Deep RL Keras
1.0.0
在Keras中流行的深鋼筋學習算法的模塊化實施:
此實施需要Keras 2.1.6以及OpenAI健身房。
$ pip install gym keras==2.1.6參與者 - 批評算法是一種無模型的非政策方法,批評家充當價值功能近似器,而演員則作為政策功能近似概述。在訓練時,評論家預測了TD-Error,並指導自己和演員的學習。在實踐中,我們使用優勢函數近似TD-Error。為了提高穩定性,我們在兩個網絡上使用共享的計算骨幹,以及折扣獎勵的N-Step公式。我們還納入了一個熵正規化術語(“軟”學習),以鼓勵探索。雖然A2C簡單有效,但由於較長的計算時間,在Atari遊戲上運行它很快就變得棘手。
以與A2C算法相似的方式,A3C的實現結合了異步重量更新,可以更快地計算。我們使用多種代理在多個線程上進行梯度上升的梯度上升。我們在Atari突破環境上測試A3C。
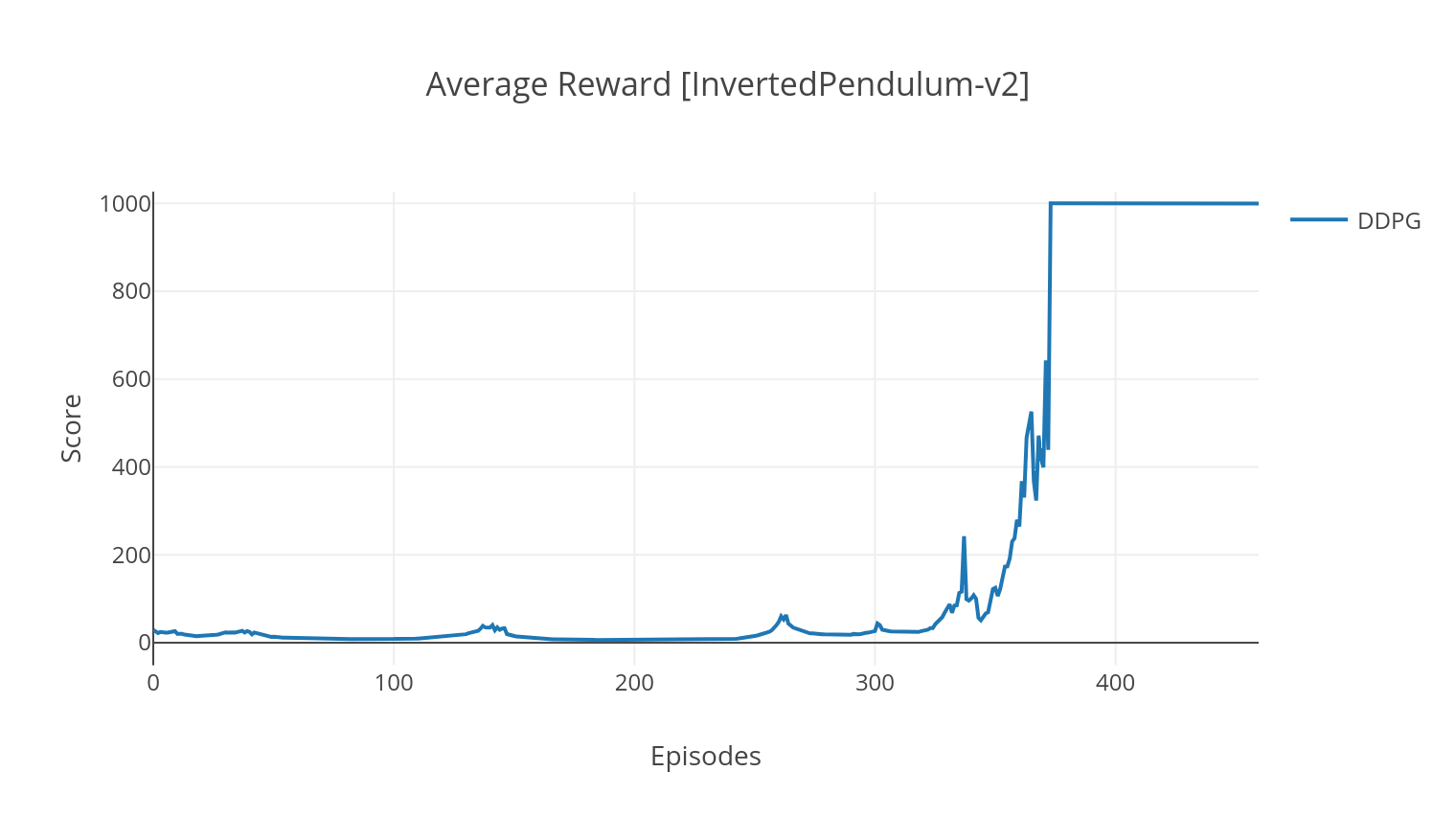
DDPG算法是一種無模型的非元素算法,用於連續作用空間。與A2C類似,它是一種參與者批評算法,其中演員接受了確定性目標政策的培訓,評論家預測了Q值。為了降低差異並提高穩定性,我們使用經驗重播和單獨的目標網絡。此外,正如Openai所暗示的那樣,我們通過參數空間噪聲(而不是傳統的動作空間噪聲)來鼓勵探索。我們在Lunar Lander環境上測試DDPG。
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2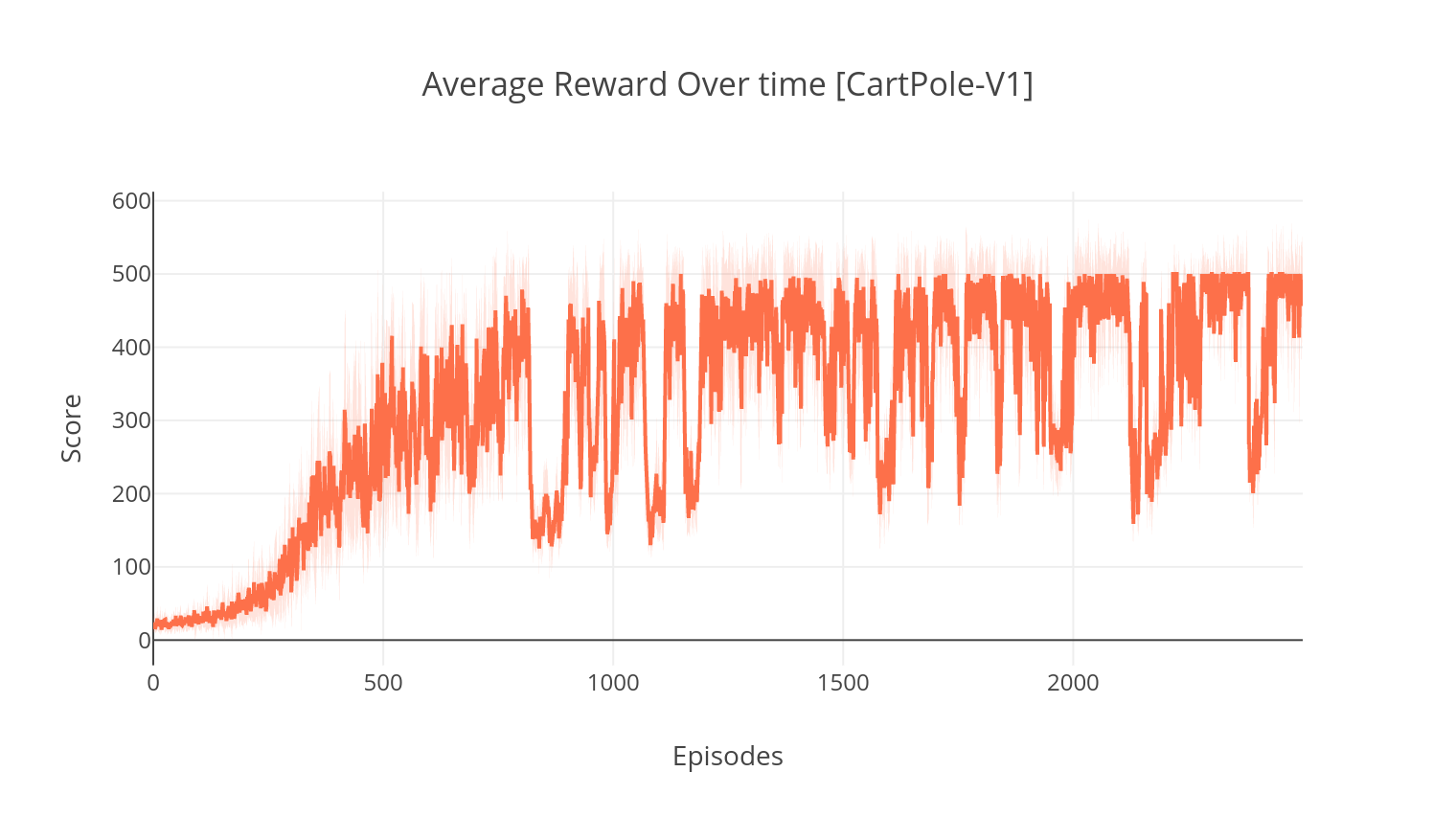
DQN算法是一種Q學習算法,它使用深神網絡作為Q值函數近似器。我們通過利用Bellman方程來估算目標Q值,並通過Epsilon-Greedy政策獲得經驗。為了獲得更高的穩定性,我們隨機對過去的經驗進行採樣(經驗重播)。 DQN算法的變體是雙DQN(或DDQN)。為了更準確地估算我們的Q值,我們使用第二個網絡來緩解原始網絡對Q值的高估。在每個培訓步驟中,該目標網絡以較慢的速率更新。
我們可以通過添加優先的經驗重播(PER)來進一步改善DDQN算法,該重播旨在對收集的體驗進行重要的採樣。體驗由其TD誤差排名,並存儲在Sumtree結構中,該結構可以有效檢索(S,A,R,S')過渡,並具有最高的誤差。
在DQN的決鬥變體中,我們在Q-Network中合併了一個中間層,以估計狀態值和狀態依賴性優勢函數。重新制定後(請參閱參考),事實證明,我們可以將估計的Q值表示為狀態價值,我們添加了優勢估算並減去其平均值。對國家獨立和國家依賴性價值的分解有助於跨動作進行學習,並產生更好的結果。
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling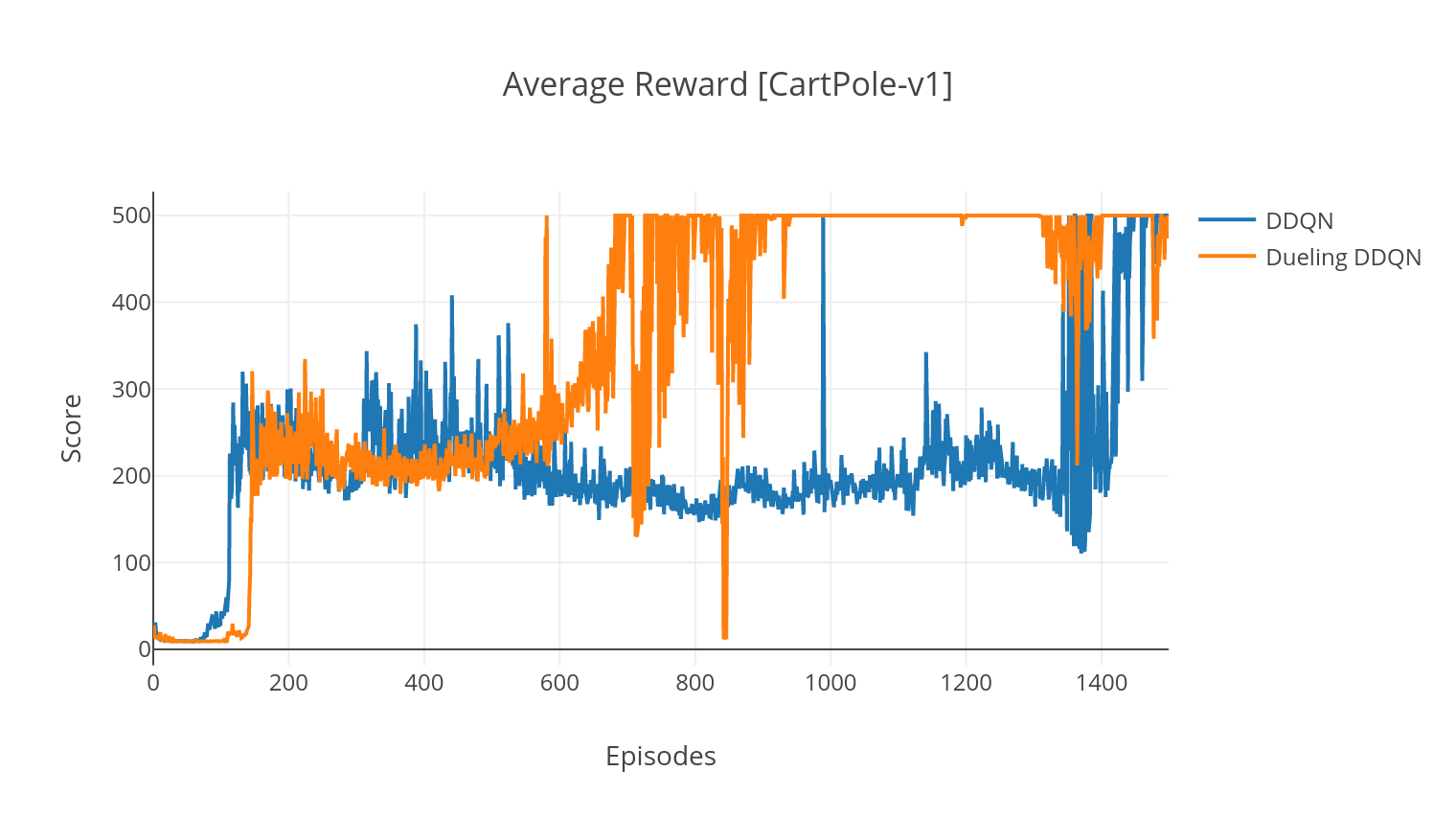
| 爭論 | 描述 | 值 |
|---|---|---|
| - 類型 | RL算法的類型運行 | 從{a2c,a3c,ddqn,ddpg}中選擇 |
| - env | 指定環境 | BreakoutNofRamesKip-V4(默認) |
| -nb_episodes | 劇集的數量 | 5000(默認) |
| - batch_size | 批量尺寸(DDQN,DDPG) | 32(默認) |
| - consectee_frames | 堆疊的連續幀數 | 4(默認) |
| -is_atari | 環境是否是帶有像素輸入的atari遊戲 | - |
| -with_per | 是否使用優先經驗重播(使用DDQN) | - |
| - 衝突 | 是否使用決鬥網絡(與DDQN) | - |
| -n_threads | 線程數(A3C) | 16(默認) |
| -gather_stats | 是否計算10場比賽中平均得分統計數據(慢,見下文) | - |
| - 使成為 | 是否在培訓時渲染環境 | - |
| -GPU | GPU索引 | 0 |
所有型號均在完成訓練後保存在<algorithm_folder>/models/下。您可以通過運行load_and_run.py腳本在與他們接受過培訓的相同環境中可視化它們。對於DQN模型,您應該在--model_path參數中指定所需模型的路徑。對於Actor-Critic模型,您需要在--actor_path和--critic_path參數中指定權重文件。
使用Tensorboard,您可以在訓練時監視代理的分數。訓練時,將創建具有匹配所選環境的名稱的日誌文件夾。例如,要遵循Cartpole-V1上的A2C進程,只需運行:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/在使用參數訓練時--gather_stats時,將生成一個日誌文件,其中包含每個情節中10個遊戲的分數: logs.csv 。使用Plotly,您可以可視化每集的平均獎勵。為此,您首先需要安裝繪圖並獲得免費許可證。
pip3 install plotly要設置您的憑據,請運行:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )最後,要繪製結果,請運行:
python3 utils/plot_results.py < path_to_your_log_file >

