SmoothNLP
1.0.0
| Autor | Correo electrónico |
|---|---|
| Vencedor | [email protected] |
| Yinjun | [email protected] |
| medusa | [email protected] |
Instalar a través de pip
pip install smoothnlp > =0.4.0Instale la última versión a través del código fuente
git clone https://github.com/smoothnlp/SmoothNLP.git
cd SmoothNLP
python setup.py installSolo versiones compatibles de SmoothNLP
V0.3.0y posterior; Los siguientes son ejemplos después de la versiónV0.4:
from smoothnlp . algorithm import kg
from kgexplore import visual
ngrams = kg . extract_ngram ([ "SmoothNLP在V0.3版本中正式推出知识抽取功能" ,
"SmoothNLP专注于可解释的NLP技术" ,
"SmoothNLP支持Python与Java" ,
"SmoothNLP将帮助工业界与学术界更加高效的构建知识图谱" ,
"SmoothNLP是上海文磨网络科技公司的开源项目" ,
"SmoothNLP在V0.4版本中推出对图谱节点的分类功能" ,
"KGExplore是SmoothNLP的一个子项目" ])
visual . visualize ( ngrams , width = 12 , height = 10 )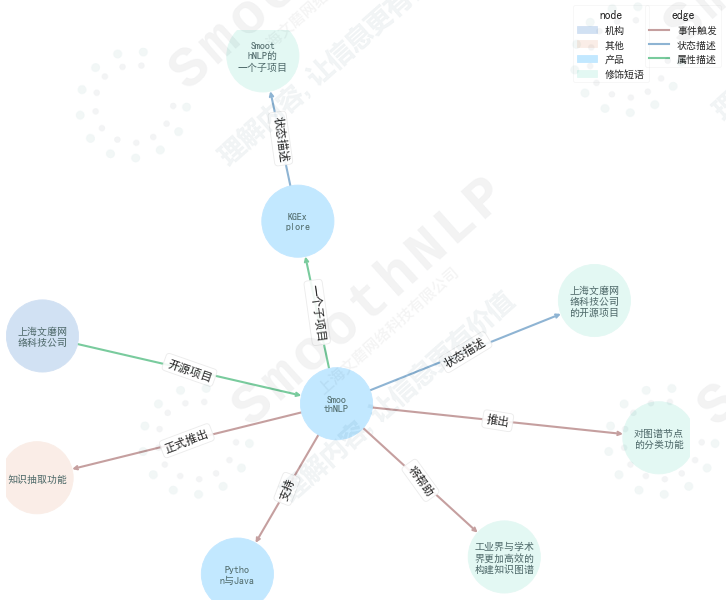
Descripción de la función
事件触发,状态描述,属性描述y数值描述.产品,地区,公司与品牌,货品,机构,人物,修饰短语y其他. >> import smoothnlp
>> smoothnlp . segment ( '欢迎在Python中使用SmoothNLP' )
[ '欢迎' , '在' , 'Python' , '中' , '使用' , 'SmoothNLP' ]Explicación de etiqueta de parte del voz wiki
>> smoothnlp . postag ( '欢迎使用smoothnlp的Python接口' )
[{ 'token' : '欢迎' , 'postag' : 'VV' },
{ 'token' : '在' , 'postag' : 'P' },
{ 'token' : 'Python' , 'postag' : 'NN' },
{ 'token' : '中' , 'postag' : 'LC' },
{ 'token' : '使用' , 'postag' : 'VV' },
{ 'token' : 'SmoothNLP' , 'postag' : 'NN' }] >> smoothnlp . ner ( "中国平安2019年度长期服务计划于2019年5月7日至5月14日通过二级市场完成购股" )
[{ 'charStart' : 0 , 'charEnd' : 4 , 'text' : '中国平安' , 'nerTag' : 'COMPANY_NAME' , 'sTokenList' : { '1' : { 'token' : '中国平安' , 'postag' : None }}, 'normalizedEntityValue' : '中国平安' },
{ 'charStart' : 4 , 'charEnd' : 9 , 'text' : '2019年' , 'nerTag' : 'NUMBER' , 'sTokenList' : { '2' : { 'token' : '2019年' , 'postag' : 'CD' }}, 'normalizedEntityValue' : '2019年' },
{ 'charStart' : 17 , 'charEnd' : 26 , 'text' : '2019年5月7日' , 'nerTag' : 'DATETIME' , 'sTokenList' : { '8' : { 'token' : '2019年5月' , 'postag' : None }, '9' : { 'token' : '7日' , 'postag' : None }}, 'normalizedEntityValue' : '2019年5月7日' },
{ 'charStart' : 27 , 'charEnd' : 32 , 'text' : '5月14日' , 'nerTag' : 'DATETIME' , 'sTokenList' : { '11' : { 'token' : '5月' , 'postag' : None }, '12' : { 'token' : '14日' , 'postag' : None }}, 'normalizedEntityValue' : '5月14日' }] >> smoothnlp . company_recognize ( "旷视科技预计将在今年9月在港IPO" )
[{ 'charStart' : 0 ,
'charEnd' : 4 ,
'text' : '旷视科技' ,
'nerTag' : 'COMPANY_NAME' ,
'sTokenList' : { '1' : { 'token' : '旷视科技' , 'postag' : None }},
'normalizedEntityValue' : '旷视科技' }]Tenga en cuenta que
Index=0devuelto porsmoothnlp.dep_parsingesrootdel ficticio.
Dependencia de la etiqueta de análisis de sintaxis explicación wiki
smoothnlp . dep_parsing ( "特斯拉是全球最大的电动汽车制造商。" )
> [{ 'relationship' : 'top' , 'dependentIndex' : 2 , 'targetIndex' : 1 },
{ 'relationship' : 'root' , 'dependentIndex' : 0 , 'targetIndex' : 2 },
{ 'relationship' : 'dep' , 'dependentIndex' : 5 , 'targetIndex' : 3 },
{ 'relationship' : 'advmod' , 'dependentIndex' : 5 , 'targetIndex' : 4 },
{ 'relationship' : 'ccomp' , 'dependentIndex' : 2 , 'targetIndex' : 5 },
{ 'relationship' : 'cpm' , 'dependentIndex' : 5 , 'targetIndex' : 6 },
{ 'relationship' : 'amod' , 'dependentIndex' : 8 , 'targetIndex' : 7 },
{ 'relationship' : 'attr' , 'dependentIndex' : 2 , 'targetIndex' : 8 },
{ 'relationship' : 'attr' , 'dependentIndex' : 2 , 'targetIndex' : 9 },
{ 'relationship' : 'punct' , 'dependentIndex' : 2 , 'targetIndex' : 10 }] smoothnlp . split2sentences ( "句子1!句子2!" )
> [ '句子1!' , '句子2!' ]SmoothNLP usa 2 hilos de forma predeterminada para llamadas de servicio;
from smoothnlp import config
config . setNumThreads ( 2 ) from smoothnlp import config
config . setLogLevel ( "DEBUG" ) ## 设定日志级别Algoritmo Introducción | Instrucciones de uso
Actualmente solo apoyamos soluciones comerciales para esta función, con servicios en línea. Para obtener más información, comuníquese con [email protected]
Demostración de efecto
[
{
"url" : " https://36kr.com/p/5167309 " ,
"title" : " Facebook第三次数据泄露,可能导致680万用户私人照片泄露" ,
"pub_ts" : 1544832000
},
{
"url" : " https://www.pencilnews.cn/p/24038.html " ,
"title" : "热点 | Facebook将因为泄露700万用户个人照片 面临16亿美元罚款" ,
"pub_ts" : 1544832000
},
{
"url" : " https://finance.sina.com.cn/stock/usstock/c/2018-12-15/doc-ihmutuec9334184.shtml " ,
"title" : " Facebook再曝新数据泄露 6800万用户或受影响" ,
"pub_ts" : 1544844120
}
]Comentario: Los datos del editor de Sina son incorrectos ... Hechos exagerados, la situación real de Facebook no filtró 68 millones de fotos
Actualmente solo apoyamos soluciones comerciales para esta función, con servicios en línea. Para más detalles, comuníquese con [email protected]; Los servicios en línea admiten la producción de API.
Efecto
| Nombre del evento | AUC | Precisión |
|---|---|---|
| Invertir y adquisición | 0.996 | 0.982 |
| Cooperación corporativa | 0.977 | 0.885 |
| Directores, supervisores y ejecutivos | 0.982 | 0.940 |
| Informe de ingresos | 0.994 | 0.960 |
| Firma de negocios | 0.993 | 0.904 |
| Desarrollo comercial | 0.968 | 0.869 |
| Informe del producto | 0.977 | 0.911 |
| Política industrial | 0.990 | 0.879 |
| Mala gestión | 0.981 | 0.765 |
| Discusión sobre violación | 0.951 | 0.890 |
Referencias
smoothnlp_maven . Se puede compilar y empaquetar a través de mavenSmoothNLP Pro admite usuarios estables y confiables de nivel empresarial, documentación; Si desea probar o comprar, [email protected]
smoothnlp.split2sentences para el preprocesamiento del corte de oraciones.SimHei de forma predeterminada. Matplotlib en la mayoría de los entornos no es compatible con las fuentes chinas. Proporcionamos un enlace de descarga para el paquete de fuentes; Puede cargar fuentes Simhei en la biblioteca de fuentes Matplotlib ejecutando el siguiente código. import matplotlib . pyplot as plt
import matplotlib . font_manager as font_manager
## 设置字体
font_dirs = [ 'simhei/' ]
font_files = font_manager . findSystemFonts ( fontpaths = font_dirs )
font_list = font_manager . createFontList ( font_files )
font_manager . fontManager . ttflist . extend ( font_list )
plt . rcParams [ 'font.family' ] = "SimHei" NLP o知识图谱, o incluso oportunidades de pasantías. Bienvenido a [email protected]

