PDF問答系統使用檢索型發電(RAG)
該項目是一個複雜的提問系統,旨在從PDF文檔中提取和提供上下文感知的答案。通過集成高級檢索功能的生成(RAG)技術和最先進的AI模型,該系統使用戶能夠以更有效,更聰明的方式與其文檔進行交互。
用例
- 學術研究:快速從研究論文,報告或研究中提取見解。
- 專業分析:輕鬆瀏覽冗長的合同,白皮書或手冊。
- 日常使用:簡化與密集或複雜的PDF文檔的交互。
關鍵功能
- PDF處理:上傳和處理PDF文檔以進行分析。
- 交互式問答:輸入自然語言問題,並根據文檔內容獲得精確的答案。
- 高級檢索:使用基於矢量的索引和相似性評分進行準確的內容檢索。
- 用戶友好的接口:具有簡化的Web應用程序可確保易用性和可訪問性。
使用的技術
前端:簡化後端:python機器學習:用於文檔矢量儲藏室的擁抱面變壓器用於文檔索引索引自定義獵犬和後處理器,以提高準確性
安裝和設置
- 克隆存儲庫:
git clone https://github.com/your-repo-name.git
cd your-repo-name
- 運行應用程序:啟動簡化應用程序:
上傳PDF並開始查詢
- 通過應用程序接口上傳所需的PDF文件。
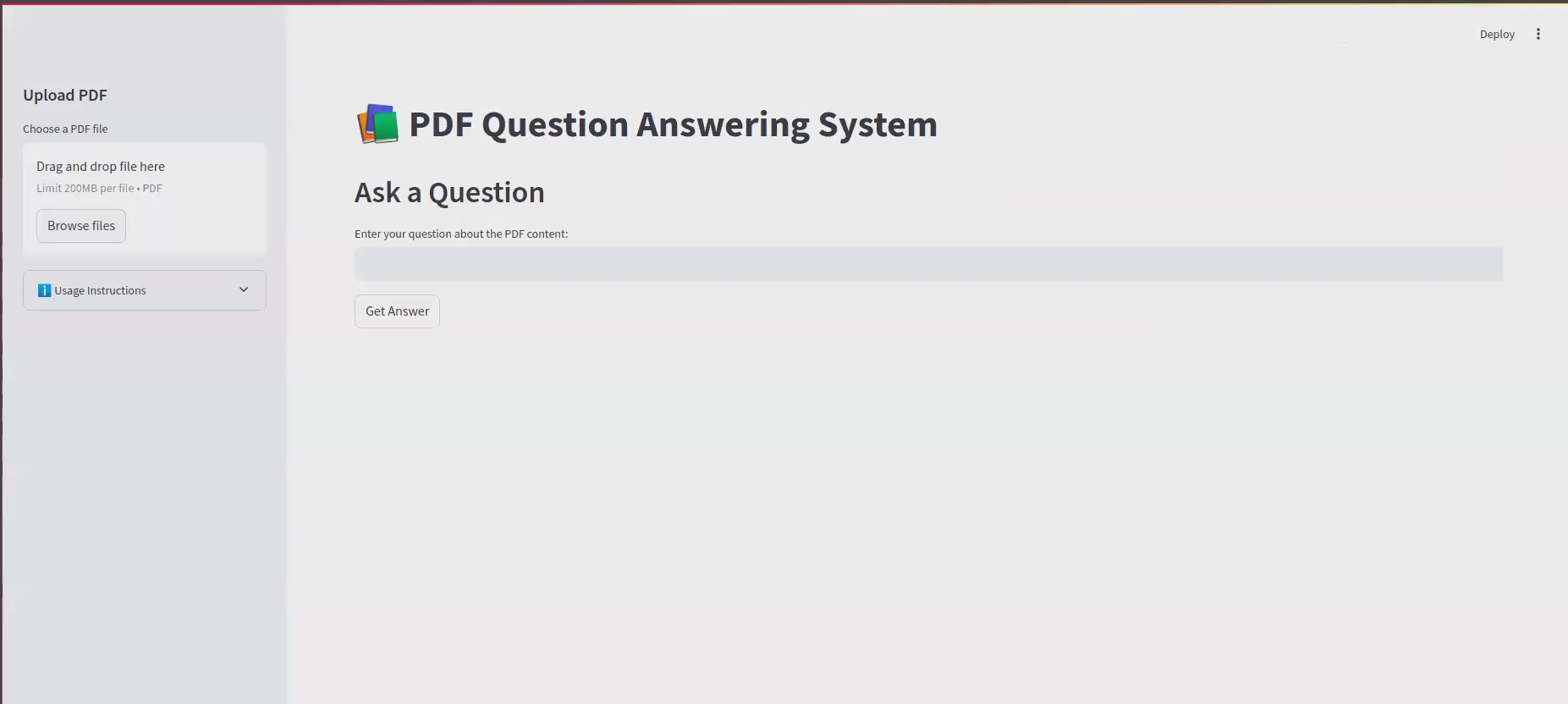
- 輸入問題並檢索上下文準確的響應。
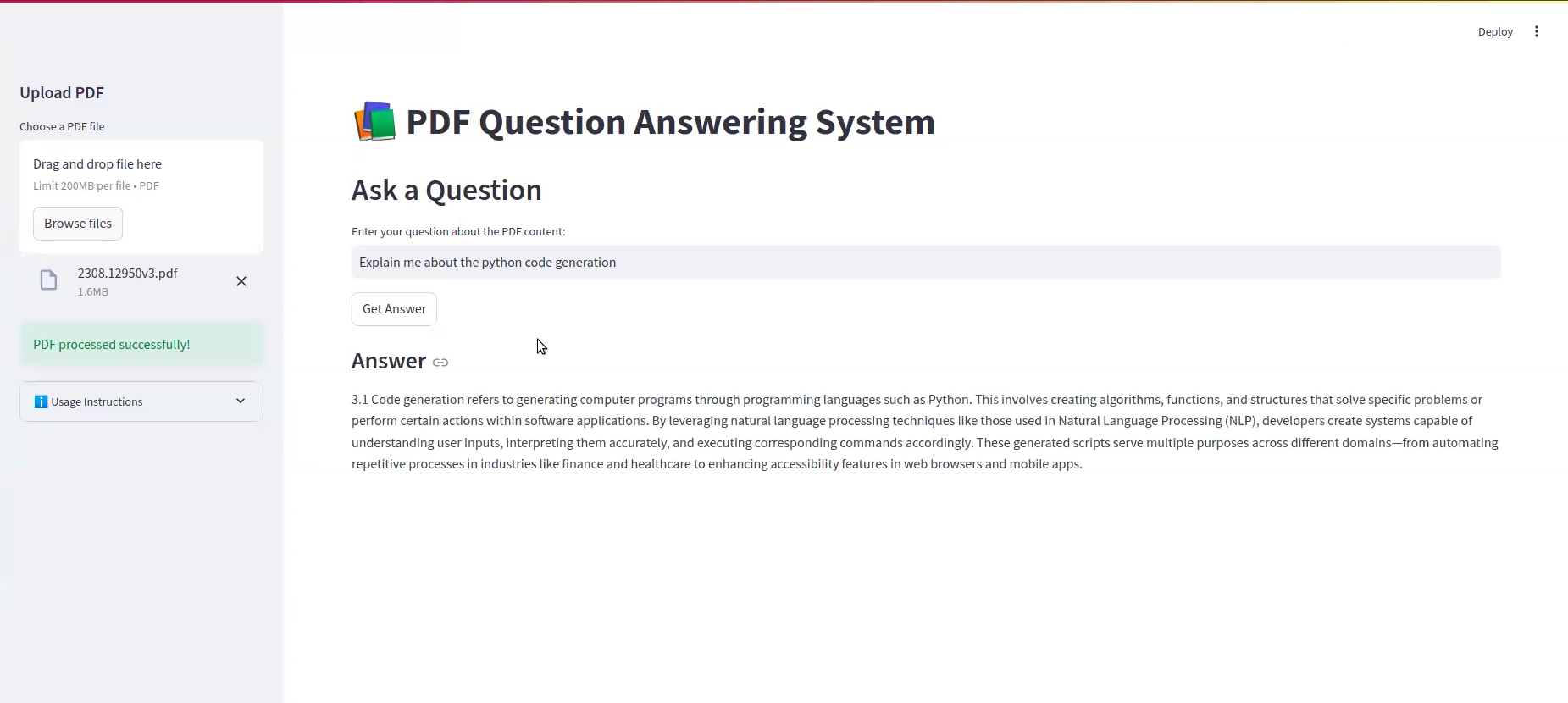
它如何工作
PDF處理:
- 該系統讀取並處理上傳的PDF,將其分成可管理的塊以進行索引。
信息檢索:
答案生成:
- 預先訓練的語言模型基於檢索的內容生成上下文感知和簡潔的響應。
技術堆棧
- 前端:簡化交互式和直觀的用戶體驗。
- 後端:
- 擁抱面變壓器,用於自然語言理解和產生。
- 使用自定義嵌入的基於向量的檢索。
- 編程語言:Python。
代碼概述
app.py
- 提供用戶界面的簡化應用程序。
- 處理PDF上傳,問題輸入並顯示答案。
rag.py
- 實現核心抹布邏輯:
- PDF處理:讀取並將PDF分為可管理的塊。
- 索引:為有效內容檢索創建一個向量索引。
- 查詢引擎:使用獵犬和後處理器回答查詢。
- 響應生成:使用變壓器模型生成詳細的響應。
使用說明
- 上傳PDF文件。
- 等待系統處理文檔。
- 輸入您的問題,然後單擊“獲取答案”。
- 查看系統生成的答案。
未來的增強
- 多文件支持:啟用多個PDF文件的查詢。
- 多語言支持:添加對多種語言處理文檔的支持。
- GPU支持:實施GPU加速度以進行更快的處理和響應時間。
- 其他格式:將支持擴展到其他文檔格式,例如DOCX和TXT。
- 增強UI :通過高級分析和可視化功能改善用戶界面。
貢獻
我們歡迎社區的貢獻。貢獻:
- 分叉存儲庫。
- 創建一個功能分支。
- 提交詳細說明您的貢獻的拉請請求。
對於任何問題或建議,請在存儲庫上開設討論或問題。
執照
該項目已根據MIT許可獲得許可。隨意使用,修改和分配其符合許可條款。
接觸
有關查詢或更多信息,請通過存儲庫問題跟踪器或電子郵件(如果適用)聯繫。


