DeepLearning MuLi Notes
1.0.0
Projet Motivation / Cours Introduction / Ressources de cours / Catalogue du manuel / Notes / Dossier Description / Organisateur / Contributeur
"Hand-on Learning Deep Learning" est une série de vidéos d'apprentissage en profondeur enseignées par M. Li Mu (un scientifique en chef principal chez AWS, Ph.D., Département d'informatique, Carnegie Mellon University, USA). Ce projet recueille des notes détaillées et des codes de jupyter connexes lors de notre processus d'apprentissage des vacances d'hiver "apprentissage de la main en profondeur". Donner à quelqu'un une rose quittera un parfum sur vos mains. Nous opensons toutes les notes de marque . Nous espérons que, tout en apprenant par nous-mêmes, il sera également utile pour tout le monde d'apprendre et de maîtriser "l'apprentissage à la main sur l'apprentissage du Deep Leear apprentissage".
Caractéristiques de ce projet:
- Les notes de Markdown correspondent à la vidéo de cours originale une par une, ce qui peut aider tout le monde à comprendre tout en écoutant la classe.
- Les codes de Jupyter ont détaillé des annotations chinoises pour aider tout le monde à se lancer plus rapidement.
Il y a 73 vidéos de cours au total , et la durée moyenne d'une seule vidéo ne dépasse pas 30 minutes . Il est prévu que l'étude puisse être terminée dans les 40 jours suivant les vacances d'hiver .
Le badge utilisé dans ce projet provient d'Internet. S'il porte atteinte à votre image de copyright, veuillez nous contacter pour le supprimer. Merci.
Habituellement, lorsque nous mentionnons l'apprentissage en profondeur, nous oublions souvent que l'apprentissage en profondeur n'est qu'une petite partie de l'apprentissage automatique, et pensons qu'il s'agit d'un module distinct indépendant de l'apprentissage automatique. En effet, l'apprentissage automatique, en tant que discipline avec une histoire plus longue, avait un éventail étroit d'applications dans le monde réel avant la publication de l'apprentissage en profondeur. Dans les domaines de la reconnaissance vocale, de la vision par ordinateur, du traitement du langage naturel, etc., l'apprentissage automatique n'est souvent qu'une petite partie des solutions pour résoudre ces problèmes de domaine en raison de la grande quantité de connaissances du domaine requises et la réalité est extrêmement complexe. Mais au cours des dernières années, l'avènement et l'application de l'apprentissage en profondeur ont apporté des surprises au monde, favorisant le développement rapide de la vision informatique, le traitement du langage naturel, la reconnaissance automatique de la parole, l'apprentissage du renforcement et la modélisation statistique, et menant progressivement la tendance, déclenchant une vague de révolution de l'intelligence artificielle dans le monde.
Dans le cours "Apprentissage en profondeur" , il n'y a pas seulement une petite quantité de connaissances de base de l'apprentissage automatique, telles que les réseaux de neurones linéaires, les machines de perception multicouches , etc.; Il existe également divers modèles d'apprentissage en profondeur qui sont actuellement utilisés dans les applications de pointe: y compris LENET, RESNET, LSTM, Bert ... en même temps, l'explication de chaque chapitre est également équipée de code, de manuels, etc. Implémentée par Pytorch, qui peut aider les étudiants à maîtriser les modèles de base et les connaissances de pointe de l'apprentissage en profondeur dans un court laps de temps et d'améliorer leur capacité pratique.
De plus, ce cours a des implémentations de code correspondantes. Chaque chapitre a un bloc-notes de jupyter correspondant, fournissant le code Python complet du modèle , et toutes les ressources peuvent être obtenues gratuitement en ligne.
"Hand-on Deep Learning" (version chinoise) et la version anglaise plongeant dans Deep Learning 0.17.1 Catalogue de manuels de documentation et les liens de chapitre sont les suivants:
| chapitre | Version chinoise | Version anglaise |
|---|---|---|
| 1 | Préface | Introduction |
| 2 | Connaissances de préparation | Préliminaires |
| 3 | Réseau neuronal linéaire | Réseaux de neurones linéaires |
| 4 | Machine de détection multicouche | Perceptrons multicouches |
| 5 | Enseignement en profondeur | Calcul d'apprentissage en profondeur |
| 6 | Réseau neuronal convolutionnel | Réseaux de neurones convolutionnels |
| 7 | Réseaux de neurones convolutionnels modernes | Réseaux de neurones convolutionnels modernes |
| 8 | Réseau neuronal récurrent | Réseaux de neurones récurrents |
| 9 | Réseau de neurones récurrents moderne | Réseaux de neurones récurrents modernes |
| 10 | Mécanisme d'attention | Mécanismes d'attention |
| 11 | Algorithme d'optimisation | Algorithmes d'optimisation |
| 12 | Performance informatique | Performance informatique |
| 13 | Vision par ordinateur | Vision par ordinateur |
| 14 | Traitement du langage naturel: pré-formation | Traitement du langage naturel: pré-formation |
| 15 | Traitement du langage naturel: application | Applications de traitement du langage naturel |
| 16 | Système recommandé | Systèmes de recommandation |
| 17 | Générer des réseaux contradictoires | Réseaux adversaires génératifs |
| 18 | Annexe: les bases des mathématiques en Deep Learning | Annexe: Mathématiques pour l'apprentissage en profondeur |
| 19 | Annexe: outils d'apprentissage en profondeur | Annexe: outils pour l'apprentissage en profondeur |
| vidéo | notes | Polycopié | Code | Contributeurs |
|---|---|---|---|---|
 | 00-preview | Polycopié |  | |
 | Calendrier 01 | Polycopié | | |
 | 02 introduction à l'apprentissage en profondeur | Polycopié |  | |
 | 03-INSTALLATION | Polycopié |   | |
 | Fonctionnement des données 04 et prétraitement des données | Polycopié | Code de jupyter |   |
 | 05 algèbre linéaire | Polycopié |   | |
 | Calcul 06-matrice | Polycopié |  | |
 | Règles 07-Chengdu et dérivation automatique | Polycopié | Code de jupyter |   |
 | 08 Régression linéaire + algorithme d'optimisation de base | Notes de conférence 1 2 | Code de jupyter | |
 | 09 régression-softmax | Notes de conférence 1 2 | Code de jupyter | |
 | Machine de détection de 10 multi-couches | Notes de conférence 1 2 | Code de jupyter | |
 | Sélection à 11 modèles + sur-ajustement et sous-ajustement | Notes de conférence 1 2 | | |
 | 12 poids récession | Polycopié | Code de jupyter | |
 | Méthode de 13 dédis | Polycopié | Code de jupyter | |
 | Stabilité 14 numérique | Notes de conférence 1 2 | | |
 | Prédiction de kaggle 15 pratiques des prix des maisons | Polycopié | Code de jupyter | |
 | Basiques du réseau neuronal 16-Pytorch | Polycopié | Code de jupyter | |
 | 17 Utiliser et acheter des GPU | Polycopié | Code de jupyter | |
 | 18-SumMary de la concurrence des prix des maisons de prédiction | Polycopié | | |
 | Couche 19-Convolutionnelle | Notes de conférence 1 2 | Code de jupyter | |
 | 20 plafonds et foulée | Polycopié | Code de jupyter | |
 | 21 canaux de sortie et de sortie | Polycopié | Code de jupyter | |
 | Couche de 22 points | Polycopié | Code de jupyter | |
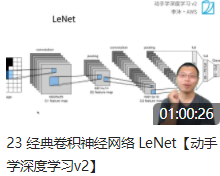 | 23-lenet | Polycopié | Code de jupyter | |
 | 24-alexnet | Polycopié | Code de jupyter | |
 | 25 réseaux VGG à l'aide de blocs | Polycopié | Code de jupyter | |
 | 26-nin | Polycopié | Code de jupyter | |
 | 27 googlenet | Polycopié | Code de jupyter | |
 | Normalisation de 28 lots | Polycopié | Code de jupyter | |
 | Resnet réseau 29-résiduel | Polycopié | | |
 | 30 parties 2 terminez la compétition | Polycopié | | |
 | 31 CPU et GPU | Polycopié | | |
 | Matériel d'apprentissage à 32 profondeurs | Polycopié | | |
 | 33 cartes multiples-machine en parallèle | Polycopié | | |
 | 34 Multi-GPU Formation Implémentation | Polycopié | Code de jupyter |  |
 | Formation à 35 distribution | Polycopié | | |
 | Augmentation de 36 données | Polycopié | Code de jupyter | |
 | Réglage de 37 fins | Polycopié | Code de jupyter | |
 | 38 - Les résultats de la deuxième classification des feuilles de compétition | Polycopié | | |
 | 39 concours de Kaggle-1-Practical-1 | Polycopié | | |
 | Compétition Kaggle à 40 pratiques-2 | Polycopié | Code de jupyter | |
 | Ensembles de détection et de données de 41 objets | Polycopié | | |
 | [Cadre 42-Anchor] | Polycopié | | |
 | Résumé 43 technique du concours de classification des feuilles | Polycopié | | |
 | Algorithme de détection de 44 objets | Notes de cours 123 | | |
 | Implémentation 45-SSD | Polycopié | Code de jupyter | |
 | Segmentation et ensembles de données 46-sémantiques | Polycopié | Code de jupyter | |
 | Convolution 47 transfert | Notes de conférence 1 2 | | |
 | 48-FCN | Polycopié | Code de jupyter | |
 | Migration de style 49 | Polycopié | Code de jupyter | |
 | Concours de 50 plats | Polycopié | | |
 | Modèle de 51 séquences | Polycopié | | |
 | Prétraitement de 52 texte | Polycopié | Code de jupyter | |
 | Modèle de langue 53 | Polycopié | | |
 | Réseau neuronal 54 | Polycopié | | |
 | Implémentation de 55-RNN | Polycopié | Code de jupyter | |
 | 56-gru | Polycopié | Code de jupyter | |
 | 57 lstm | Polycopié | | |
 | Réseau de neurones récurrents de 58 profondeurs | Polycopié | Code de jupyter | |
 | [59 réseau neuronal récurrent bidirectionnel] | Polycopié | | |
 | Ensemble de données de traduction de 60 machines | Polycopié | Code de jupyter | |
 | Architecture de décodeur 61 | Polycopié | | |
 | Apprentissage de 62 séquence à la séquence | Polycopié | Code de jupyter | |
 | Recherche de 63 bouchons | Polycopié | | |
 | 64 - Mécanisme d'attention | Polycopié | Code de jupyter | |
 | Score d'attention 65 | Polycopié | | |
 | [66-seq en utilisant l'attention] | Polycopié | | |
 | 67 auto-attention | Polycopié | Code de jupyter | |
 | 68 transformateur | Polycopié | Code de jupyter | |
 | Pré-formation 69-BERT | Polycopié | | |
 | Ajustement fin 70-BERT | Polycopié | | |
 | [71-Summary du concours de détection cible] | Polycopié | | |
 | Algorithme d'optimisation 72 | Polycopié | | |
 | Résumé de 73 plats et apprentissage avancé | Polycopié | |
Merci aux étudiants suivants pour avoir organisé ce projet
Merci aux étudiants suivants pour leur soutien et leur contribution à ce projet


