Instagram Crawler
1.0.0
Ce projet nous couvrons plusieurs segments de collecte de données sur Instagram
Installer Python 3.6.0
Installez le package PIP, saisissez la ligne de commande:
python get-pip.py
Installez les demandes PIP (cela installera les cadres Django et Selenium)
cd * PATH * / Project
pip install -r requirements.txt
Installer Firefox Client (vous pouvez télécharger le célèbre navigateur Mozilla Firefox)
Complété
Si vous souhaitez utiliser la plate-forme Web, vous devez déployer l'intégralité du système Django dans la base de données. Nous le faisons avec le code suivant:
cd * PATH * / Project / web. / manage.py makemigrations
Cela effectuera les migrations du modèle. /manage.py migrer les migrations converties d'un modèle à une base
Accès par défaut utilisateur / administrateur:
Pour créer un super administrateur qui a tous les privilèges, Type:
./manage.py createsuperuser
Entrez les champs nécessaires.
Pour activer le serveur, exécutez la commande suivante et activez l'application Web Django au port 8000
./manage.py runserver 8000
L'utilisation du script pour collecter des données est trop simple, voici l'API complète avec laquelle vous pouvez servir.
Avertissement! Avant de commencer à utiliser tout type de service à partir du robot, vous devez configurer l'utilisateur d'authentification Instagram qui sera utilisé pour ramper les données qui sont visibles uniquement pour les utilisateurs authentifiés
Allez dans Project / Script / Settings.py
Modifier les informations d'authentification
La valeur par défaut est: username = "kiril_cvetkov" mot de passe = " * "
Entrez votre nom d'utilisateur et votre mot de passe à travers lequel le navigateur se connectera.
Une fois que nous avons configuré notre renifleur, ci-dessous est l'API complète ainsi qu'un exemple pour donner une image complète de la façon dont le script peut être utilisé
crawl.py [-db EXPORT_DB] [-DIR DIRECTORY] [-page PAGE_NAME] [-more MORE_DETAILS] [-num POST_NUMBER]
* [-db EXPORT_DB] Whether to save data in a database or only in a file system
* [-DIR DIRECTORY]: Directory where the data will be stored
* [-page PAGE_NAME]: Profile / crawling page
* [-more MORE_DETAILS]: Retrieve more details, such as a number of likes, description of pictures within a single photo
Allez d'abord au répertoire où se trouve le script
cd * PATH * / Project / script
Afin d'exécuter le script et de ramper les données de la page de Bill Gates :), veuillez taper:
python crawl.py -num = 30 -page = thisisbillgates -more -db
Vous pouvez voir toutes les pages indexées par notre chercheur
Vous pouvez filtrer les images contenant un mot-clé sur le nom de la page ou vous pouvez rechercher par des mots clés contenus dans leur description
Vous pouvez cliquer sur une image spécifique et la répertorier dans une galerie
Vous pouvez modifier les données via le panneau d'administration pour accéder à la section Admin, saisir l'URL suivante
localhost: 8000 / admin
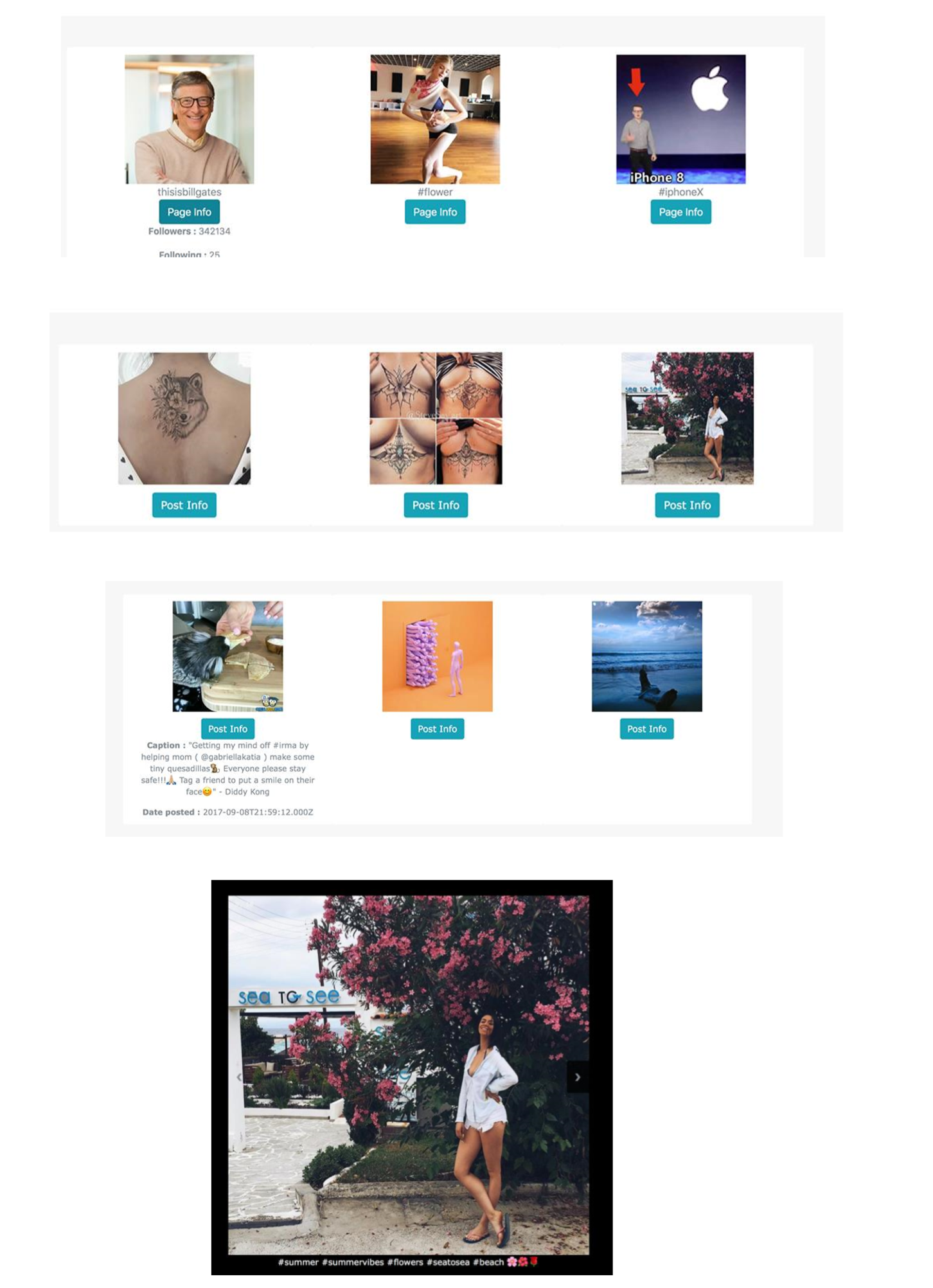
La plus grande utilisation sur une architecture aussi définie et mise en œuvre est que la récupération des données peut nous apporter une puissance énorme aujourd'hui, en particulier dans le domaine des mégadonnées , de l'apprentissage en profondeur et d'autres algorithmes d'apprentissage automatique . Si nous recherchons des images avec certains hashtags, le système nous donne des images qui contiennent logiquement le même hashtag. Nous ne pouvons qu'imaginer comment Instagram utilise des hashtags pour former un système à reconnaître divers événements, objets, événements, articles, modèles en temps réel. Mais avec l'utilisation de ce script, toutes les informations sont disponibles si nous savons les prendre. Les navigateurs Web et la récupération Web sont une capacité puissante que chaque développeur et analyste commercial doit avoir.


