AmoebaLLM
1.0.0
Yonggan Fu,Zhongzhi Yu,Junwei Li,Jiayi Qian,Yongan Zhang,Xiangchi Yuan,Dachuan Shi,Roman Yakunin和Yingyan(Celine)Lin
在神經2024年接受[紙張|滑動]。
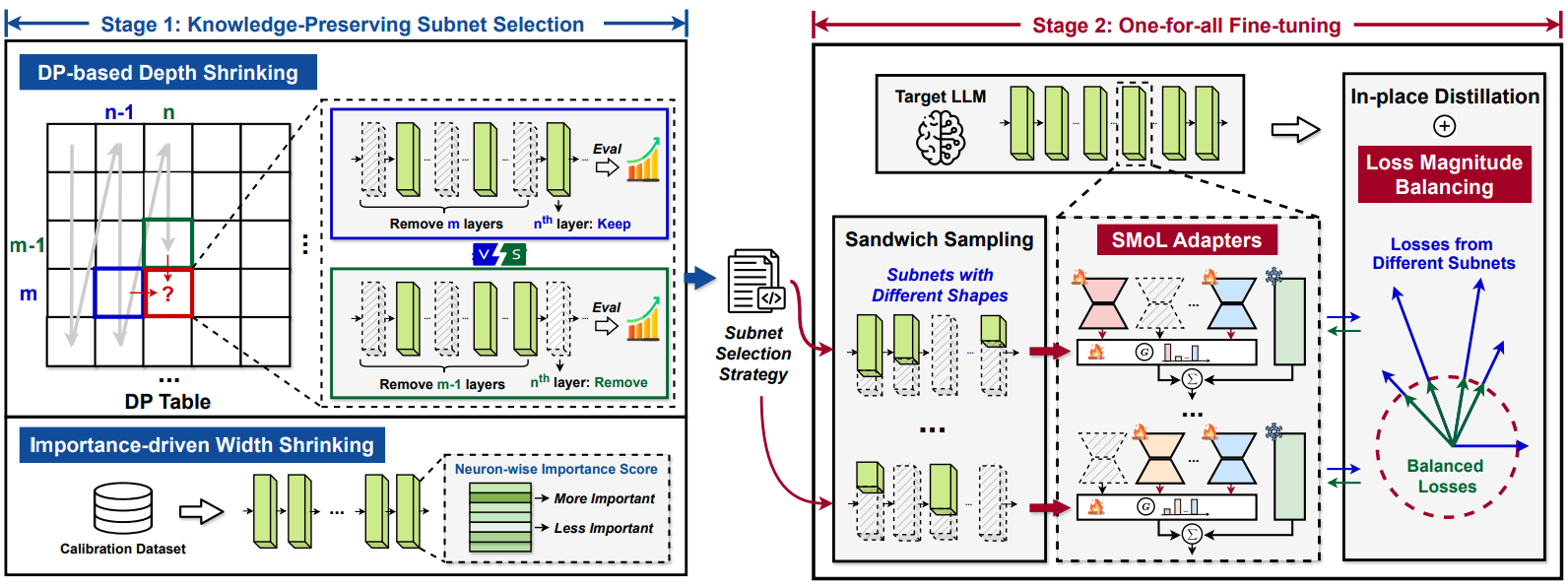
使用Conda基於提供的env.yml :
conda env create -f env.yml
CUDA_VISIBLE_DEVICES=0 python main.py --model_name_or_path meta-llama/Llama-2-7b-hf --fp16 --output_dir ./output/calib_dp --do_train False --do_eval False --no_eval_orig --layer_calib_dp --calib_dataset mmlu --enable_shrinking --num_calib_sample 40 --calib_metric acc --min_num_layer 20 --dp_keep_last_layer 1
CUDA_VISIBLE_DEVICES=0 python main.py --model_name_or_path meta-llama/Llama-2-7b-hf --fp16 --output_dir ./output/width_calib --do_train False --do_eval False --use_auth_token --no_eval_orig --width_calib --num_calib_sample 512 --prune_width_method flap
dp_selection_strategy.npy (我們還為repo中的llama2-7b提供了此文件): python utils/merge_depth_width.py
--do_train True和--enable_shrinking啟用一對全部的微調,並指定階段1提供的子集選擇策略,with- --shrinking_file dp_selection_strategy.npy : CUDA_VISIBLE_DEVICES=0 python main.py --model_name_or_path meta-llama/Llama-2-7b-hf --output_dir ./output/ft --dataset alpaca-gpt4 --use_auth_token --do_train True --do_eval True --do_mmlu_eval True --do_eval_wikitext2 True --lora_modules all --fp16 --source_max_len 384 --target_max_len 128 --gradient_accumulation_steps 4 --logging_steps 10 --max_steps 10000 --save_strategy steps --data_seed 42 --save_steps 1000 --save_total_limit 1 --evaluation_strategy steps --eval_dataset_size 1024 --max_eval_samples 1000 --eval_steps 1000 --optim paged_adamw_32bit --ddp_find_unused_parameters --enable_shrinking --kd_weight 1 --min_num_layer 20 --random_sample_num_layer 2 --distill_method sp --shrinking_method calib_dp --shrinking_file dp_selection_strategy.npy --shrinkable_width --width_choice [1,7/8,3/4,5/8] --prune_width_method flap --use_moe_lora --moe_num_expert 5 --moe_topk 2
amoeba_llama2 。您可以使用以下命令下載並解壓縮: pip install gdown
gdown 1lwOiQa-UOYOXn72wo5gvzUvFat_PTg6b
unzip amoeba_llama2.zip
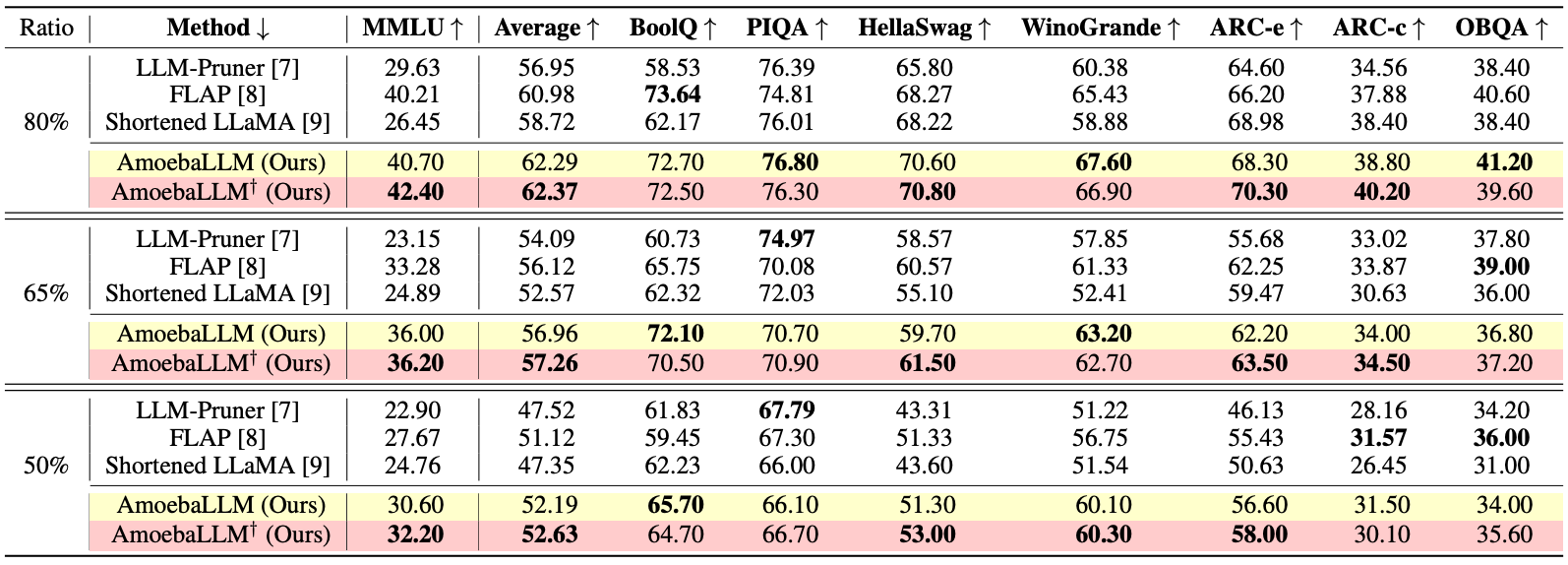
--output_dir作為微型模型的路徑,並分別使用--eval_num_layer和--eval_num_width指定目標深度和寬度比: CUDA_VISIBLE_DEVICES=0 python main.py --model_name_or_path meta-llama/Llama-2-7b-hf --output_dir amoeba_llama2 --do_train False --do_eval True --do_mmlu_eval True --bits 8 --bf16 --enable_shrinking --min_num_layer 20 --shrinking_method calib_dp --shrinking_file dp_selection_strategy.npy --shrinkable_width --width_choice [1,7/8,3/4,5/8] --prune_width_method flap --use_moe_lora --moe_num_expert 5 --moe_topk 2 --eval_num_layer 24 --eval_num_width 0.875 --do_lm_eval True --do_lm_eval_task arc_easy,piqa,hellaswag
我們指的是Qlora中的實現。
@inproceedings{fuamoeballm,
title={AmoebaLLM: Constructing Any-Shape Large Language Models for Efficient and Instant Deployment},
author={Fu, Yonggan and Yu, Zhongzhi and Li, Junwei and Qian, Jiayi and Zhang, Yongan and Yuan, Xiangchi and Shi, Dachuan and Yakunin, Roman and Lin, Yingyan Celine},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems}
}


