lightly
More and better Transforms
Ligeramente SSL es un marco de visión por computadora para el aprendizaje auto-supervisado.
Para una versión comercial con más características, incluidos los modelos de soporte de Docker y previación para la incrustación, clasificación, detección y tareas de segmentación con un solo comando, comuníquese con [email protected].
También hemos construido una plataforma completa en la parte superior, con características adicionales para el aprendizaje activo y la curación de datos. Si está interesado en la solución de trabajador ligero para procesar fácilmente millones de muestras y ejecutar algoritmos potentes en sus datos, consulte a la ligera. ¡Es gratis comenzar!
Este marco de aprendizaje auto-supervisado ofrece las siguientes características:
Puede encontrar código de muestra para todos los modelos compatibles aquí. Proporcionamos Pytorch, Pytorch Lightning y Pytorch Lightning Ejemplos distribuidos para que todos los modelos inicien su proyecto.
Modelos :
| Modelo | Año | Papel | Documento | Colab (Pytorch) | Colab (Pytorch Lightning) |
|---|---|---|---|---|---|
| APUNTAR | 2024 | papel | documento | ||
| Barlow Twins | 2021 | papel | documento | ||
| Byol | 2020 | papel | documento | ||
| DCL y DCLW | 2021 | papel | documento | ||
| Densa | 2021 | papel | documento | ||
| Dino | 2021 | papel | documento | ||
| Mae | 2021 | papel | documento | ||
| MSN | 2022 | papel | documento | ||
| Moco | 2019 | papel | documento | ||
| Nnclr | 2021 | papel | documento | ||
| Pmsn | 2022 | papel | documento | ||
| Simclr | 2020 | papel | documento | ||
| Simmim | 2022 | papel | documento | ||
| Simsiam | 2021 | papel | documento | ||
| Swav | 2020 | papel | documento | ||
| Vicreg | 2021 | papel | documento |
¿Quieres saltar a los tutoriales y ver a la ligera en acción?
Proyectos de la comunidad y socio:
Ligeramente requiere Python 3.7+ . Recomendamos instalar ligeramente en un entorno Linux o OSX . Python 3.13 aún no es compatible, ya que Pytorch en sí carece de compatibilidad de Python 3.13.
Debido a la naturaleza modular del paquete ligeramente, algunos módulos se pueden usar con versiones más antiguas de dependencias. Sin embargo, para usar todas las características a partir de hoy requiere ligeramente las siguientes dependencias:
¡Ligeramente es compatible con Pytorch y Pytorch Lightning v2.0+!
Puede instalar ligeramente y sus dependencias de PYPI con:
pip3 install lightly
Recomendamos encarecidamente instalar a la ligera en un VirtualEnv dedicado para evitar conflictos con los paquetes de su sistema.
Con la ligera, puede usar los últimos métodos de aprendizaje auto-supervisados de manera modular utilizando la potencia completa de Pytorch. Experimente con varias columnas, modelos y funciones de pérdida. El marco ha sido diseñado para ser fácil de usar desde cero. Encuentra más ejemplos en nuestros documentos.
import torch
import torchvision
from lightly import loss
from lightly import transforms
from lightly . data import LightlyDataset
from lightly . models . modules import heads
# Create a PyTorch module for the SimCLR model.
class SimCLR ( torch . nn . Module ):
def __init__ ( self , backbone ):
super (). __init__ ()
self . backbone = backbone
self . projection_head = heads . SimCLRProjectionHead (
input_dim = 512 , # Resnet18 features have 512 dimensions.
hidden_dim = 512 ,
output_dim = 128 ,
)
def forward ( self , x ):
features = self . backbone ( x ). flatten ( start_dim = 1 )
z = self . projection_head ( features )
return z
# Use a resnet backbone from torchvision.
backbone = torchvision . models . resnet18 ()
# Ignore the classification head as we only want the features.
backbone . fc = torch . nn . Identity ()
# Build the SimCLR model.
model = SimCLR ( backbone )
# Prepare transform that creates multiple random views for every image.
transform = transforms . SimCLRTransform ( input_size = 32 , cj_prob = 0.5 )
# Create a dataset from your image folder.
dataset = LightlyDataset ( input_dir = "./my/cute/cats/dataset/" , transform = transform )
# Build a PyTorch dataloader.
dataloader = torch . utils . data . DataLoader (
dataset , # Pass the dataset to the dataloader.
batch_size = 128 , # A large batch size helps with the learning.
shuffle = True , # Shuffling is important!
)
# Lightly exposes building blocks such as loss functions.
criterion = loss . NTXentLoss ( temperature = 0.5 )
# Get a PyTorch optimizer.
optimizer = torch . optim . SGD ( model . parameters (), lr = 0.1 , weight_decay = 1e-6 )
# Train the model.
for epoch in range ( 10 ):
for ( view0 , view1 ), targets , filenames in dataloader :
z0 = model ( view0 )
z1 = model ( view1 )
loss = criterion ( z0 , z1 )
loss . backward ()
optimizer . step ()
optimizer . zero_grad ()
print ( f"loss: { loss . item ():.5f } " )Puede usar fácilmente otro modelo como Simsiam intercambiando el modelo y la función de pérdida.
# PyTorch module for the SimSiam model.
class SimSiam ( torch . nn . Module ):
def __init__ ( self , backbone ):
super (). __init__ ()
self . backbone = backbone
self . projection_head = heads . SimSiamProjectionHead ( 512 , 512 , 128 )
self . prediction_head = heads . SimSiamPredictionHead ( 128 , 64 , 128 )
def forward ( self , x ):
features = self . backbone ( x ). flatten ( start_dim = 1 )
z = self . projection_head ( features )
p = self . prediction_head ( z )
z = z . detach ()
return z , p
model = SimSiam ( backbone )
# Use the SimSiam loss function.
criterion = loss . NegativeCosineSimilarity ()Puede encontrar un ejemplo más completo para Simsiam aquí.
Use Pytorch Lightning para entrenar el modelo:
from pytorch_lightning import LightningModule , Trainer
class SimCLR ( LightningModule ):
def __init__ ( self ):
super (). __init__ ()
resnet = torchvision . models . resnet18 ()
resnet . fc = torch . nn . Identity ()
self . backbone = resnet
self . projection_head = heads . SimCLRProjectionHead ( 512 , 512 , 128 )
self . criterion = loss . NTXentLoss ()
def forward ( self , x ):
features = self . backbone ( x ). flatten ( start_dim = 1 )
z = self . projection_head ( features )
return z
def training_step ( self , batch , batch_index ):
( view0 , view1 ), _ , _ = batch
z0 = self . forward ( view0 )
z1 = self . forward ( view1 )
loss = self . criterion ( z0 , z1 )
return loss
def configure_optimizers ( self ):
optim = torch . optim . SGD ( self . parameters (), lr = 0.06 )
return optim
model = SimCLR ()
trainer = Trainer ( max_epochs = 10 , devices = 1 , accelerator = "gpu" )
trainer . fit ( model , dataloader )Vea nuestros documentos para un ejemplo completo de Pytorch Lightning.
O entrenar el modelo en 4 GPU:
# Use distributed version of loss functions.
criterion = loss . NTXentLoss ( gather_distributed = True )
trainer = Trainer (
max_epochs = 10 ,
devices = 4 ,
accelerator = "gpu" ,
strategy = "ddp" ,
sync_batchnorm = True ,
use_distributed_sampler = True , # or replace_sampler_ddp=True for PyTorch Lightning <2.0
)
trainer . fit ( model , dataloader )Proporcionamos ejemplos de capacitación multi-GPU con recopilación distribuida y lotes sincronizados. Eche un vistazo a nuestros documentos con respecto a la capacitación distribuida.
Implementó modelos y su rendimiento en varios conjuntos de datos. Los hiperparámetros no están sintonizados para obtener la máxima precisión. Para obtener resultados detallados y más información sobre los puntos de referencia, haga clic aquí.
Puntos de referencia de imagenet1k
Nota : La configuración de evaluación se basa en estos documentos:
Vea los scripts de evaluación comparativa para más detalles.
| Modelo | Columna vertebral | Tamaño por lotes | Épocas | Top1 lineal | Finetune Top1 | KNN TOP1 | Tabla tensor | Control |
|---|---|---|---|---|---|---|---|---|
| Barlowtwins | Res50 | 256 | 100 | 62.9 | 72.6 | 45.6 | enlace | enlace |
| Byol | Res50 | 256 | 100 | 62.5 | 74.5 | 46.0 | enlace | enlace |
| Dino | Res50 | 128 | 100 | 68.2 | 72.5 | 49.9 | enlace | enlace |
| Mae | Vit-b/16 | 256 | 100 | 46.0 | 81.3 | 11.2 | enlace | enlace |
| Mocov2 | Res50 | 256 | 100 | 61.5 | 74.3 | 41.8 | enlace | enlace |
| Simclr* | Res50 | 256 | 100 | 63.2 | 73.9 | 44.8 | enlace | enlace |
| Simclr* + dcl | Res50 | 256 | 100 | 65.1 | 73.5 | 49.6 | enlace | enlace |
| Simclr* + dclw | Res50 | 256 | 100 | 64.5 | 73.2 | 48.5 | enlace | enlace |
| Swav | Res50 | 256 | 100 | 67.2 | 75.4 | 49.5 | enlace | enlace |
| Tico | Res50 | 256 | 100 | 49.7 | 72.7 | 26.6 | enlace | enlace |
| Vicreg | Res50 | 256 | 100 | 63.0 | 73.7 | 46.3 | enlace | enlace |
*Utilizamos la escala de la tasa de aprendizaje de raíz cuadrada en lugar de la escala lineal, ya que produce mejores resultados para tamaños de lotes más pequeños. Ver Apéndice B.1 en el documento SIMCLR.
Imagenet100 puntos de referencia resultados detallados
Imagenette Benchmars Resultados detallados
CIFAR-10 puntos de referencia resultados detallados
A continuación puede ver una descripción esquemática de los diferentes conceptos en el paquete. Los términos en negrita se explican con más detalle en nuestra documentación.
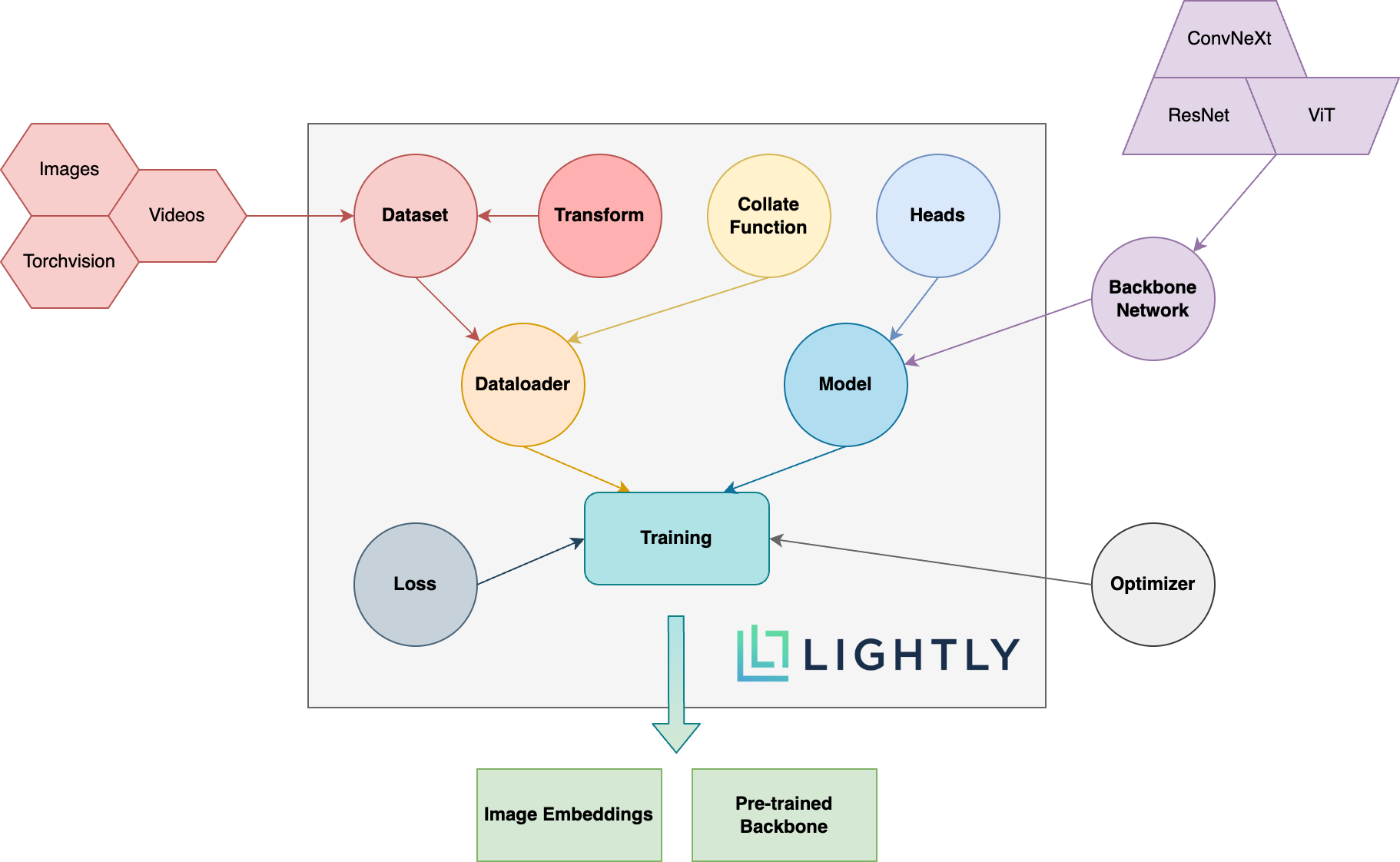
¡Dirígete a la documentación y mira las cosas con las que puedes lograr a la ligera!
Para instalar Dev Dependencias (por ejemplo, para contribuir al marco) puede usar el siguiente comando:
pip3 install -e ".[dev]"
Para obtener más información sobre cómo contribuir, eche un vistazo aquí.
Las pruebas unitarias están dentro del directorio de pruebas y recomendamos ejecutarlas usando Pytest. Hay dos configuraciones de prueba disponibles. Por defecto, solo se ejecutará un subconjunto:
make test-fast
Para ejecutar todas las pruebas (incluidas las lentas), puede usar el siguiente comando:
make test
Para probar un archivo o directorio específico:
pytest <path to file or directory>
Para formatear el código con Black and Isort Run:
make format
Aprendizaje auto-supervisado :
¿Por qué debería preocuparme por el aprendizaje auto-supervisado? ¿No son los modelos previamente entrenados de ImageNet mucho mejores para el aprendizaje de transferencia?
¿Cómo puedo contribuir?
¿Es este marco gratis?
Si este marco es gratuito, ¿cómo está la compañía que está detrás de ganar dinero a la ligera?
Lightly es un spin-off de ETH Zurich que ayuda a las empresas a construir tuberías de aprendizaje activas eficientes para seleccionar los datos más relevantes para sus modelos.
Puede obtener más información sobre la empresa y sus servicios siguiendo los enlaces a continuación:
Volver arriba


