Instagram Crawler
1.0.0
Este proyecto cubrimos varios segmentos de recopilación de datos de Instagram
Instale Python 3.6.0
Instale el paquete PIP, escriba la línea de comando:
python get-pip.py
Instale solicitudes PIP (esto instalará marcos de Django y Selenium)
cd * PATH * / Project
pip install -r requirements.txt
Instale el cliente Firefox (puede descargar el famoso navegador Mozilla Firefox)
Terminado
Si desea utilizar la plataforma web, debe implementar todo el sistema Django en la base de datos. Hacemos esto con el siguiente código:
cd * PATH * / Project / web. / manage.py makemigrations
Esto realizará las migraciones del modelo. /manage.py migra las migraciones de conversión de un modelo a una base
Acceso predeterminado de usuario/administrador:
Para crear un super administrador que tenga todos los privilegios, escriba:
./manage.py createsuperuser
Ingrese los campos que se requieren.
Para encender el servidor, ejecute el siguiente comando y active la aplicación web Django en el puerto 8000
./manage.py runserver 8000
Usar el script para recopilar datos es demasiado simple, aquí está la API completa con la que puede servir.
¡Advertencia! Antes de comenzar a usar cualquier tipo de servicio del rastreador, debe configurar el usuario de autenticación de Instagram que se utilizará para rastrear los datos que son visibles solo para usuarios autenticados
Vaya a Project / script / settings.py
Cambiar información de autenticación
El valor predeterminado es: username = "kiril_cvetkov" contraseña = " * "
Ingrese su nombre de usuario y contraseña a través de la cual el navegador iniciará sesión.
Una vez que hemos configurado nuestro sniffer, a continuación se encuentra la API completa, así como un ejemplo para dar una imagen completa de cómo se puede usar el script.
crawl.py [-db EXPORT_DB] [-DIR DIRECTORY] [-page PAGE_NAME] [-more MORE_DETAILS] [-num POST_NUMBER]
* [-db EXPORT_DB] Whether to save data in a database or only in a file system
* [-DIR DIRECTORY]: Directory where the data will be stored
* [-page PAGE_NAME]: Profile / crawling page
* [-more MORE_DETAILS]: Retrieve more details, such as a number of likes, description of pictures within a single photo
Primero vaya al directorio donde se encuentra el script
cd * PATH * / Project / script
Para ejecutar el script y rastrear los datos de la página de Bill Gates :), escriba:
python crawl.py -num = 30 -page = thisisbillgates -more -db
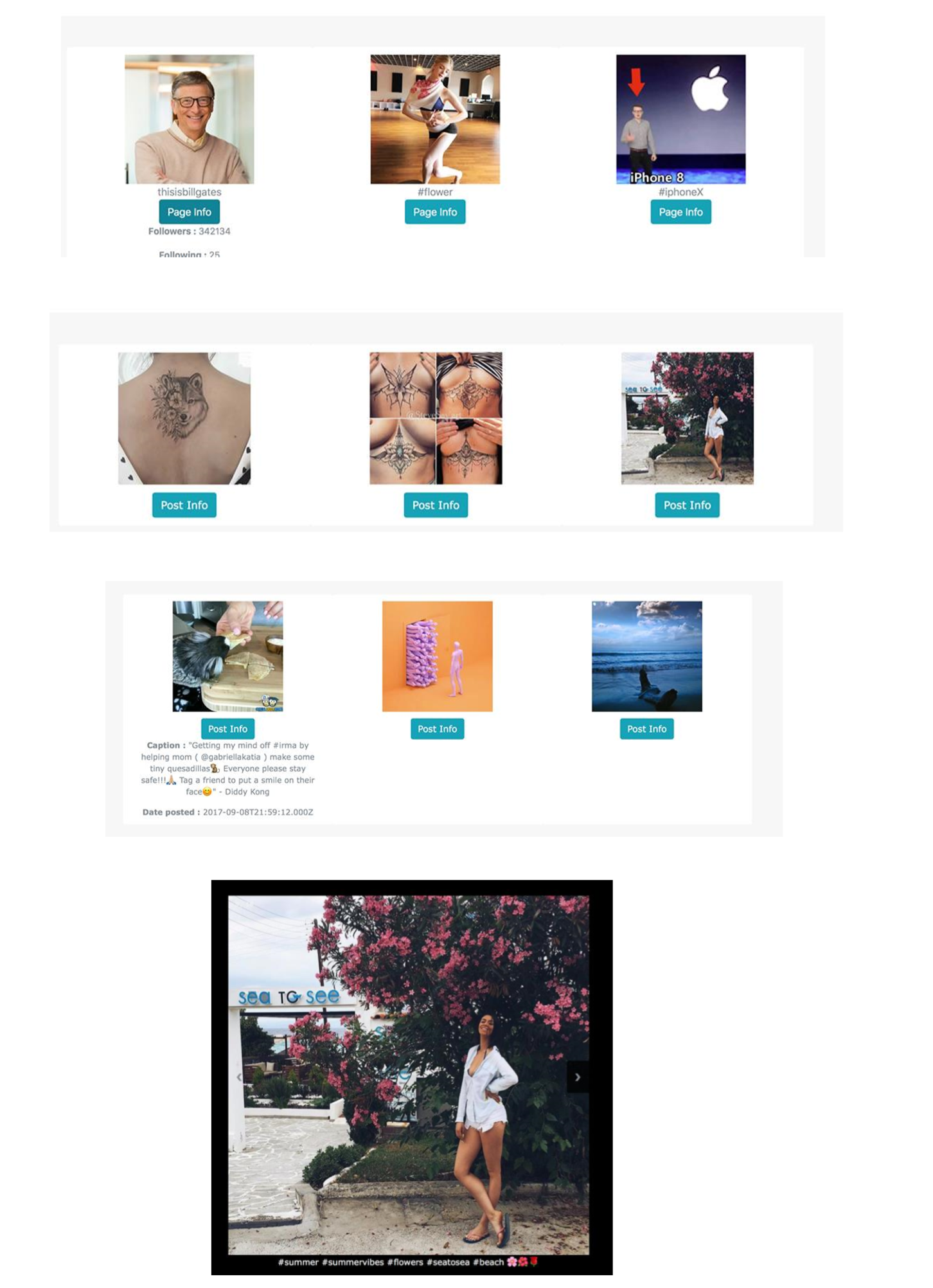
Puede ver todas las páginas indexadas por nuestro buscador
Puede filtrar imágenes que contienen una palabra clave en el nombre de la página o puede buscar por palabras clave contenidas en su descripción
Puede hacer clic en una imagen específica y enumerarla en una galería
Puede modificar los datos a través del panel de administración para acceder a la sección de administración, escriba la siguiente URL
Localhost: 8000/administrador
El mayor uso en una arquitectura tan definida e implementada es que la recuperación de datos puede brindarnos un enorme poder hoy, especialmente en el campo de los grandes datos , el aprendizaje profundo y otros algoritmos de aprendizaje automático . Si buscamos imágenes con ciertos hashtags, entonces el sistema nos da imágenes que lógicamente contienen el mismo hashtag. Solo podemos imaginar cómo Instagram usa hashtags para entrenar un sistema para reconocer varios eventos, objetos, eventos, artículos, modelos en tiempo real. Pero con el uso de este script, toda la información está disponible para nosotros si sabemos cómo llevarlos. Los navegadores web y la recuperación web es una capacidad poderosa que todos los desarrolladores y analistas de negocios deben tener.


