ArticutAPI
v1.3.7
| اسم | articleapi | mp_articutapi | WS_ARTICUTAPI |
|---|---|---|---|
| منتج | عبر الإنترنت / docker | عامل ميناء | عامل ميناء |
| تكنولوجيا | طلب HTTP | المعالجة المتعددة | WebSocket |
| ميزة | بسيطة وسهلة الاستخدام | معالجة الدُفعات | المعالجة الفورية |
| السيناريوهات المعمول بها | أي | تحليل النص | chatbot |
| اسم | articleapi | mp_articutapi | WS_ARTICUTAPI |
|---|---|---|---|
| وقت | 0.1252 ثانية | 0.1206 ثانية | 0.0677 ثانية |
| عدد الجمل | articleapi | mp_articutapi | WS_ARTICUTAPI |
|---|---|---|---|
| طريقة | تحليل () | bulk_parse (20) | تحليل () |
| 1K | 155 ثانية | 8 ثوان | 18 ثانية |
| 2K | 306 ثانية | 14 ثانية | 35 ثانية |
| 3K | 455 ثانية | 17 ثانية | 43 ثانية |
MP_ArticutAPI طريقة bulk_parse (plksize = 20).WS_ArticutAPI طريقة Parse ().pip3 install ArticutAPIيرجى الرجوع إلى مستندات/index.html لوصف الوظيفة
from ArticutAPI import Articut
from pprint import pprint
username = "" #這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。
apikey = "" #這裡填入您在 https://api.droidtown.co 登入後取得的 api Key。若使用空字串,則預設使用每小時 2000 字的公用額度。
articut = Articut(username, apikey)
inputSTR = "會被大家盯上,才證明你有實力。"
resultDICT = articut.parse(inputSTR)
pprint(resultDICT)
{"exec_time": 0.06723856925964355,
"level": "lv2",
"msg": "Success!",
"result_pos": ["<MODAL>會</MODAL><ACTION_lightVerb>被</ACTION_lightVerb><ENTITY_nouny>大家</ENTITY_nouny><ACTION_verb>盯上</ACTION_verb>",
",",
"<MODAL>才</MODAL><ACTION_verb>證明</ACTION_verb><ENTITY_pronoun>你</ENTITY_pronoun><ACTION_verb>有</ACTION_verb><ENTITY_noun>實力</ENTITY_noun>",
"。"],
"result_segmentation": "會/被/大家/盯上/,/才/證明/你/有/實力/。/",
"status": True,
"version": "v118",
"word_count_balance": 9985,
"product": "https://api.droidtown.co/product/",
"document": "https://api.droidtown.co/document/"
}
يمكنك العثور على كلمات لها معاني كاملة للكلمات مثل "الاسم" أو "الفعل" أو "الصفة" وفقًا لاحتياجاتك.
inputSTR = "你計劃過地球人類補完計劃"
resultDICT = articut.parse(inputSTR, level="lv1")
pprint(resultDICT["result_pos"])
#列出所有的 content word.
contentWordLIST = articut.getContentWordLIST(resultDICT)
pprint(contentWordLIST)
#列出所有的 verb word. (動詞)
verbStemLIST = articut.getVerbStemLIST(resultDICT)
pprint(verbStemLIST)
#列出所有的 noun word. (名詞)
nounStemLIST = articut.getNounStemLIST(resultDICT)
pprint(nounStemLIST)
#列出所有的 location word. (地方名稱)
locationStemLIST = articut.getLocationStemLIST(resultDICT)
pprint(locationStemLIST)
#resultDICT["result_pos"]
["<ENTITY_pronoun>你</ENTITY_pronoun><ACTION_verb>計劃</ACTION_verb><ASPECT>過</ASPECT><LOCATION>地球</LOCATION><ENTITY_oov>人類</ENTITY_oov><ACTION_verb>補完</ACTION_verb><ENTITY_nounHead>計劃</ENTITY_nounHead>"]
#列出所有的 content word.
[[(47, 49, '計劃'), (117, 119, '人類'), (146, 147, '補'), (196, 198, '計劃')]]
#列出所有的 verb word. (動詞)
[[(47, 49, '計劃'), (146, 147, '補')]]
#列出所有的 noun word. (名詞)
[[(117, 119, '人類'), (196, 198, '計劃')]]
#列出所有的 location word. (地方名稱)
[[(91, 93, '地球')]]
resultDICT = articut.versions()
pprint(resultDICT)
{"msg": "Success!",
"status": True,
"versions": [{"level": ["lv1", "lv2"],
"release_date": "2019-04-25",
"version": "latest"},
{"level": ["lv1", "lv2"],
"release_date": "2019-04-25",
"version": "v118"},
{"level": ["lv1", "lv2"],
"release_date": "2019-04-24",
"version": "v117"},...
}
inputSTR = "小紅帽"
resultDICT = articut.parse(inputSTR, level="lv1")
pprint(resultDICT)
الفعل الشديد الفعل ، مناسب لاستخدام الترجمة التلقائي في NLU أو الماكينة. قدم النتائج لتقسيم كل عنصر في الجملة قدر الإمكان.
{"exec_time": 0.04814624786376953,
"level": "lv1",
"msg": "Success!",
"result_pos": ["<MODIFIER>小</MODIFIER><MODIFIER_color>紅</MODIFIER_color><ENTITY_nounHead>帽</ENTITY_nounHead>"],
"result_segmentation": "小/紅/帽/",
"status": True,
"version": "v118",
"word_count_balance": 9997,...}
تعتبر Phonology مناسبة لتحليل النص ، وحساب قيمة الميزات ، واستخراج الكلمات الرئيسية ، وما إلى ذلك. سيتم تقديم نتائج العرض في أصغر وحدة من المعنى.
{"exec_time": 0.04195523262023926,
"level": "lv2",
"msg": "Success!",
"result_pos": ["<ENTITY_nouny>小紅帽</ENTITY_nouny>"],
"result_segmentation": "小紅帽/",
"status": True,
"version": "v118",
"word_count_balance": 9997,...}
لأن المقالة تتعامل فقط مع "معرفة اللغة" وليس "المعرفة الموسوعة". نحن نقدم وظيفة المفردات "تخصيص المستخدم" ، والتي يتم استخدامها في تنسيق القاموس ، يرجى كتابتها بنفسك.
userDefinedFile.json
{"雷姆":["小老婆"],
"艾蜜莉亞":["大老婆"],
"初音未來": ["初音", "只是個軟體"],
"李敏鎬": ["全民歐巴", "歐巴"]}
Runarticut.py
from ArticutAPI import Articut
from pprint import pprint
articut = Articut()
userDefined = "./UserDefinedFile.json"
inputSTR = "我的最愛是小老婆,不是初音未來。"
# 使用自定義詞典
resultDICT = articut.parse(inputSTR, userDefinedDictFILE=userDefined)
pprint(resultDICT)
# 未使用自定義詞典
resultDICT = articut.parse(inputSTR)
pprint(resultDICT)
# 使用自定義詞典
{"result_pos": ["<ENTITY_pronoun>我</ENTITY_pronoun><FUNC_inner>的</FUNC_inner><ACTION_verb>最愛</ACTION_verb><AUX>是</AUX><UserDefined>小老婆</UserDefined>",
",",
"<FUNC_negation>不</FUNC_negation><AUX>是</AUX><UserDefined>初音未來</UserDefined>",
"。"],
"result_segmentation": "我/的/最愛/是/小老婆/,/不/是/初音未來/。/",...}
# 未使用自定義詞典
{"result_pos": ["<ENTITY_pronoun>我</ENTITY_pronoun><FUNC_inner>的</FUNC_inner><ACTION_verb>最愛</ACTION_verb><AUX>是</AUX><ENTITY_nouny>小老婆</ENTITY_nouny>",
",",
"<FUNC_negation>不</FUNC_negation><AUX>是</AUX><ENTITY_nouny>初音</ENTITY_nouny><TIME_justtime>未來</TIME_justtime>",
"。"],
"result_segmentation": "我/的/最愛/是/小老婆/,/不/是/初音/未來/。/",...}
تحتوي منصة الحكومة المفتوحة على "مكتب السياحة في وزارة النقل يجمع المعلومات السياحية المكانية التي أصدرتها العديد من الوكالات الحكومية". يمكن أن تستخدم المقالة المعلومات الموجودة فيه وتمييزها على أنها <Crethion_Place>
تحميل المحتوى (تنسيق JSON)
{
"username": "[email protected]",
"api_key": "anapikeyfordocthatdoesnwork@all",
"input_str": "花蓮的原野牧場有一間餐廳",
"version": "v137",
"level": "lv1",
"opendata_place": true
}
إرجاع محتوى (تنسيق JSON)
{
"exec_time": 0.013453006744384766,
"level": "lv1",
"msg": "Success!",
"result_pos": ["<LOCATION>花蓮</LOCATION><FUNC_inner>的</FUNC_inner><KNOWLEDGE_place>原野牧場</KNOWLEDGE_place><ACTION_verb>有</ACTION_verb><ENTITY_classifier>一間</ENTITY_classifier><ENTITY_noun>餐廳</ENTITY_noun>"],
"result_segmentation": "花蓮/的/原野牧場/有/一間/餐廳/",
"status": True,
"version": "v137",
"word_count_balance": 99987
}
مثال على الاستخدام: https://github.com/droidtown/articutapi/blob/master/articutapi.py#l624
ورقة الخوارزمية: Textrank: إحضار النظام إلى نصوص
مثال على الاستخدام: https://github.com/droidtown/articutapi/blob/master/articutapi.py#l629
المتطلبات البيئية
Python 3.6.1
$ pip install graphene
$ pip install starlette
$ pip install jinja2
$ pip install uvicorn
تنفيذ articlegraphql.py لجلب مسار الأرشيف إلى نتيجة كسر كلمة articut ، وفتح المتصفح لدخول عنوان URL http://0.0.0.0:8000/
$ python ArticutGraphQL.py articutResult.json
تثبيت وحدة الجرافين
$ pip install graphene
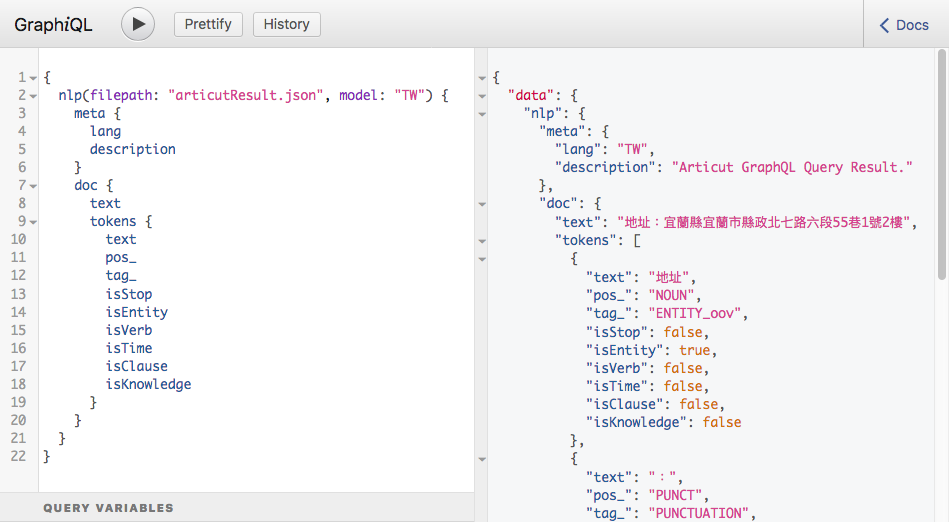
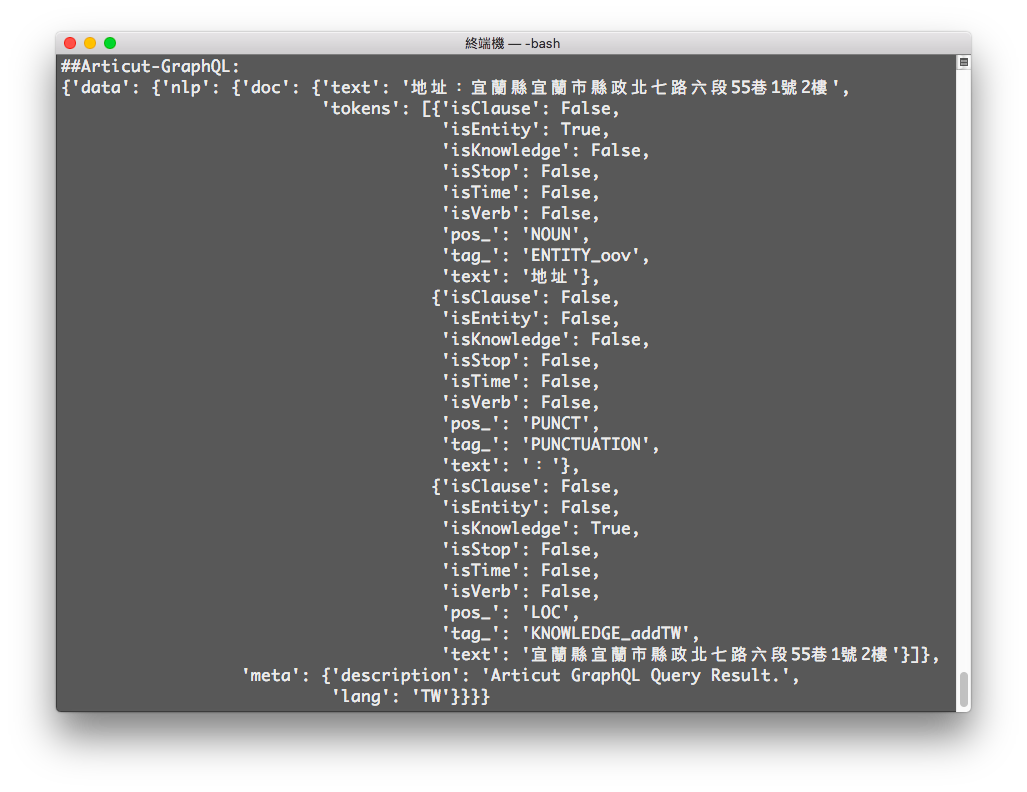
inputSTR = "地址:宜蘭縣宜蘭市縣政北七路六段55巷1號2樓"
result = articut.parse(inputSTR)
with open("articutResult.json", "w", encoding="utf-8") as resultFile:
json.dump(result, resultFile, ensure_ascii=False)
graphQLResult = articut.graphQL.query(
filePath="articutResult.json",
query="""
{
meta {
lang
description
}
doc {
text
tokens {
text
pos_
tag_
isStop
isEntity
isVerb
isTime
isClause
isKnowledge
}
}
}""")
pprint(graphQLResult)
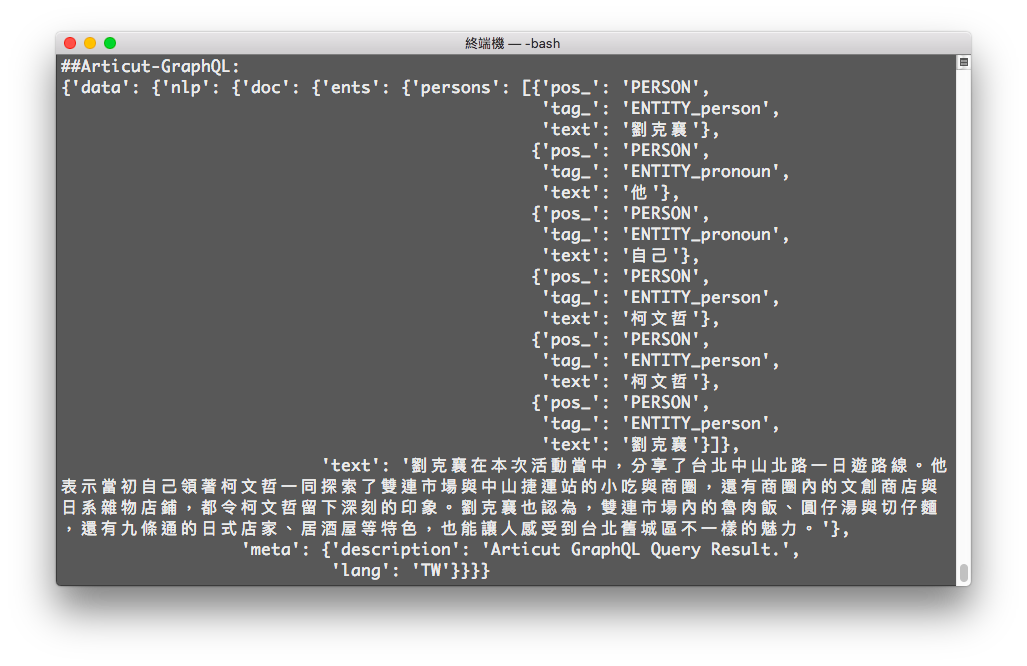
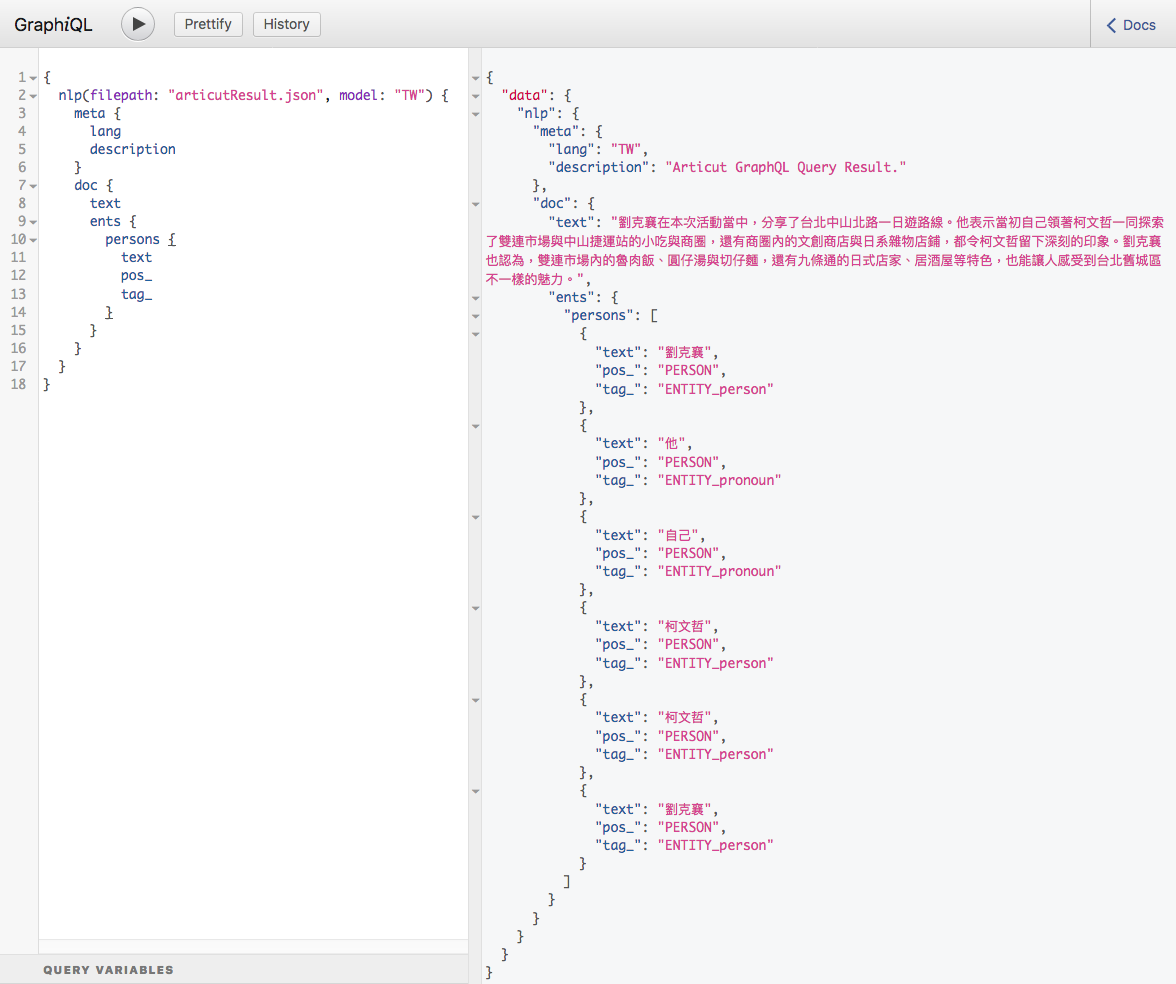
inputSTR = "劉克襄在本次活動當中,分享了台北中山北路一日遊路線。他表示當初自己領著柯文哲一同探索了雙連市場與中山捷運站的小吃與商圈,還有商圈內的文創商店與日系雜物店鋪,都令柯文哲留下深刻的印象。劉克襄也認為,雙連市場內的魯肉飯、圓仔湯與切仔麵,還有九條通的日式店家、居酒屋等特色,也能讓人感受到台北舊城區不一樣的魅力。"
result = articut.parse(inputSTR)
with open("articutResult.json", "w", encoding="utf-8") as resultFile:
json.dump(result, resultFile, ensure_ascii=False)
graphQLResult = articut.graphQL.query(
filePath="articutResult.json",
query="""
{
meta {
lang
description
}
doc {
text
ents {
persons {
text
pos_
tag_
}
}
}
}""")
pprint(graphQLResult)