نظام الإجابة على أسئلة PDF باستخدام الجيل المسبق للاسترجاع (خرقة)
هذا المشروع هو نظام متطور لإجازة الأسئلة مصمم لاستخراج وتوفير إجابات مدركة للسياق من مستندات PDF. من خلال دمج تقنيات التوليد المتقدم (RAG) المتقدم (RAG) ونماذج AI الحديثة ، يمكّن النظام المستخدمين من التفاعل مع مستنداتهم بطريقة أكثر كفاءة وذكية.
استخدام الحالات
- البحوث الأكاديمية : استخرج بسرعة رؤى من الأوراق البحثي أو التقارير أو الدراسات.
- التحليل المهني : التنقل في العقود الطويلة أو البيضاء أو الكتيبات بسهولة.
- الاستخدام اليومي : تبسيط التفاعلات مع وثائق PDF كثيفة أو معقدة.
الميزات الرئيسية
- معالجة PDF : تحميل ومعالجة مستندات PDF للتحليل.
- سؤال وجواب تفاعلي : أدخل أسئلة اللغة الطبيعية واستقبل إجابات دقيقة بناءً على محتوى المستند.
- الاسترجاع المتقدم : يستخدم الفهرسة المستندة إلى المتجه وتسجيل التشابه لاسترجاع المحتوى الدقيق.
- واجهة سهلة الاستخدام : يضمن تطبيق الويب المصمم باستخدام SPEREMLIT سهولة الاستخدام وسهولة الوصول.
التقنيات المستخدمة
الواجهة الأمامية: الواجهة الخلفية: Python Machine Learning: Huggingface Transformers لتوليد النص VectorStoreEx لفهرسة المستندات المخصصة و Postprocessor لتحسين الدقة
التثبيت والإعداد
- استنساخ المستودع :
git clone https://github.com/your-repo-name.git
cd your-repo-name
- قم بتشغيل التطبيق: ابدأ تطبيق SPEREMLIT:
قم بتحميل ملف PDF وابدأ في الاستعلام
- قم بتحميل ملف PDF المطلوب من خلال واجهة التطبيق.
- أدخل الأسئلة واسترداد الردود الدقيقة في السياق.
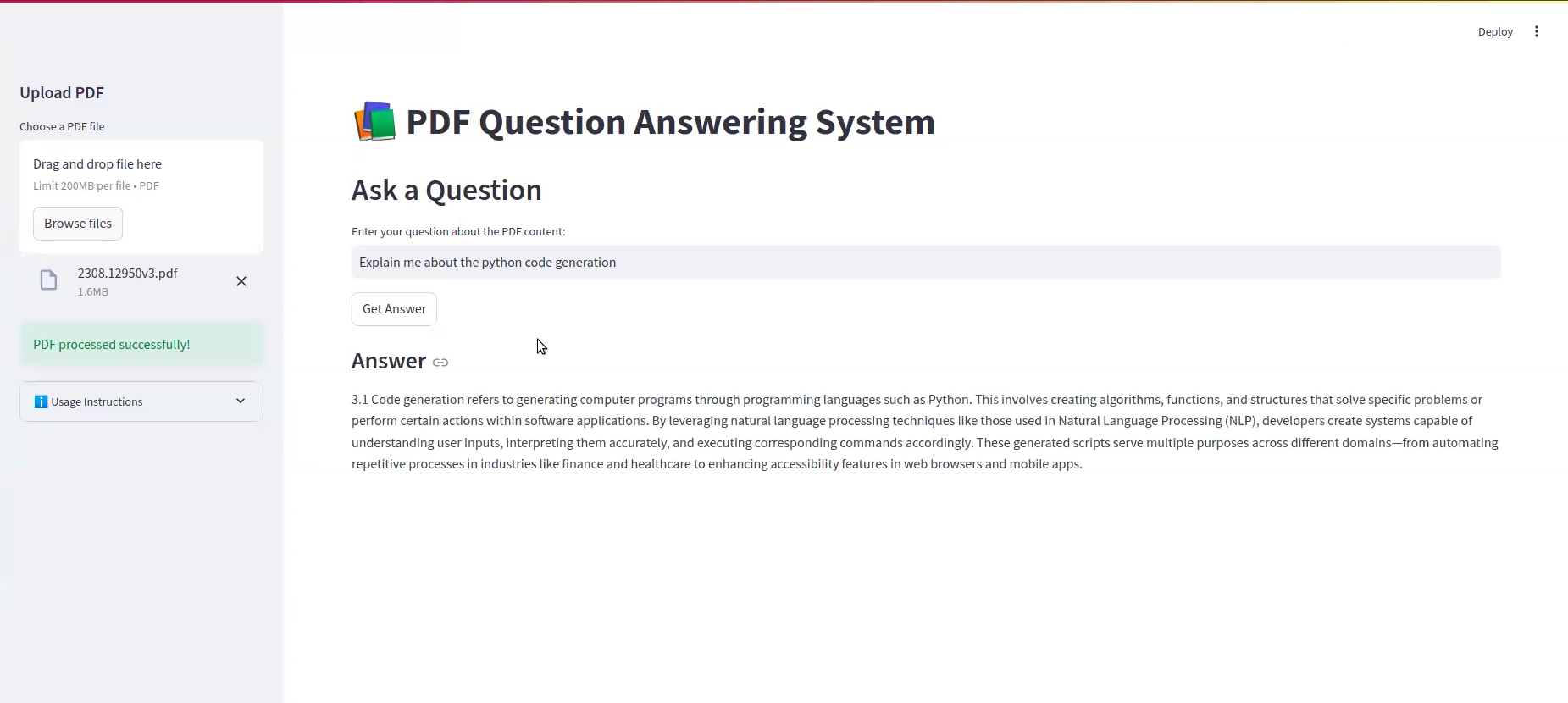
كيف تعمل
معالجة PDF :
- يقرأ النظام ويعالج PDF المحمّل ، وتقسيمه إلى قطع يمكن التحكم فيها للفهرسة.
استرجاع المعلومات :
- يتم استرداد المحتوى المفهرس باستخدام التضمين المتقدمة وتسجيل التشابه.
توليد الجواب :
- يولد نموذج اللغة المدربة مسبقًا ردود على السياق والموجز بناءً على المحتوى الذي تم استرداده.
كومة التكنولوجيا
- الواجهة الأمامية : التدفق لتجربة مستخدم تفاعلية وبديهية.
- الخلفية :
- محولات Huggingface لفهم اللغة الطبيعية وتوليدها.
- الاسترجاع القائم على المتجه باستخدام التضمينات المخصصة.
- لغة البرمجة : بيثون.
نظرة عامة على الرمز
app.py
- تطبيق بديل يوفر واجهة المستخدم.
- يتعامل مع تحميلات PDF ، ومدخلات الأسئلة ، ويعرض الإجابات.
rag.py
- ينفذ منطق الخرقة الأساسية:
- معالجة PDF : تقرأ وتقسيم PDF إلى قطع يمكن التحكم فيها.
- الفهرسة : إنشاء فهرس متجه لاسترجاع المحتوى الفعال.
- محرك الاستعلام : يستخدم مسترد و Postprocessor للإجابة على الاستعلامات.
- توليد الاستجابة : يولد استجابات مفصلة باستخدام نموذج محول.
تعليمات الاستخدام
- تحميل ملف PDF.
- انتظر النظام لمعالجة المستند.
- اكتب سؤالك وانقر فوق "Get Asse".
- عرض الإجابة التي تم إنشاؤها بواسطة النظام.
التحسينات المستقبلية
- دعم متعدد الوصول : تمكين الاستعلام عبر ملفات PDF متعددة.
- دعم متعدد اللغات : أضف دعمًا لمعالجة المستندات بلغات متعددة.
- دعم GPU : تنفيذ تسريع GPU لأوقات المعالجة والاستجابة بشكل أسرع.
- تنسيقات إضافية : توسيع الدعم لتنسيقات المستندات الأخرى مثل DOCX و TXT.
- واجهة المستخدم المحسّنة : تحسين واجهة المستخدم مع ميزات التحليلات المتقدمة وميزات التصور.
المساهمة
نرحب بالمساهمات من المجتمع. للمساهمة:
- شوكة المستودع.
- إنشاء فرع ميزة.
- إرسال طلب سحب يوضح تفاصيل مساهمتك.
لأي قضايا أو اقتراحات ، يرجى فتح مناقشة أو إصدار على المستودع.
رخصة
هذا المشروع مرخص بموجب ترخيص معهد ماساتشوستس للتكنولوجيا. لا تتردد في استخدامها وتعديلها وتوزيعها وفقًا لشروط الترخيص.
اتصال
للاستفسارات أو مزيد من المعلومات ، يرجى الاتصال عبر تعقب مشكلة المستودع أو البريد الإلكتروني (إن أمكن).


