DeepLearning MuLi Notes
1.0.0
Project motivation/ Course introduction/ Course resources/ Textbook catalog/ Notes/ Folder description/ Organizer/ Contributor
"Hand-On Learning Deep Learning" is a series of deep learning videos taught by Mr. Li Mu (a senior chief scientist at AWS, Ph.D., Department of Computer Science, Carnegie Mellon University, USA). This project collects detailed markdown notes and related jupyter codes during our winter vacation learning "Hand-On Learning Deep Learning" process. Giving someone a rose will leave a fragrance on your hands. We open source all markdown notes. We hope that while learning by ourselves, it will also be helpful for everyone to learn and master Teacher Li Mu's "Hand-On Learning Deep Learning".
Features of this project:
- Markdown notes correspond to the original course video one by one, which can help everyone understand while listening to the class.
- The jupyter codes have detailed Chinese annotations to help everyone get started with practice faster.
There are 73 course videos in total , and the average duration of a single video is no more than 30 minutes . It is expected that the study can be completed within 40 days of winter vacation .
The badge used in this project comes from the Internet. If it infringes on your image copyright, please contact us to delete it. Thank you.
Usually when we mention deep learning, we often forget that deep learning is just a small part of machine learning, and think it is a separate module independent of machine learning. This is because machine learning, as a discipline with a longer history, had a narrow range of applications in the real world before deep learning was released. In the fields of speech recognition, computer vision, natural language processing, etc., machine learning is often just a small part of the solutions to solve these domain problems because of the large amount of domain knowledge required and the reality is extremely complex. But in the past few years, the advent and application of deep learning have brought surprises to the world, promoting the rapid development of computer vision, natural language processing, automatic speech recognition, reinforcement learning and statistical modeling, and gradually leading the trend, setting off a wave of artificial intelligence revolution in the world.
In the course "Hand-On Deep Learning" , there are not only a small amount of basic knowledge of machine learning, such as linear neural networks, multi-layer perception machines , etc.; there are also various deep learning models that are currently used in cutting-edge applications: including leNet, ResNet, LSTM, BERT... At the same time, the explanation of each chapter is also equipped with code, textbooks, etc. implemented by pytorch, which can help students master the basic models and cutting-edge knowledge of deep learning in a short period of time and improve their practical ability.
In addition, this course has corresponding code implementations. Each chapter has a corresponding jupyter notepad, providing the complete python code of the model , and all resources can be obtained for free online.
"Hand-On Deep Learning" (Chinese version) and English version Dive into Deep Learning 0.17.1 documentation textbook catalog and chapter links are as follows:
| chapter | Chinese version | English version |
|---|---|---|
| 1 | Preface | Introduction |
| 2 | Preparation knowledge | Preliminaries |
| 3 | Linear neural network | Linear Neural Networks |
| 4 | Multi-layer sensing machine | Multilayer Perceptrons |
| 5 | Deep Learning Computing | Deep Learning Computation |
| 6 | Convolutional neural network | Convolutional Neural Networks |
| 7 | Modern convolutional neural networks | Modern Convolutional Neural Networks |
| 8 | Recurrent neural network | Recurrent Neural Networks |
| 9 | Modern recurrent neural network | Modern Recurrent Neural Networks |
| 10 | Attention mechanism | Attention Mechanisms |
| 11 | Optimization algorithm | Optimization Algorithms |
| 12 | Computational performance | Computational Performance |
| 13 | Computer Vision | Computer Vision |
| 14 | Natural Language Processing: Pre-training | Natural Language Processing: Pretraining |
| 15 | Natural Language Processing: Application | Natural Language Processing Applications |
| 16 | Recommended system | Recommender Systems |
| 17 | Generate adversarial networks | Generative Adversarial Networks |
| 18 | Appendix: The basics of mathematics in deep learning | Appendix: Mathematics for Deep Learning |
| 19 | Appendix: Deep Learning Tools | Appendix: Tools for Deep Learning |
| video | notes | Handout | Code | Contributors |
|---|---|---|---|---|
 | 00-Preview | Handout |  | |
 | 01-Course Schedule | Handout | | |
 | 02-Introduction to Deep Learning | Handout |  | |
 | 03-Installation | Handout |   | |
 | 04-Data operation and data preprocessing | Handout | Jupyter Code |   |
 | 05-Linear Algebra | Handout |   | |
 | 06-Matrix calculation | Handout |  | |
 | 07-Chengdu Rules and Automatic Derivation | Handout | Jupyter Code |   |
 | 08-Linear Regression + Basic Optimization Algorithm | Lecture Notes 1 2 | Jupyter Code | |
 | 09-Softmax Regression | Lecture Notes 1 2 | Jupyter Code | |
 | 10-Multi-layer sensing machine | Lecture Notes 1 2 | Jupyter Code | |
 | 11-Model selection + overfitting and underfitting | Lecture Notes 1 2 | | |
 | 12-Weight Recession | Handout | Jupyter Code | |
 | 13-Discarding method | Handout | Jupyter Code | |
 | 14-Numerical Stability | Lecture Notes 1 2 | | |
 | 15-Practical Kaggle Prediction of House Prices | Handout | Jupyter Code | |
 | 16-Pytorch neural network basics | Handout | Jupyter Code | |
 | 17-Use and Buy GPUs | Handout | Jupyter Code | |
 | 18-Summary of the Prediction House Price Competition | Handout | | |
 | 19-Convolutional Layer | Lecture Notes 1 2 | Jupyter Code | |
 | 20-Fill and stride | Handout | Jupyter Code | |
 | 21-Multi-input and output channels | Handout | Jupyter Code | |
 | 22-Pooling Layer | Handout | Jupyter Code | |
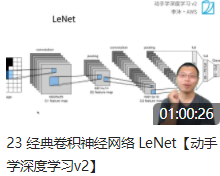 | 23-LeNet | Handout | Jupyter Code | |
 | 24-AlexNet | Handout | Jupyter Code | |
 | 25-Network VGG using blocks | Handout | Jupyter Code | |
 | 26-NiN | Handout | Jupyter Code | |
 | 27-GoogLeNet | Handout | Jupyter Code | |
 | 28-Batch Normalization | Handout | Jupyter Code | |
 | 29-Residual Network ResNet | Handout | | |
 | 30-Part 2 Finish the Competition | Handout | | |
 | 31-CPU and GPU | Handout | | |
 | 32-Deep Learning Hardware | Handout | | |
 | 33-Single-machine multiple cards in parallel | Handout | | |
 | 34-Multi-GPU training implementation | Handout | Jupyter Code |  |
 | 35-Distributed Training | Handout | | |
 | 36-Data augmentation | Handout | Jupyter Code | |
 | 37-fine adjustment | Handout | Jupyter Code | |
 | 38-The results of the second competition leaf classification | Handout | | |
 | 39-Practical Kaggle Competition-1 | Handout | | |
 | 40-Practical Kaggle Competition-2 | Handout | Jupyter Code | |
 | 41-Object Detection and Data Sets | Handout | | |
 | [42-Anchor Frame] | Handout | | |
 | 43-Technical summary of leaves classification competition | Handout | | |
 | 44-Object Detection Algorithm | Lecture Notes 123 | | |
 | 45-SSD implementation | Handout | Jupyter Code | |
 | 46-Semantic segmentation and datasets | Handout | Jupyter Code | |
 | 47-Transfer Convolution | Lecture Notes 1 2 | | |
 | 48-FCN | Handout | Jupyter Code | |
 | 49-Style Migration | Handout | Jupyter Code | |
 | 50-Course Competition | Handout | | |
 | 51-Sequence Model | Handout | | |
 | 52-Text Preprocessing | Handout | Jupyter Code | |
 | 53-Language Model | Handout | | |
 | 54-Recurrent Neural Network | Handout | | |
 | 55-RNN implementation | Handout | Jupyter Code | |
 | 56-GRU | Handout | Jupyter Code | |
 | 57-LSTM | Handout | | |
 | 58-Deep Recurrent Neural Network | Handout | Jupyter Code | |
 | [59-Bidirectional recurrent neural network] | Handout | | |
 | 60-Machine Translation Dataset | Handout | Jupyter Code | |
 | 61-Encoder-Decoder Architecture | Handout | | |
 | 62-Sequence-to-Sequence Learning | Handout | Jupyter Code | |
 | 63-Bunch Search | Handout | | |
 | 64- Attention Mechanism | Handout | Jupyter Code | |
 | 65- Attention Score | Handout | | |
 | [66-seq using attention] | Handout | | |
 | 67-Self-attention | Handout | Jupyter Code | |
 | 68-Transformer | Handout | Jupyter Code | |
 | 69-BERT pre-training | Handout | | |
 | 70-BERT fine adjustment | Handout | | |
 | [71-Summary of the Target Detection Competition] | Handout | | |
 | 72-Optimization Algorithm | Handout | | |
 | 73-Course Summary and Advanced Learning | Handout | |
Thanks to the following students for organizing this project
Thank you to the following students for their support and contribution to this project


