Instagram Crawler
1.0.0
In diesem Projekt behandeln wir mehrere Datenerfassungsegmente von Instagram
Installieren Sie Python 3.6.0
Installieren Sie das PIP -Paket und geben Sie die Befehlszeile ein:
python get-pip.py
Installieren Sie PIP -Anfragen (dadurch werden Django- und Selenium -Frames installiert)
cd * PATH * / Project
pip install -r requirements.txt
Installieren Sie den Firefox -Client (Sie können den berühmten Mozilla Firefox -Browser herunterladen)
Vollendet
Wenn Sie die Webplattform nutzen möchten, müssen Sie das gesamte Django -System in der Datenbank bereitstellen. Wir tun dies mit dem folgenden Code:
cd * PATH * / Project / web. / manage.py makemigrations
Dies führt die Migrationen aus dem Modell aus. /Manage.py migrieren Konvertieren Migrationen von einem Modell zu einer Basis
Standard -Benutzer-/Administratorzugriff:
Um einen Superadministrator zu erstellen, der über alle Berechtigungen verfügt, geben Sie an:
./manage.py createsuperuser
Geben Sie die erforderlichen Felder ein.
Führen Sie den folgenden Befehl aus, um den Server einzuschalten, und aktivieren Sie die Django -Webanwendung unter Port 8000
./manage.py runserver 8000
Die Verwendung des Skripts zum Sammeln von Daten ist zu einfach. Hier finden Sie die vollständige API, mit der Sie servieren können.
Warnung! Bevor Sie mit dem Crawler -Dienst anfangen, müssen Sie den Authentifizierungsinstagram -Benutzer konfigurieren, der zum Krabbeln der Daten verwendet wird, die nur für authentifizierte Benutzer sichtbar sind
Gehen Sie zu Project / script / setting.py
Authentifizierungsinformationen ändern
Standard ist: userername = "kiril_cvetkov" password = " * "
Geben Sie Ihren Benutzernamen und Ihr Passwort ein, über das sich der Browser anmelden.
Sobald wir unseren Sniffer konfiguriert haben, finden Sie unten die vollständige API sowie ein Beispiel, um ein vollständiges Bild darüber zu geben, wie das Skript verwendet werden kann
crawl.py [-db EXPORT_DB] [-DIR DIRECTORY] [-page PAGE_NAME] [-more MORE_DETAILS] [-num POST_NUMBER]
* [-db EXPORT_DB] Whether to save data in a database or only in a file system
* [-DIR DIRECTORY]: Directory where the data will be stored
* [-page PAGE_NAME]: Profile / crawling page
* [-more MORE_DETAILS]: Retrieve more details, such as a number of likes, description of pictures within a single photo
Gehen Sie zuerst in das Verzeichnis, in dem sich das Drehbuch befindet
cd * PATH * / Project / script
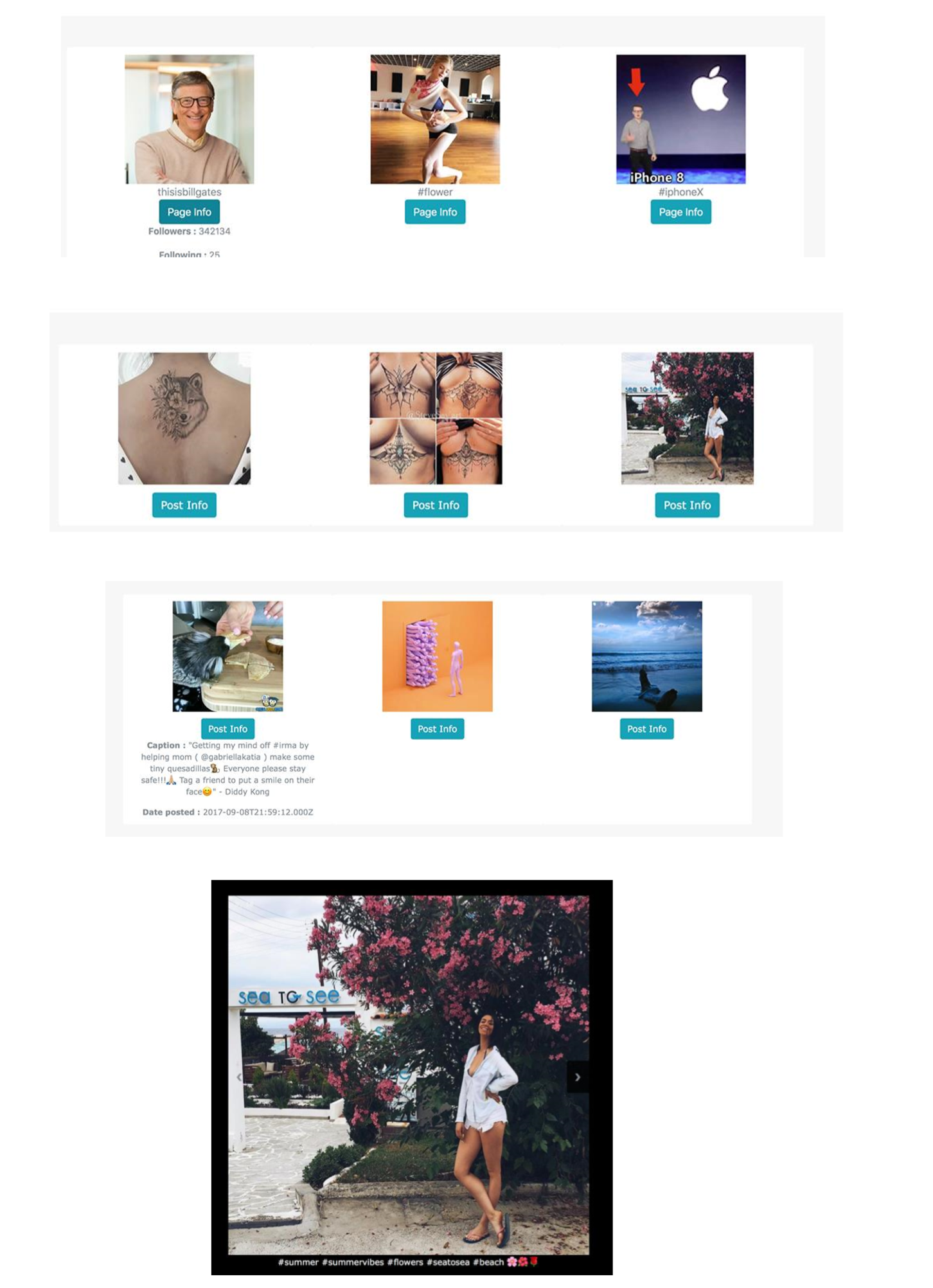
Um das Skript auszuführen und die Daten aus der Seite von Bill Gates zu kriechen :) Tippen Sie bitte:
python crawl.py -num = 30 -page = thisisbillgates -more -db
Sie können alle Seiten sehen, die von unserem Sucher indiziert werden
Sie können Bilder filtern, die ein Schlüsselwort auf dem Seitennamen enthalten oder nach Schlüsselwörtern suchen, die in ihrer Beschreibung enthalten sind
Sie können auf ein bestimmtes Bild klicken und es in einer Galerie auflisten
Sie können die Daten über das Administrationsfeld ändern, um auf den Abschnitt Administrator zuzugreifen. Geben Sie die folgende URL ein
Localhost: 8000/Admin
Die größte Verwendung in einer so definierten und implementierten Architektur besteht darin, dass das Abrufen von Daten uns heute enorme Macht bringen kann, insbesondere im Bereich Big Data , Deep Learning und andere Algorithmen für maschinelles Lernen . Wenn wir nach Bildern mit bestimmten Hashtags suchen, gibt das System uns Bilder, die logisch denselben Hashtag enthalten. Wir können uns nur vorstellen, wie Instagram Hashtags verwendet, um ein System zu schulen, um verschiedene Ereignisse, Objekte, Ereignisse, Artikel und Modelle in Echtzeit zu erkennen. Mit der Verwendung dieses Skripts stehen uns jedoch alle Informationen zur Verfügung, wenn wir wissen, wie wir sie nehmen. Webbrowser und Webabruf sind eine leistungsstarke Fähigkeit, die jeder Entwickler und Geschäftsanalytiker haben muss.


