上流ファイルが削除されるため、適切なアクセス許可が必要です。
k8sgpt cache purge $OBJECT_NAME
リモートキャッシュの削除注:これにより、上流のS3バケットまたはAzureストレージコンテナが削除されません
k8sgpt cache remove
選択した言語で独自のアナライザーを書きたいシナリオがあるかもしれません。 K8SGPTは、スキーマを守り、消費のためにアナライザーに提供することにより、そうする能力をサポートしています。これを行うには、K8SGPT構成内のアナライザーを定義すると、スキャンプロセスに追加されます。これに加えて、分析で次のフラグを有効にする必要があります。
k8sgpt analyze --custom-analysis
これがlocalhost:8080で実行されるときの錆のローカルホストアナライザーの例を示します。
custom_analyzers:
- name: host-analyzer
connection:
url: localhost
port: 8080
これにより、Hostos情報(この分析装置の例から)を通過してK8SGPTを通過して、通常の分析でコンテキストとして使用できるようになります。
カスタムアナライザーの書き方に関するドキュメントを参照してください
カスタムアナライザーのリスト構成
k8sgpt custom-analyzer list
インストールせずにカスタムアナライザーを追加します
k8sgpt custom-analyzer add --name my-custom-analyzer --port 8085
カスタムアナライザーの削除
k8sgpt custom-analyzer remove --names "my-custom-analyzer,my-custom-analyzer-2"
ここで公式ドキュメントをご覧ください
寄稿ガイドをお読みください。
Slackで私たちを見つけてください


