Deep RL Keras
1.0.0
在Keras中流行的深钢筋学习算法的模块化实施:
此实施需要Keras 2.1.6以及OpenAI健身房。
$ pip install gym keras==2.1.6参与者 - 批评算法是一种无模型的非政策方法,批评家充当价值功能近似器,而演员则作为政策功能近似概述。在训练时,评论家预测了TD-Error,并指导自己和演员的学习。在实践中,我们使用优势函数近似TD-Error。为了提高稳定性,我们在两个网络上使用共享的计算骨干,以及折扣奖励的N-Step公式。我们还纳入了一个熵正规化术语(“软”学习),以鼓励探索。虽然A2C简单有效,但由于较长的计算时间,在Atari游戏上运行它很快就变得棘手。
以与A2C算法相似的方式,A3C的实现结合了异步重量更新,可以更快地计算。我们使用多种代理在多个线程上进行梯度上升的梯度上升。我们在Atari突破环境上测试A3C。
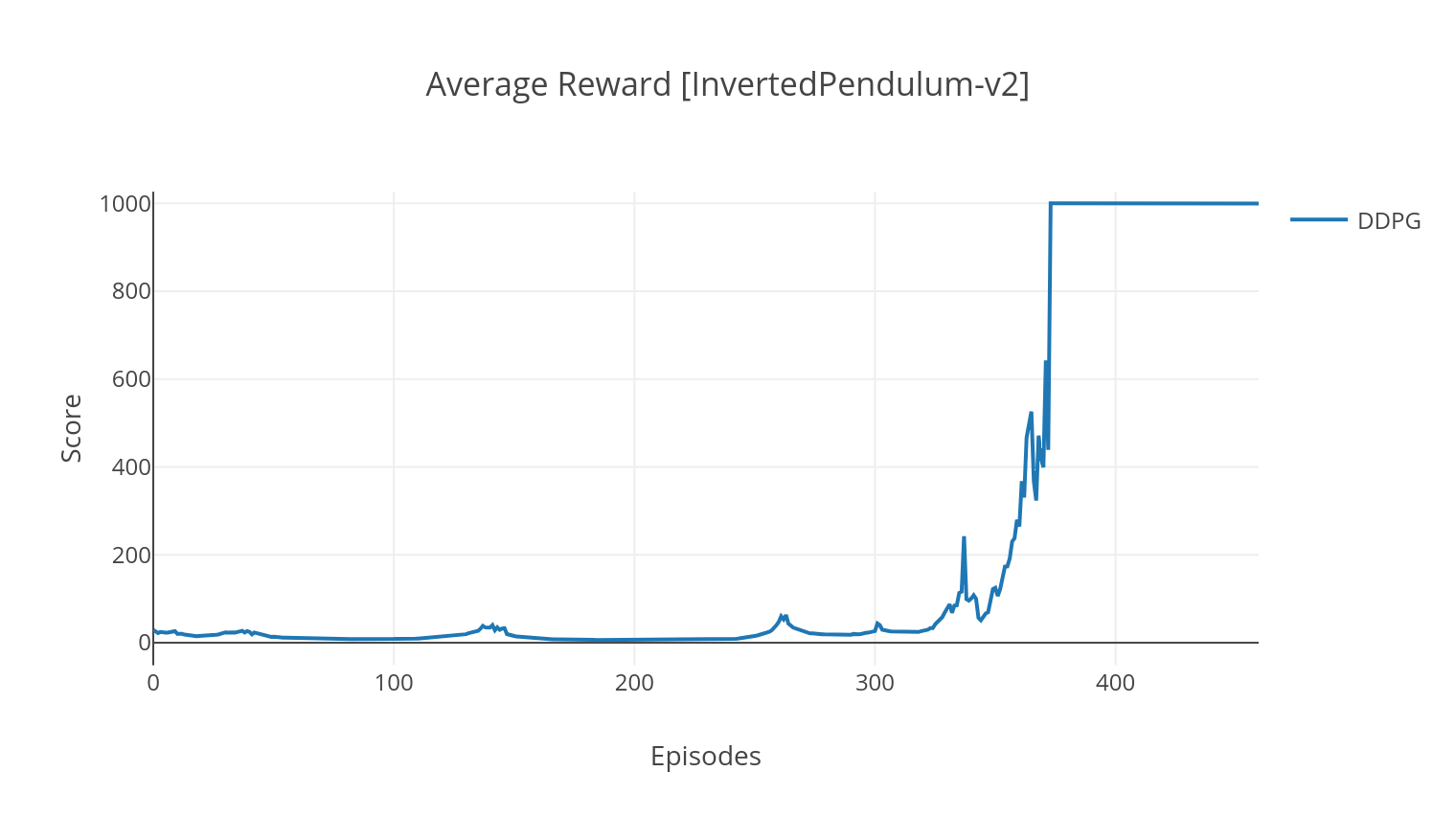
DDPG算法是一种无模型的非元素算法,用于连续作用空间。与A2C类似,它是一种参与者批评算法,其中演员接受了确定性目标政策的培训,评论家预测了Q值。为了降低差异并提高稳定性,我们使用经验重播和单独的目标网络。此外,正如Openai所暗示的那样,我们通过参数空间噪声(而不是传统的动作空间噪声)来鼓励探索。我们在Lunar Lander环境上测试DDPG。
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2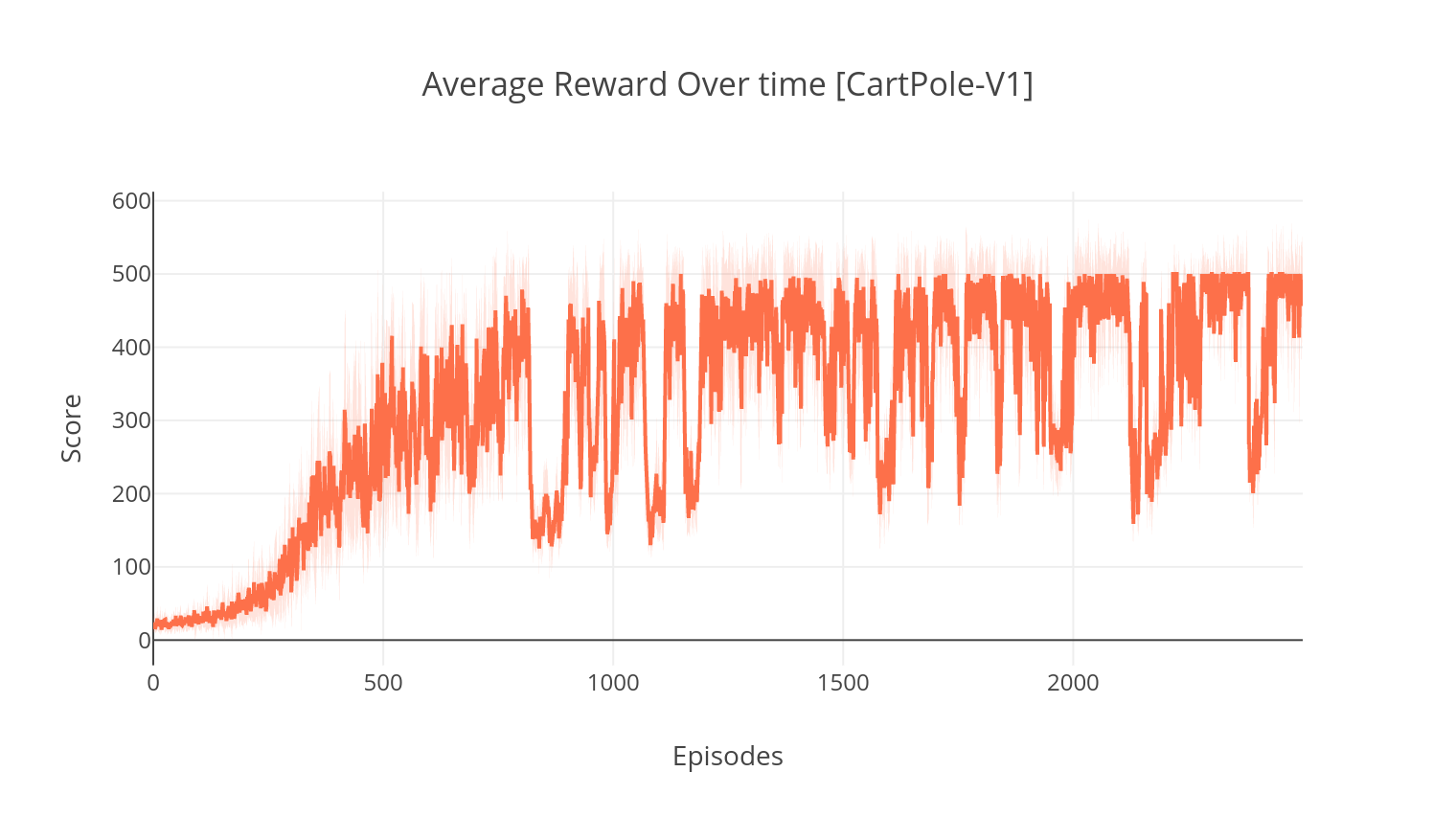
DQN算法是一种Q学习算法,它使用深神网络作为Q值函数近似器。我们通过利用Bellman方程来估算目标Q值,并通过Epsilon-Greedy政策获得经验。为了获得更高的稳定性,我们随机对过去的经验进行采样(经验重播)。 DQN算法的变体是双DQN(或DDQN)。为了更准确地估算我们的Q值,我们使用第二个网络来缓解原始网络对Q值的高估。在每个培训步骤中,该目标网络以较慢的速率更新。
我们可以通过添加优先的经验重播(PER)来进一步改善DDQN算法,该重播旨在对收集的体验进行重要的采样。体验由其TD误差排名,并存储在Sumtree结构中,该结构可以有效检索(S,A,R,S')过渡,并具有最高的误差。
在DQN的决斗变体中,我们在Q-Network中合并了一个中间层,以估计状态值和状态依赖性优势函数。重新制定后(请参阅参考),事实证明,我们可以将估计的Q值表示为状态价值,我们添加了优势估算并减去其平均值。对国家独立和国家依赖性价值的分解有助于跨动作进行学习,并产生更好的结果。
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling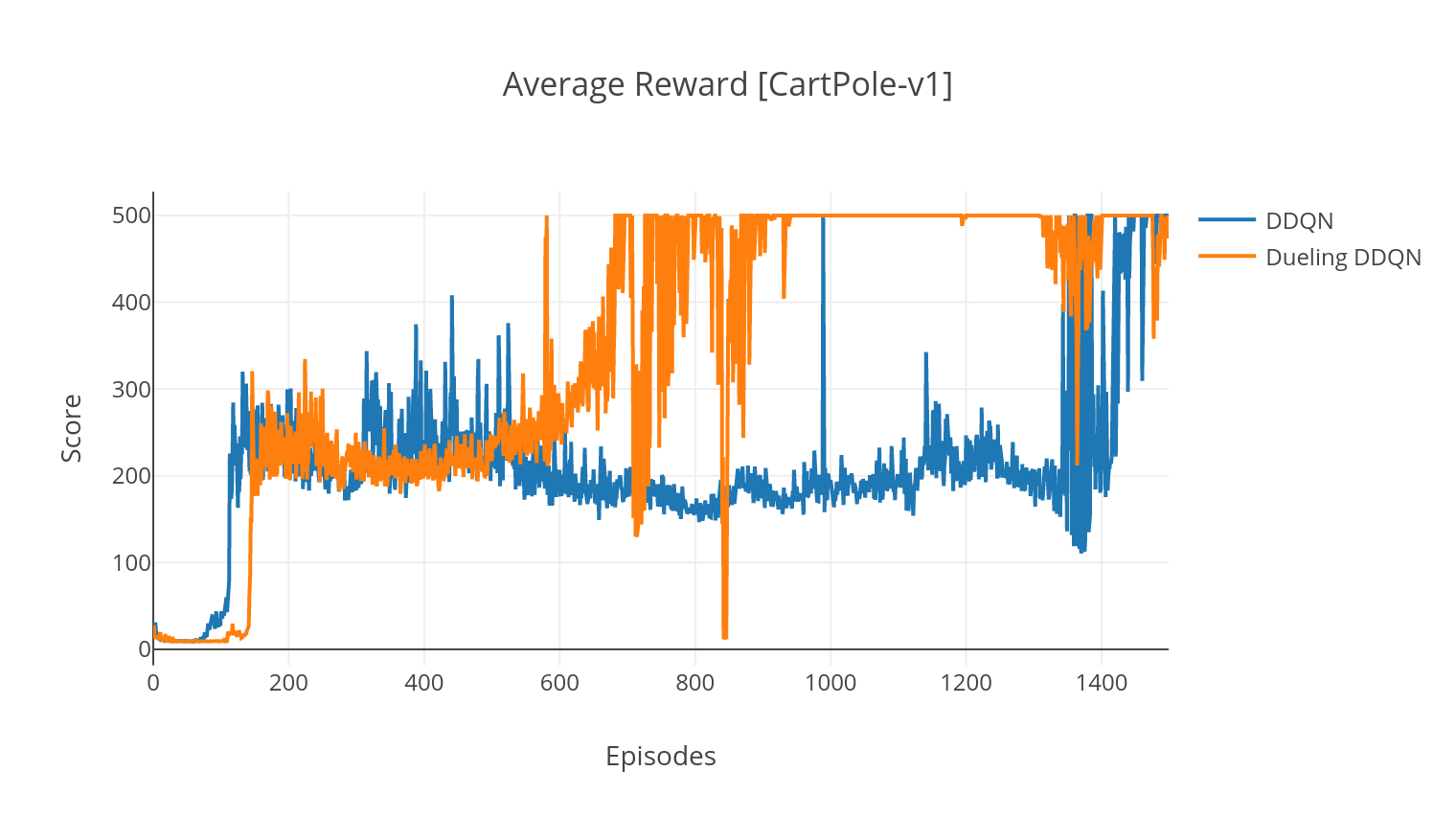
| 争论 | 描述 | 值 |
|---|---|---|
| - 类型 | RL算法的类型运行 | 从{a2c,a3c,ddqn,ddpg}中选择 |
| - env | 指定环境 | BreakoutNofRamesKip-V4(默认) |
| -nb_episodes | 剧集的数量 | 5000(默认) |
| - batch_size | 批量尺寸(DDQN,DDPG) | 32(默认) |
| - consectee_frames | 堆叠的连续帧数 | 4(默认) |
| -is_atari | 环境是否是带有像素输入的atari游戏 | - |
| -with_per | 是否使用优先经验重播(使用DDQN) | - |
| - 冲突 | 是否使用决斗网络(与DDQN) | - |
| -n_threads | 线程数(A3C) | 16(默认) |
| -gather_stats | 是否计算10场比赛中平均得分统计数据(慢,见下文) | - |
| - 使成为 | 是否在培训时渲染环境 | - |
| -GPU | GPU索引 | 0 |
所有型号均在完成训练后保存在<algorithm_folder>/models/下。您可以通过运行load_and_run.py脚本在与他们接受过培训的相同环境中可视化它们。对于DQN模型,您应该在--model_path参数中指定所需模型的路径。对于Actor-Critic模型,您需要在--actor_path和--critic_path参数中指定权重文件。
使用Tensorboard,您可以在训练时监视代理的分数。训练时,将创建具有匹配所选环境的名称的日志文件夹。例如,要遵循Cartpole-V1上的A2C进程,只需运行:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/在使用参数训练时--gather_stats时,将生成一个日志文件,其中包含每个情节中10个游戏的分数: logs.csv 。使用Plotly,您可以可视化每集的平均奖励。为此,您首先需要安装绘图并获得免费许可证。
pip3 install plotly要设置您的凭据,请运行:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )最后,要绘制结果,请运行:
python3 utils/plot_results.py < path_to_your_log_file >

