SPT
1.0.0
[ICCV 2023] (Oral) 이것은 우리 논문의 공식 저장소입니다. Haoyu He, Jianfei Cai, Jing Zhang, Dacheng Tao 및 Bohan Zhuang의 감도 인식 시각 매개 변수 효율적인 미세 조정.
[2023-09-12] : 릴리스 코드.소식
[2023-08-12] : 구두 프레젠테이션을 위해 ICCV 2023에 의해 받아 들여졌습니다!
PEFT (Parameter-Effcient Fine-Tuning)에서 학습 가능한 매개 변수로 다른 아키텍처를 제시하는 대신, 우리의 작업은 PEFT 아키텍처를 다양한 작업에 맞게 조정 된 최적의 위치에 놓는 것의 중요성을 강조합니다!

우리의 SPT는 두 단계로 구성됩니다.
1 단계는 훈련 가능한 매개 변수를 도입 할 위치를 찾기 위해 매우 빠른 원샷 매개 변수 감도 추정 (몇 초)입니다. 다음은 상위 0.4% 민감한 매개 변수를 가진 다양한 미리 훈련 된 VIT의 흥미로운 감도 패턴입니다. 우리는 비율이 작동 측면에서 네트워크 깊이 및 작업에 대한 유사한 패턴 측면에서 작업 별 다양한 패턴을 나타냅니다.
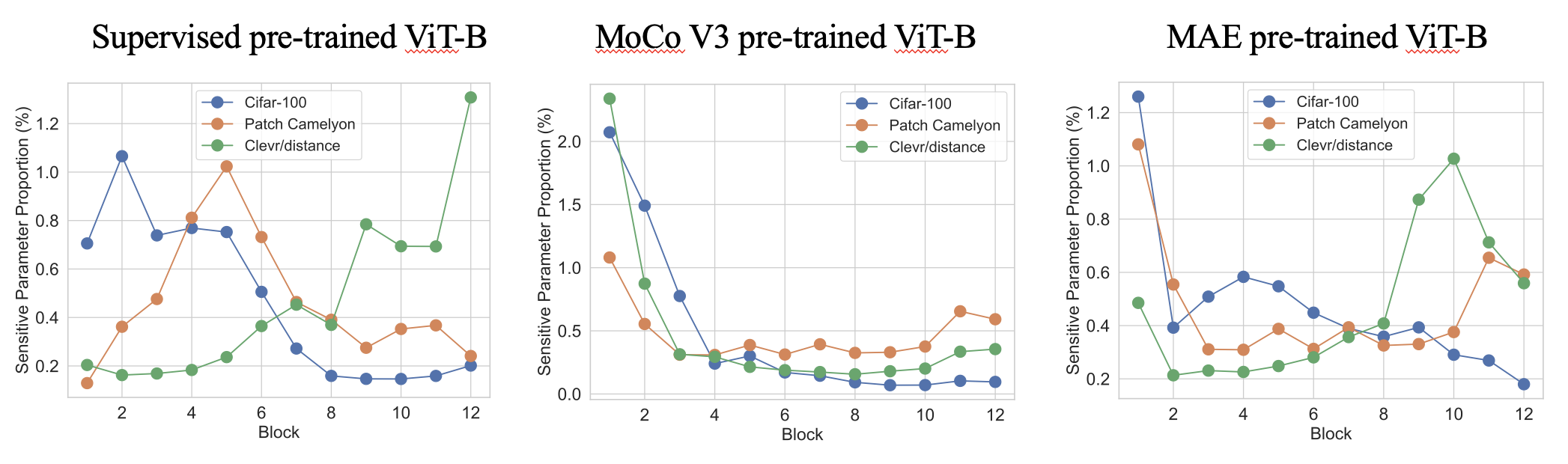
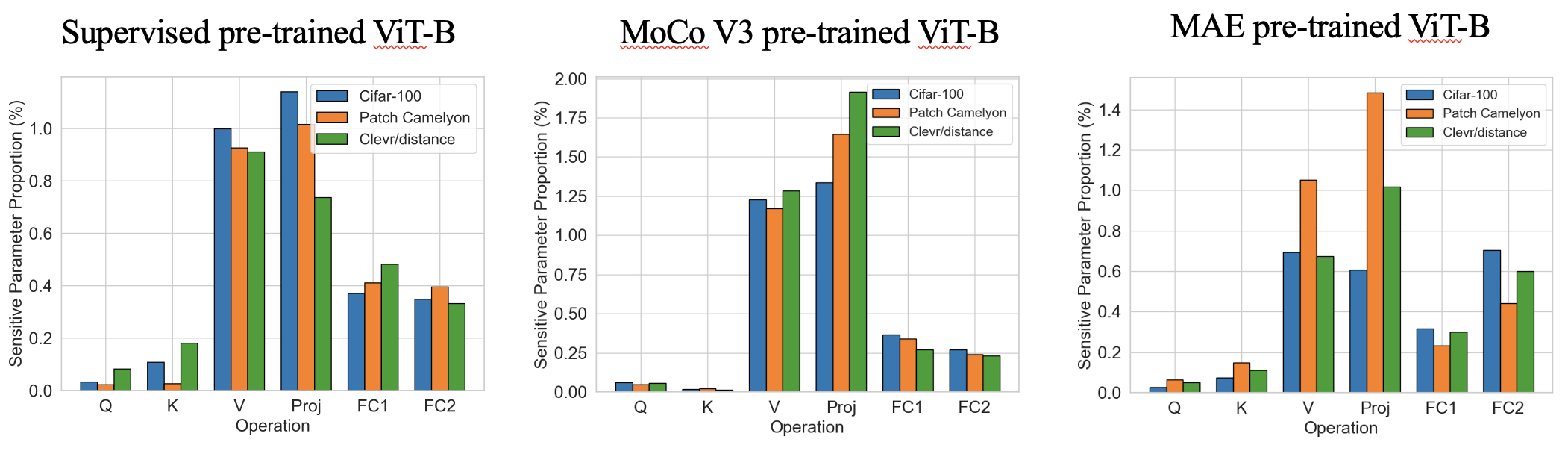
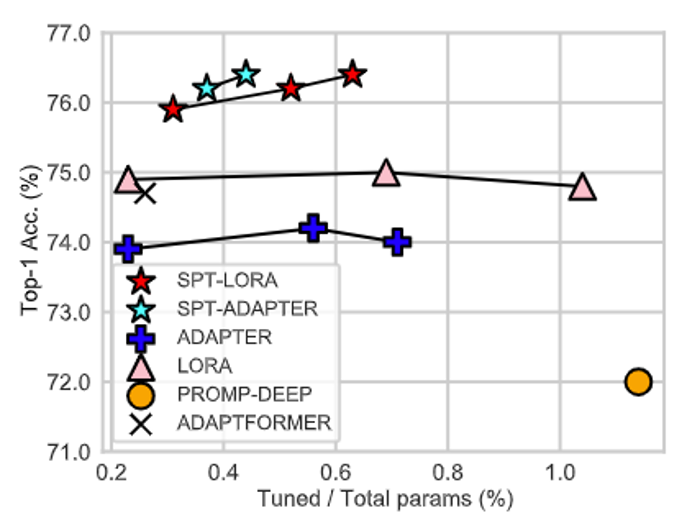
2 단계는 표준 PEFT로, 대부분의 매개 변수를 동결시키고 훈련 가능한 것만 미세 조정합니다. 당사의 SPT는 두 가지 과립력의 민감한 위치에 훈련 가능한 매개 변수를 소개합니다. 즉 구조화되지 않은 뉴런과 구조화 된 PEFT 모듈 (예 : LORA 또는 어댑터)이 우수한 성능을 달성합니다!
이 저장소 나 논문이 유용하다면 인용하고 우리를 별표로 고려하십시오!
@inproceedings{he2023sensitivity,
title={Sensitivity-Aware Visual Parameter-Efficient Fine-Tuning},
author={He, Haoyu and Cai, Jianfei and Zhang, Jing and Tao, Dacheng and Zhuang, Bohan},
booktitle={ICCV},
year={2023}
}
우리는 토치 1.8.0과 1.10.0에서 코드를 테스트했습니다. 홈 디렉토리에 다음 코드로 다른 종속성을 설치하십시오.
pip install -r requirements.txt
우리는 주요 벤치 마크 VTAB-1K에 대한 교육 및 추론 코드를 제공합니다.
cd data/vtab-source
python get_vtab1k.py
추신 : SUN397을 수동으로 설치해야 할 수도 있습니다. VTAB-1K를 참조하십시오.
다음 코드로 백본을 다운로드하십시오.
cd checkpoints
# Supervised pre-trained ViT-B/16
wget https://console.cloud.google.com/storage/browser/_details/vit_models/imagenet21k/ViT-B_16.npz
# MAE pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth
# MoCo V3 pre-trained ViT-B/16
wget https://dl.fbaipublicfiles.com/moco-v3/vit-b-300ep/linear-vit-b-300ep.pth.tar
우리는 다음 코드를 제공했습니다 (우리는 이미 sensitivity_spt_supervised_adapter_a10 sensitivity_spt_supervised_lora_a10 에서 감독 된 미리 훈련 된 VIT-B/16에 대한 감도를 이미 제공했습니다.
# SPT-ADAPTER and SPT-LORA with supervised pre-trained ViT-B/16
bash configs/vtab_mae_spt_lora_sensitivity.sh
bash configs/vtab_mae_spt_adapter_sensitivity.sh
# SPT-ADAPTER and SPT-LORA with MAE pre-trained ViT-B/16
bash configs/vtab_mae_spt_lora_sensitivity.sh
bash configs/vtab_mae_spt_adapter_sensitivity.sh
# SPT-ADAPTER and SPT-LORA with MoCo V3 pre-trained ViT-B/16
bash configs/vtab_mae_spt_lora_sensitivity.sh
bash configs/vtab_mae_spt_adapter_sensitivity.sh
우리는 다음과 같은 교육 코드를 제공했습니다.
# SPT-ADAPTER and SPT-LORA with supervised pre-trained ViT-B/16
bash configs/vtab_supervised_spt_lora.sh
bash configs/vtab_supervised_spt_adapter.sh
# SPT-ADAPTER and SPT-LORA with MAE pre-trained ViT-B/16
bash configs/vtab_mae_spt_lora.sh
bash configs/vtab_mae_spt_adapter.sh
# SPT-ADAPTER and SPT-LORA with MoCo V3 pre-trained ViT-B/16
bash configs/vtab_moco_spt_lora.sh
bash configs/vtab_moco_spt_adapter.sh
추신 : 우리는 다른 훈련 가능한 매개 변수 예산을 휩쓸어 잠재적 인 더 나은 결과 (0.2m ~ 1.0m)를 찾습니다.
- [x] Release code for SPT on ViTs.
- [ ] Release code for FGVC benchmark training (ETA October).
- [ ] Release code for SPT on Swin (ETA October).
- [ ] Release code for SPT on ConvNext (ETA October).
- [ ] Integrate to [PEFT](https://github.com/huggingface/peft) package.
우리의 코드는 Noah, Coop, Autoformer, Timm 및 MMCV에서 수정되었습니다. 오픈 소스 코드에 대해 저자에게 감사드립니다.


