SPT
1.0.0
[ICCV 2023](口头)这是我们论文的官方存储库: Haoyu He,Jianfei Cai,Jing Zhang,Dacheng Tao和Bohan Zhuang的Haoyu He,Jianfei Cai,Jianfei Cai,Jianfei Cai和Bohan Zhuang的敏感性视觉参数的微调。
[2023-09-12]:发布代码。消息
[2023-08-12]:被ICCV 2023接受口头呈现!
我们的工作并没有在参数效率微调(PEFT)中介绍另一个具有可学习参数的体系结构,而是强调将PEFT体系结构放置在适合各种任务的最佳位置上的重要性!

我们的SPT包括两个阶段。
阶段1是一个非常快速的单发参数灵敏度估计(几秒钟),以查找在哪里引入可训练的参数。以下是具有TOP-0.4%敏感参数的各种预训练VIT中的一些有趣的灵敏度模式。我们发现,从网络深度和任务无关的类似模式方面,该比例在操作方面表现出特定于任务的不同模式。
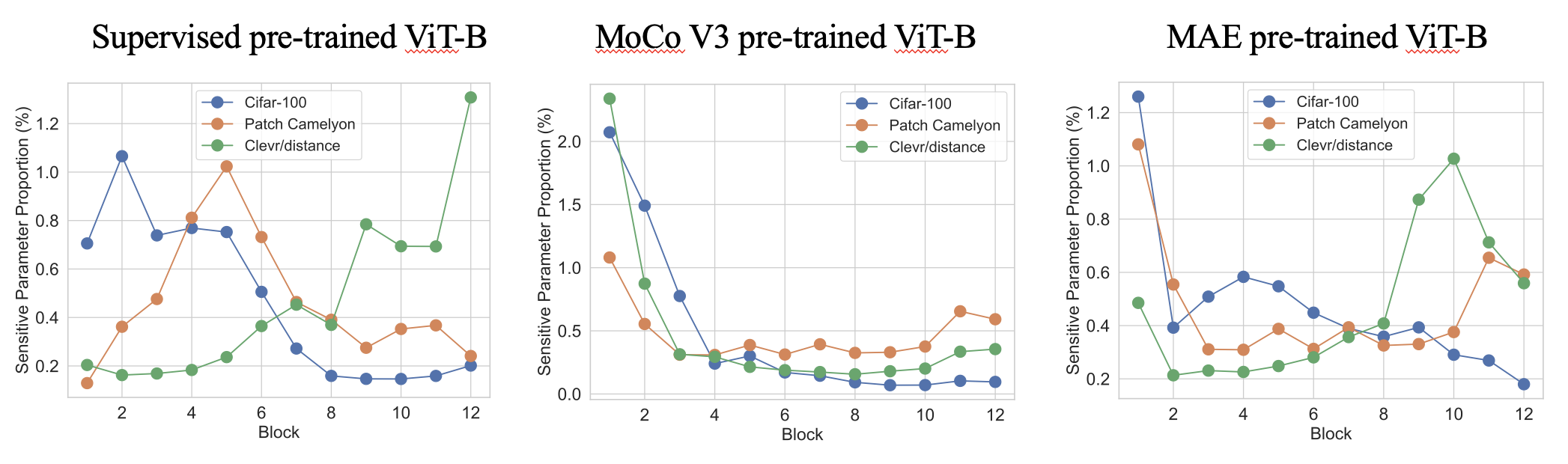
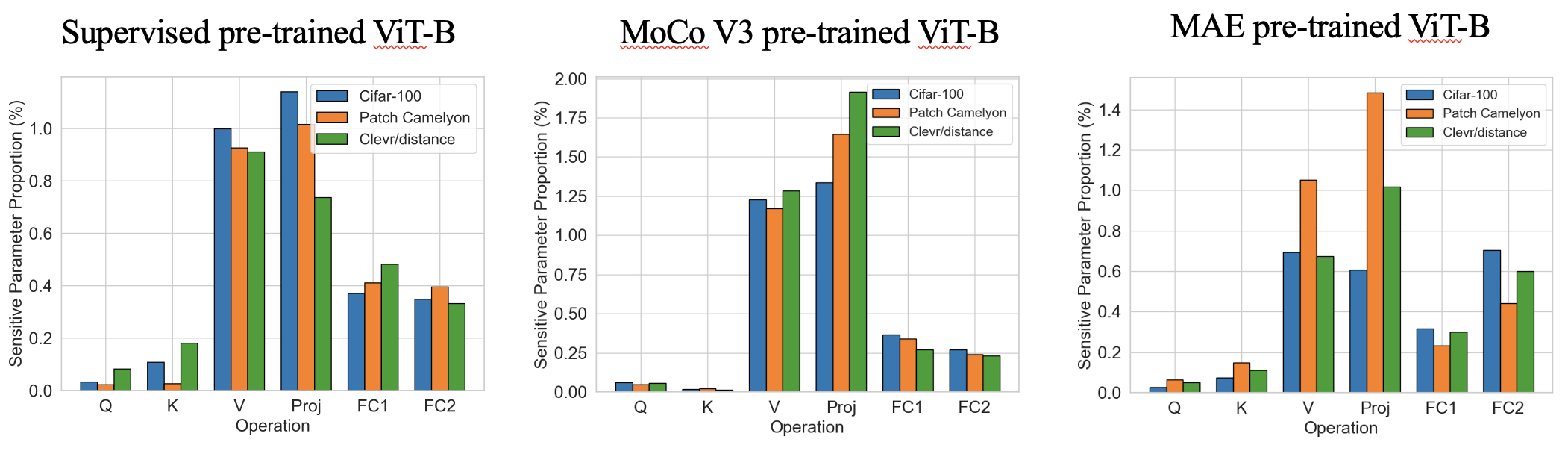
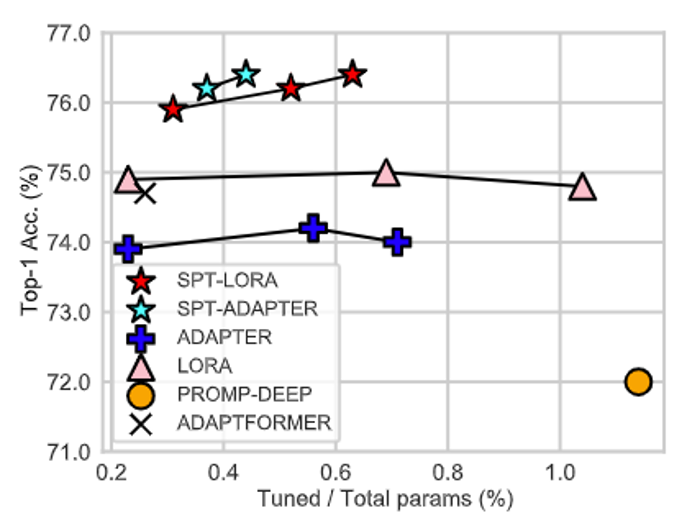
第2阶段是标准的PEFT,可将大多数参数冻结,并且仅对可训练的参数进行微调。我们的SPT将可训练的参数引入了两个粒度的敏感位置:非结构化的神经元和结构化的PEFT模块(例如,Lora或适配器),以实现良好的性能!
如果您发现此存储库或我们的论文很有用,请考虑引用并饰演我们!
@inproceedings{he2023sensitivity,
title={Sensitivity-Aware Visual Parameter-Efficient Fine-Tuning},
author={He, Haoyu and Cai, Jianfei and Zhang, Jing and Tao, Dacheng and Zhuang, Bohan},
booktitle={ICCV},
year={2023}
}
我们已经在Torch 1.8.0和1.10.0上测试了代码。请在主目录中使用以下代码安装其他依赖项:
pip install -r requirements.txt
我们为主基准VTAB-1K提供培训和推理代码。
cd data/vtab-source
python get_vtab1k.py
PS:您可能必须手动安装Sun397。请参考VTAB-1K。
请使用以下代码下载骨干:
cd checkpoints
# Supervised pre-trained ViT-B/16
wget https://console.cloud.google.com/storage/browser/_details/vit_models/imagenet21k/ViT-B_16.npz
# MAE pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth
# MoCo V3 pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/moco-v3/vit-b-300ep/linear-vit-b-300ep.pth.tar
我们提供了以下代码(我们已经为受监督的预训练的VIT-B/16提供了灵敏度sensitivity_spt_supervised_lora_a10和sensitivity_spt_supervised_adapter_a10 )。
# SPT-ADAPTER and SPT-LORA with supervised pre-trained ViT-B/16
bash configs/vtab_mae_spt_lora_sensitivity.sh
bash configs/vtab_mae_spt_adapter_sensitivity.sh
# SPT-ADAPTER and SPT-LORA with MAE pre-trained ViT-B/16
bash configs/vtab_mae_spt_lora_sensitivity.sh
bash configs/vtab_mae_spt_adapter_sensitivity.sh
# SPT-ADAPTER and SPT-LORA with MoCo V3 pre-trained ViT-B/16
bash configs/vtab_mae_spt_lora_sensitivity.sh
bash configs/vtab_mae_spt_adapter_sensitivity.sh
我们提供了以下培训代码:
# SPT-ADAPTER and SPT-LORA with supervised pre-trained ViT-B/16
bash configs/vtab_supervised_spt_lora.sh
bash configs/vtab_supervised_spt_adapter.sh
# SPT-ADAPTER and SPT-LORA with MAE pre-trained ViT-B/16
bash configs/vtab_mae_spt_lora.sh
bash configs/vtab_mae_spt_adapter.sh
# SPT-ADAPTER and SPT-LORA with MoCo V3 pre-trained ViT-B/16
bash configs/vtab_moco_spt_lora.sh
bash configs/vtab_moco_spt_adapter.sh
PS:我们扫描不同的可训练参数预算,以寻求潜在的更好的结果(从0.2m到1.0m)。
- [x] Release code for SPT on ViTs.
- [ ] Release code for FGVC benchmark training (ETA October).
- [ ] Release code for SPT on Swin (ETA October).
- [ ] Release code for SPT on ConvNext (ETA October).
- [ ] Integrate to [PEFT](https://github.com/huggingface/peft) package.
我们的代码是根据Noah,Coop,AutoFormer,Timm和MMCV修改的。我们感谢作者的开源代码。


