Deep RL Keras
1.0.0
Keras에서 인기있는 깊은 강화 학습 알고리즘의 모듈 식 구현 :
이 구현에는 Keras 2.1.6뿐만 아니라 Openai Gym이 필요합니다.
$ pip install gym keras==2.1.6액터-비법 알고리즘은 비평가가 값 기능 근사기 역할을하는 모델이없고 정책 오프 정책 방법이며, 법은 정책 기능 근사기 역할을합니다. 훈련 할 때, 비평가는 TD-Orror를 예측하고 그 자체와 배우의 학습을 안내합니다. 실제로, 우리는 이점 기능을 사용하여 TD-Orror와 근사합니다. 보다 안정성을 높이기 위해, 우리는 두 네트워크에서 공유 계산 백본과 할인 된 보상의 N 단계 공식을 사용합니다. 또한 탐사를 장려하기 위해 엔트로피 정규화 용어 ( "소프트"학습)를 통합합니다. A2C는 간단하고 효율적이지만 Atari 게임에서 실행하면 계산 시간이 길기 때문에 빠르게 다루기 어려워집니다.
A2C 알고리즘과 유사한 방식으로 A3C의 구현에는 비동기 무게 업데이트가 통합되어 훨씬 빠른 계산이 가능합니다. 여러 에이전트를 사용하여 여러 스레드에서 구배 상승 비동기를 수행합니다. Atari 브레이크 아웃 환경에서 A3C를 테스트합니다.
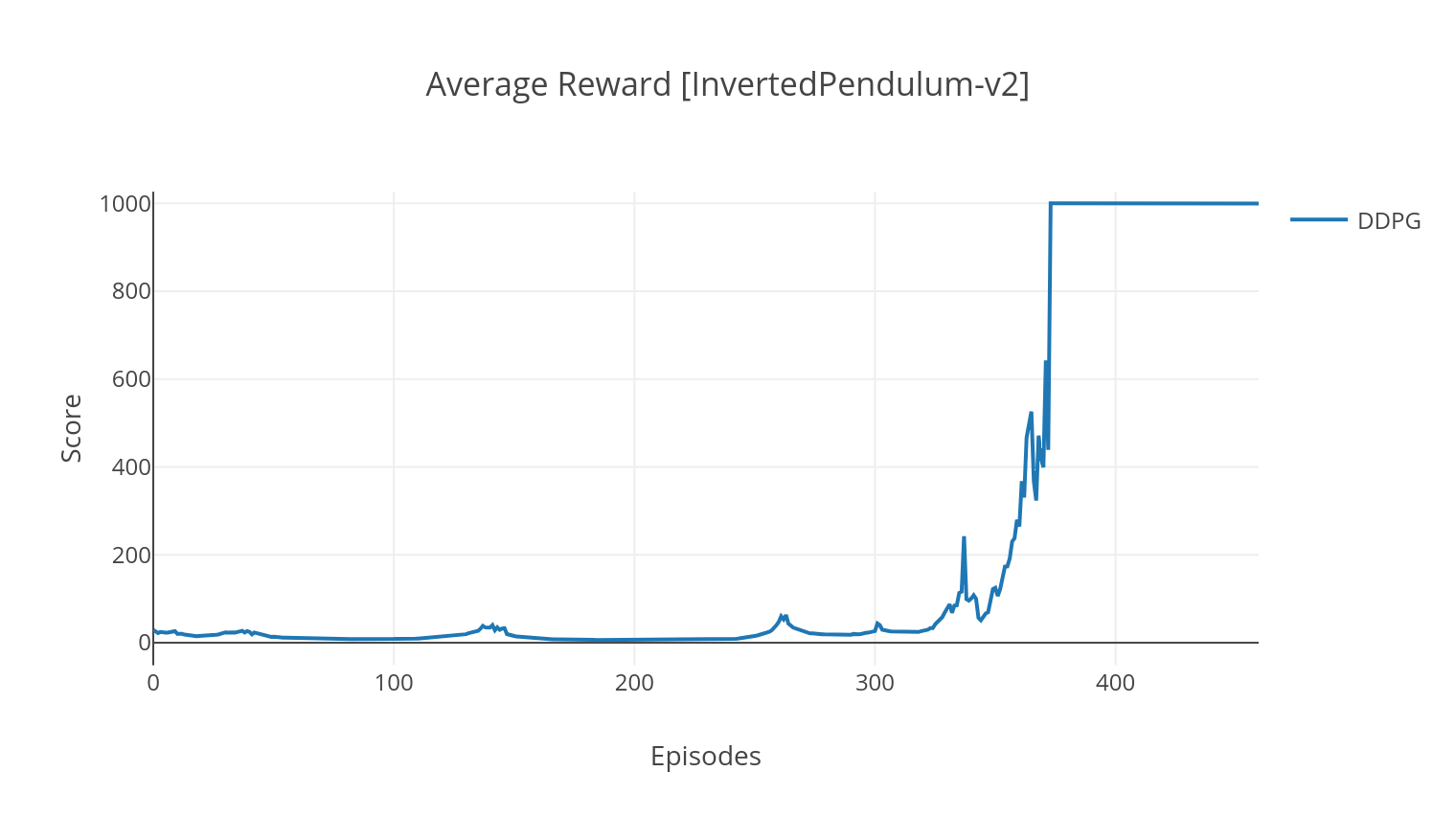
DDPG 알고리즘은 연속 동작 공간을위한 모델이없는 오프 정책 알고리즘입니다. A2C와 마찬가지로, 이는 배우가 결정적인 목표 정책에 대해 훈련을받는 액터-비판 알고리즘이며, 비평가는 Q- 값을 예측합니다. 분산을 줄이고 안정성을 높이기 위해 경험 재생 및 별도의 대상 네트워크를 사용합니다. 또한, OpenAI의 힌트를받은 바와 같이, 우리는 매개 변수 공간 노이즈 (전통적인 액션 공간 노이즈와는 반대로)를 통한 탐색을 권장합니다. 우리는 달 착륙선 환경에서 DDPG를 테스트합니다.
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2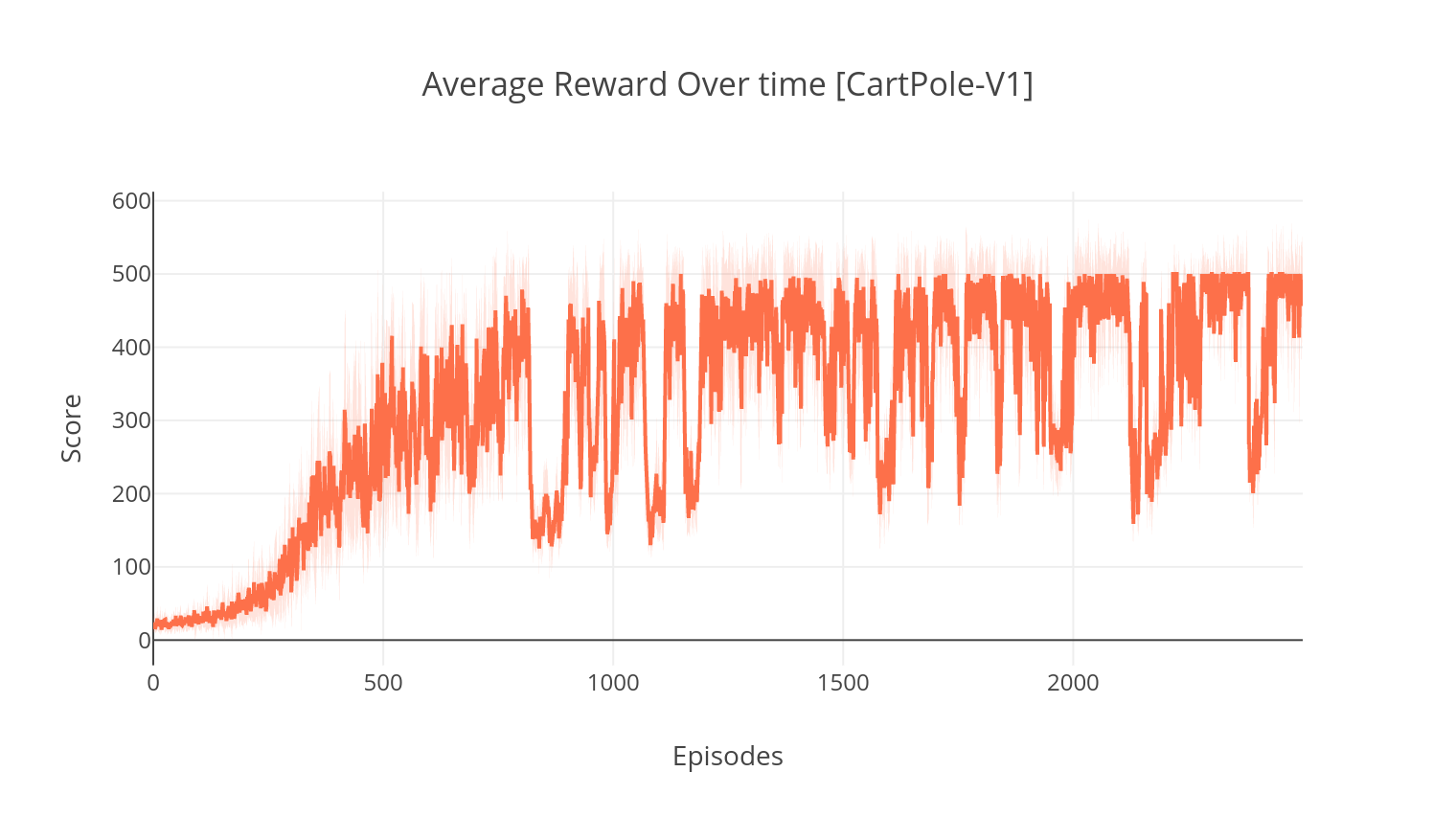
DQN 알고리즘은 Q- 학습 알고리즘으로 Q- 값 기능 근사기로 깊은 신경망을 사용합니다. 우리는 Bellman 방정식을 활용하여 대상 Q- 값을 추정하고 Epsilon-Greedy 정책을 통해 경험을 수집합니다. 더 많은 안정성을 위해, 우리는 과거 경험을 무작위로 샘플링합니다 (재생 경험). DQN 알고리즘의 변형은 Double-DQN (또는 DDQN)입니다. Q- 값을보다 정확하게 추정하기 위해 두 번째 네트워크를 사용하여 원래 네트워크에 의해 Q- 값의 과대 평가를 완화시킵니다. 이 대상 네트워크는 모든 교육 단계에서 속도가 느린 타우로 업데이트됩니다.
PER (Priorified Experience Replay)을 추가하여 DDQN 알고리즘을 더욱 향상시킬 수 있으며, 이는 수집 된 경험에 대한 중요성 샘플링을 수행하는 것을 목표로합니다. 이 경험은 TD-Orror에 의해 순위가 매겨지고 Sumtree 구조에 저장되어 가장 높은 오류로 (S, A, R, S ') 전환을 효율적으로 검색 할 수 있습니다.
DQN의 결투 변형에서, 우리는 q-network에 중간 층을 통합하여 상태 가치와 상태 의존적 이점 함수를 모두 추정합니다. 개혁 후 (참조 참조), 우리는 추정 된 Q- 값을 상태 값으로 표현할 수 있으며, 이는 이점 추정치를 추가하고 평균을 빼냅니다. 국가 독립적이고 국가 의존적 가치에 대한 이러한 인수화는 행동에 대한 학습을 분리하는 데 도움이되고 더 나은 결과를 얻는 데 도움이됩니다.
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling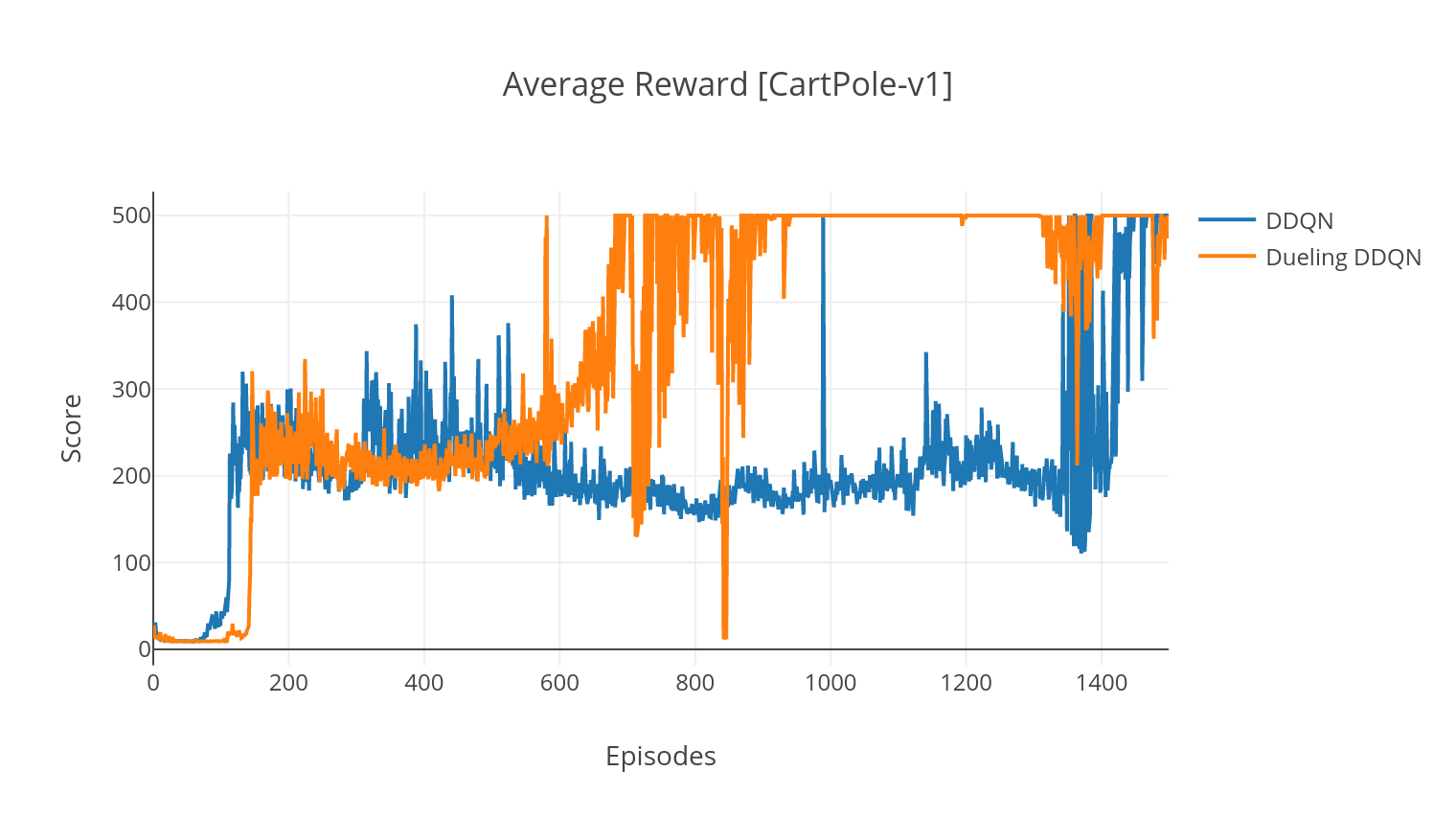
| 논쟁 | 설명 | 값 |
|---|---|---|
| --유형 | 실행할 RL 알고리즘 유형 | {a2c, a3c, ddqn, ddpg}에서 선택하십시오. |
| --env | 환경을 지정합니다 | Breakoutnoframeskip-v4 (기본값) |
| -nb_episodes | 실행할 에피소드 수 | 5000 (기본값) |
| ---batch_size | 배치 크기 (DDQN, DDPG) | 32 (기본값) |
| -Consecutive_frames | 쌓인 연속 프레임 수 | 4 (기본값) |
| --is_atari | 환경이 픽셀 입력이있는 atari 게임인지 여부 | - |
| -with_per | 우선 순위가 우선 경험 재생 (DDQN 포함)을 사용할지 여부 | - |
| -eULING | 결투 네트워크 사용 여부 (DDQN 포함) | - |
| --n_threads | 스레드 수 (A3C) | 16 (기본값) |
| -gather_stats | 점수 통계 계산 여부는 평균 10 게임에 걸쳐 평균적으로 (느리게, 아래 참조) | - |
| --세우다 | 훈련으로 환경을 렌더링할지 여부 | - |
| -gpu | GPU 지수 | 0 |
모든 모델은 <algorithm_folder>/models/ Moides에서 저장됩니다. load_and_run.py 스크립트를 실행하여 훈련 된 것과 동일한 환경에서 실행되는 시각화를 시각화 할 수 있습니다. DQN 모델의 경우 --model_path 인수에서 원하는 모델로의 경로를 지정해야합니다. Actor-Critic 모델의 경우 --actor_path 및 --critic_path 인수에 두 가중치 파일을 모두 지정해야합니다.
Tensorboard를 사용하면 에이전트의 점수를 훈련 할 때 모니터링 할 수 있습니다. 훈련 할 때 선택한 환경과 일치하는 이름이있는 로그 폴더가 생성됩니다. 예를 들어, CartPole-V1에서 A2C 진행을 따르려면 간단히 실행하십시오.
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ 인수 --gather_stats 로 훈련 할 때, 로그 파일은 모든 에피소드마다 평균 10 경기 이상의 점수가 포함되어 있습니다 : logs.csv . Plotly를 사용하면 에피소드 당 평균 보상을 시각화 할 수 있습니다. 그렇게하려면 먼저 플롯을 설치하고 무료 라이센스를 받아야합니다.
pip3 install plotly자격 증명을 설정하려면 실행하십시오.
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )마지막으로 결과를 플로팅하려면 실행하십시오.
python3 utils/plot_results.py < path_to_your_log_file >

