lightly
More and better Transforms
Légèrement SSL est un cadre de vision par ordinateur pour l'apprentissage auto-supervisé.
Pour une version commerciale avec plus de fonctionnalités, y compris les modèles de support Docker et de pré-formation pour l'intégration, la classification, la détection et les tâches de segmentation avec une seule commande, veuillez contacter [email protected].
Nous avons également construit une plate-forme entière sur le dessus, avec des fonctionnalités supplémentaires pour l'apprentissage actif et la conservation des données. Si vous êtes intéressé par la solution légèrement des travailleurs pour traiter facilement des millions d'échantillons et exécuter des algorithmes puissants sur vos données, consultez légèrement.ai. C'est gratuit pour commencer!
Ce cadre d'apprentissage auto-supervisé offre les fonctionnalités suivantes:
Vous pouvez trouver un exemple de code pour tous les modèles pris en charge ici. Nous fournissons des exemples distribués Pytorch, Pytorch Lightning et Pytorch Lightning pour tous les modèles pour lancer votre projet.
Modèles :
| Modèle | Année | Papier | Docs | Colab (pytorch) | Colab (Pytorch Lightning) |
|---|---|---|---|---|---|
| BUT | 2024 | papier | docs | ||
| Jumeaux de Barlow | 2021 | papier | docs | ||
| Byol | 2020 | papier | docs | ||
| DCL & DCLW | 2021 | papier | docs | ||
| Secl | 2021 | papier | docs | ||
| Dino | 2021 | papier | docs | ||
| Mae | 2021 | papier | docs | ||
| MSN | 2022 | papier | docs | ||
| Moco | 2019 | papier | docs | ||
| NNCLR | 2021 | papier | docs | ||
| PMSN | 2022 | papier | docs | ||
| Simclr | 2020 | papier | docs | ||
| Simmim | 2022 | papier | docs | ||
| Simisiam | 2021 | papier | docs | ||
| Agiter | 2020 | papier | docs | ||
| Vicreg | 2021 | papier | docs |
Vous voulez passer aux tutoriels et voir légèrement en action?
Projets communautaires et partenaires:
Nécessite légèrement Python 3.7+ . Nous vous recommandons d'installer légèrement dans un environnement Linux ou OSX . Python 3.13 n'est pas encore pris en charge, car Pytorch lui-même manque de compatibilité Python 3.13.
En raison de la nature modulaire de l'emballage légèrement, certains modules peuvent être utilisés avec des versions plus anciennes de dépendances. Cependant, pour utiliser toutes les fonctionnalités d'aujourd'hui, il faut légèrement les dépendances suivantes:
Légèrement est compatible avec Pytorch et Pytorch Lightning V2.0 +!
Vous pouvez installer légèrement et ses dépendances de PYPI avec:
pip3 install lightly
Nous vous recommandons fortement d'installer légèrement dans un virtualenv dédié pour éviter les conflits avec vos packages système.
Avec à la légère, vous pouvez utiliser les dernières méthodes d'apprentissage auto-supervisées d'une manière modulaire en utilisant toute la puissance de Pytorch. Expérimentez avec divers squeries, modèles et fonctions de perte. Le cadre a été conçu pour être facile à utiliser à partir de zéro. Trouvez plus d'exemples dans nos documents.
import torch
import torchvision
from lightly import loss
from lightly import transforms
from lightly . data import LightlyDataset
from lightly . models . modules import heads
# Create a PyTorch module for the SimCLR model.
class SimCLR ( torch . nn . Module ):
def __init__ ( self , backbone ):
super (). __init__ ()
self . backbone = backbone
self . projection_head = heads . SimCLRProjectionHead (
input_dim = 512 , # Resnet18 features have 512 dimensions.
hidden_dim = 512 ,
output_dim = 128 ,
)
def forward ( self , x ):
features = self . backbone ( x ). flatten ( start_dim = 1 )
z = self . projection_head ( features )
return z
# Use a resnet backbone from torchvision.
backbone = torchvision . models . resnet18 ()
# Ignore the classification head as we only want the features.
backbone . fc = torch . nn . Identity ()
# Build the SimCLR model.
model = SimCLR ( backbone )
# Prepare transform that creates multiple random views for every image.
transform = transforms . SimCLRTransform ( input_size = 32 , cj_prob = 0.5 )
# Create a dataset from your image folder.
dataset = LightlyDataset ( input_dir = "./my/cute/cats/dataset/" , transform = transform )
# Build a PyTorch dataloader.
dataloader = torch . utils . data . DataLoader (
dataset , # Pass the dataset to the dataloader.
batch_size = 128 , # A large batch size helps with the learning.
shuffle = True , # Shuffling is important!
)
# Lightly exposes building blocks such as loss functions.
criterion = loss . NTXentLoss ( temperature = 0.5 )
# Get a PyTorch optimizer.
optimizer = torch . optim . SGD ( model . parameters (), lr = 0.1 , weight_decay = 1e-6 )
# Train the model.
for epoch in range ( 10 ):
for ( view0 , view1 ), targets , filenames in dataloader :
z0 = model ( view0 )
z1 = model ( view1 )
loss = criterion ( z0 , z1 )
loss . backward ()
optimizer . step ()
optimizer . zero_grad ()
print ( f"loss: { loss . item ():.5f } " )Vous pouvez facilement utiliser un autre modèle comme Simisiam en échangeant le modèle et la fonction de perte.
# PyTorch module for the SimSiam model.
class SimSiam ( torch . nn . Module ):
def __init__ ( self , backbone ):
super (). __init__ ()
self . backbone = backbone
self . projection_head = heads . SimSiamProjectionHead ( 512 , 512 , 128 )
self . prediction_head = heads . SimSiamPredictionHead ( 128 , 64 , 128 )
def forward ( self , x ):
features = self . backbone ( x ). flatten ( start_dim = 1 )
z = self . projection_head ( features )
p = self . prediction_head ( z )
z = z . detach ()
return z , p
model = SimSiam ( backbone )
# Use the SimSiam loss function.
criterion = loss . NegativeCosineSimilarity ()Vous pouvez trouver un exemple plus complet pour Simsiam ici.
Utilisez Pytorch Lightning pour former le modèle:
from pytorch_lightning import LightningModule , Trainer
class SimCLR ( LightningModule ):
def __init__ ( self ):
super (). __init__ ()
resnet = torchvision . models . resnet18 ()
resnet . fc = torch . nn . Identity ()
self . backbone = resnet
self . projection_head = heads . SimCLRProjectionHead ( 512 , 512 , 128 )
self . criterion = loss . NTXentLoss ()
def forward ( self , x ):
features = self . backbone ( x ). flatten ( start_dim = 1 )
z = self . projection_head ( features )
return z
def training_step ( self , batch , batch_index ):
( view0 , view1 ), _ , _ = batch
z0 = self . forward ( view0 )
z1 = self . forward ( view1 )
loss = self . criterion ( z0 , z1 )
return loss
def configure_optimizers ( self ):
optim = torch . optim . SGD ( self . parameters (), lr = 0.06 )
return optim
model = SimCLR ()
trainer = Trainer ( max_epochs = 10 , devices = 1 , accelerator = "gpu" )
trainer . fit ( model , dataloader )Voir nos documents pour un exemple complet de la foudre Pytorch.
Ou entraînez le modèle sur 4 GPU:
# Use distributed version of loss functions.
criterion = loss . NTXentLoss ( gather_distributed = True )
trainer = Trainer (
max_epochs = 10 ,
devices = 4 ,
accelerator = "gpu" ,
strategy = "ddp" ,
sync_batchnorm = True ,
use_distributed_sampler = True , # or replace_sampler_ddp=True for PyTorch Lightning <2.0
)
trainer . fit ( model , dataloader )Nous fournissons des exemples de formation multi-GPU avec une collection distribuée et un Batchnorm synchronisé. Jetez un œil à nos documents concernant la formation distribuée.
Les modèles implémentés et leurs performances sur divers ensembles de données. Les hyperparamètres ne sont pas réglés pour une précision maximale. Pour des résultats détaillés et plus d'informations sur les repères, cliquez ici.
Benchmarks ImageNet1k
Remarque : les paramètres d'évaluation sont basés sur ces articles:
Voir les scripts d'analyse comparative pour plus de détails.
| Modèle | Colonne vertébrale | Taille de lot | Époques | Top1 linéaire1 | Finetune top1 | KNN TOP1 | Tensorboard | Point de contrôle |
|---|---|---|---|---|---|---|---|---|
| Barlowtwins | RES50 | 256 | 100 | 62.9 | 72.6 | 45.6 | lien | lien |
| Byol | RES50 | 256 | 100 | 62.5 | 74.5 | 46.0 | lien | lien |
| Dino | RES50 | 128 | 100 | 68.2 | 72.5 | 49.9 | lien | lien |
| Mae | Vit-B / 16 | 256 | 100 | 46.0 | 81.3 | 11.2 | lien | lien |
| Mocov2 | RES50 | 256 | 100 | 61.5 | 74.3 | 41.8 | lien | lien |
| Simclr * | RES50 | 256 | 100 | 63.2 | 73.9 | 44.8 | lien | lien |
| Simclr * + dcl | RES50 | 256 | 100 | 65.1 | 73.5 | 49.6 | lien | lien |
| Simclr * + dclw | RES50 | 256 | 100 | 64.5 | 73.2 | 48.5 | lien | lien |
| Agiter | RES50 | 256 | 100 | 67.2 | 75.4 | 49.5 | lien | lien |
| Tico | RES50 | 256 | 100 | 49.7 | 72.7 | 26.6 | lien | lien |
| Vicreg | RES50 | 256 | 100 | 63.0 | 73.7 | 46.3 | lien | lien |
* Nous utilisons la mise à l'échelle de la vitesse d'apprentissage des racines carrées au lieu de l'échelle linéaire car elle donne de meilleurs résultats pour les tailles de lots plus petites. Voir l'annexe B.1 dans le papier SIMCLR.
Benchmarks ImageNet100 Résultats détaillés
Benchmarks Imagenette Résultats détaillés
Benchmarks CIFAR-10 Résultats détaillés
Vous trouverez ci-dessous un aperçu schématique des différents concepts du package. Les termes en gras sont expliqués plus en détail dans notre documentation.
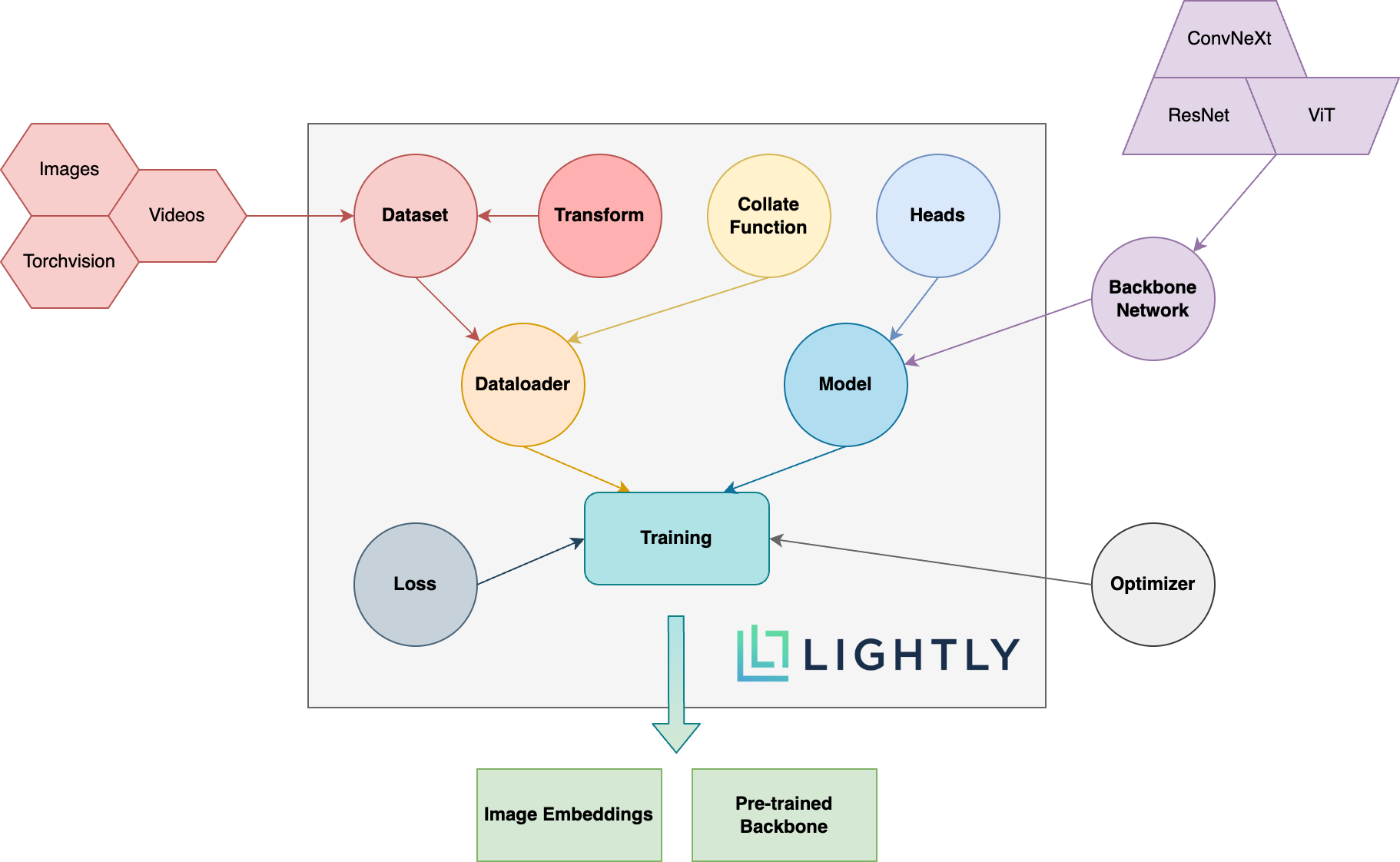
Dirigez-vous vers la documentation et voyez les choses que vous pouvez réaliser à la légère!
Pour installer des dépendances de développement (par exemple pour contribuer au framework), vous pouvez utiliser la commande suivante:
pip3 install -e ".[dev]"
Pour plus d'informations sur la façon de contribuer, jetez un œil ici.
Les tests unitaires sont dans le répertoire des tests et nous vous recommandons de les exécuter en utilisant PYTEST. Il y a deux configurations de test disponibles. Par défaut, seul un sous-ensemble sera exécuté:
make test-fast
Pour exécuter tous les tests (y compris les lents), vous pouvez utiliser la commande suivante:
make test
Pour tester un fichier ou un répertoire spécifique:
pytest <path to file or directory>
Pour formater le code avec Black et Isort Run:
make format
Apprentissage auto-supervisé :
Pourquoi devrais-je me soucier de l'apprentissage auto-supervisé? Les modèles préfabriqués d'imageNet ne sont-ils pas meilleurs pour l'apprentissage du transfert?
Comment puis-je contribuer?
Ce cadre est-il gratuitement?
Si ce cadre est gratuit, comment l'entreprise est-elle à la légère gagne à la légère?
Légèrement est un spin-off d'ETH Zurich qui aide les entreprises à construire des pipelines d'apprentissage actifs efficaces pour sélectionner les données les plus pertinentes pour leurs modèles.
Vous pouvez en savoir plus sur l'entreprise et ses services en suivant les liens ci-dessous:
Retour en haut


