conformer
v1.0

Pytorch实施构象异构体:卷积调格的变压器以进行语音识别。
变压器模型擅长捕获基于内容的全局交互,而CNNS有效利用本地功能。构象体将卷积神经网络和变压器结合在一起,以参数效率的方式对音频序列的局部和全局依赖性进行建模。构象异构体的表现明显优于先前的变压器和基于CNN的模型,该模型可实现最先进的精度。
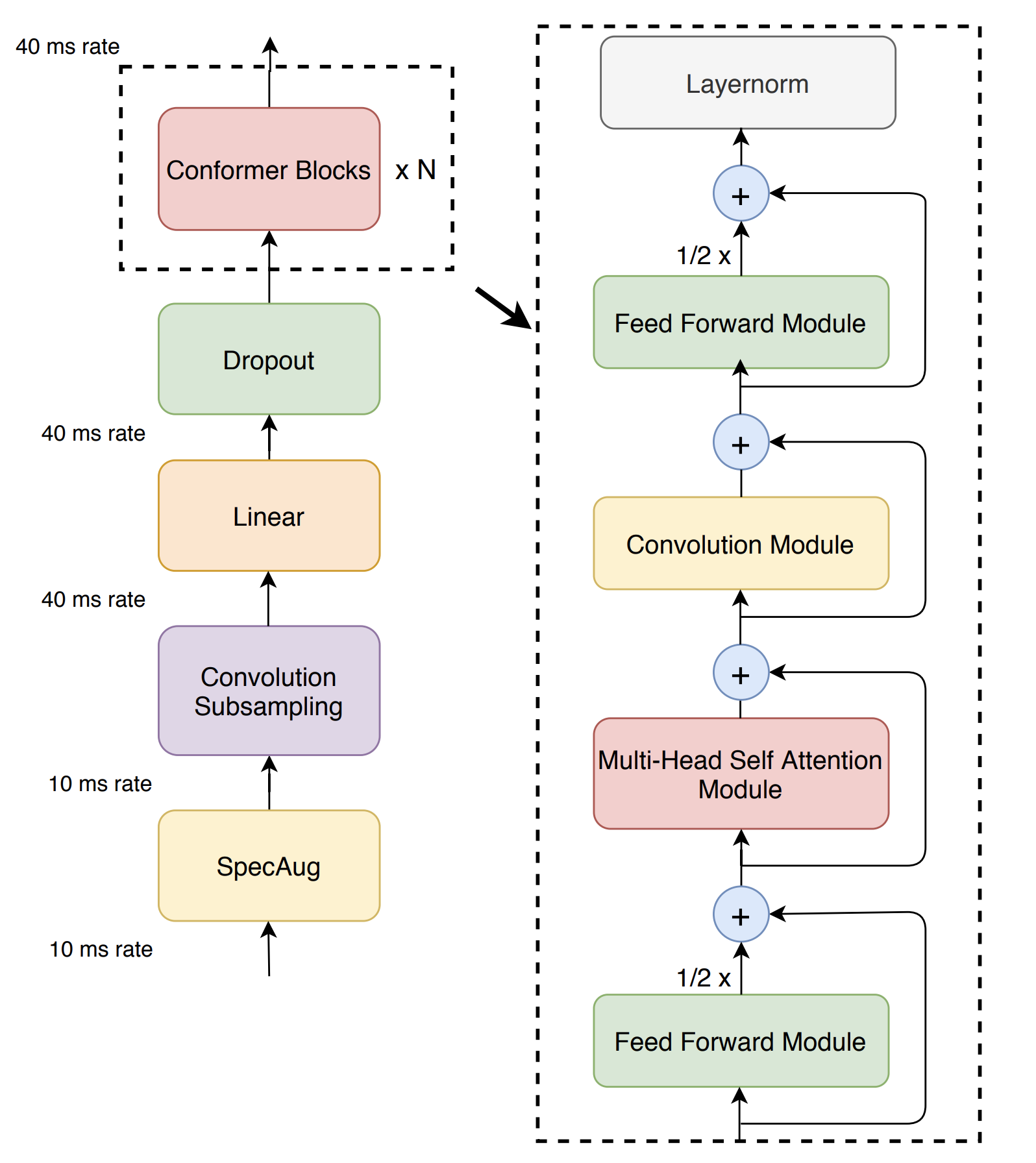
该存储库仅包含模型代码,但是您可以在OpenSpeech上使用构象异构体训练
该项目建议Python 3.7或更高。我们建议为该项目(使用Virtual Env或Conda)创建一个新的虚拟环境。
pip install numpy (请参阅此处的问题安装Numpy)。当前,我们仅使用SetUptools从源代码安装。检查源代码并运行以下命令:
pip install -e .
import torch
import torch . nn as nn
from conformer import Conformer
batch_size , sequence_length , dim = 3 , 12345 , 80
cuda = torch . cuda . is_available ()
device = torch . device ( 'cuda' if cuda else 'cpu' )
criterion = nn . CTCLoss (). to ( device )
inputs = torch . rand ( batch_size , sequence_length , dim ). to ( device )
input_lengths = torch . LongTensor ([ 12345 , 12300 , 12000 ])
targets = torch . LongTensor ([[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 5 , 6 , 2 ],
[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 5 , 2 , 0 ],
[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 2 , 0 , 0 ]]). to ( device )
target_lengths = torch . LongTensor ([ 9 , 8 , 7 ])
model = Conformer ( num_classes = 10 ,
input_dim = dim ,
encoder_dim = 32 ,
num_encoder_layers = 3 ). to ( device )
# Forward propagate
outputs , output_lengths = model ( inputs , input_lengths )
# Calculate CTC Loss
loss = criterion ( outputs . transpose ( 0 , 1 ), targets , output_lengths , target_lengths )如果您有任何疑问,错误报告和功能请求,请在github上打开问题或
请联系[email protected]。
感谢任何形式的反馈或贡献。请随时进行小问题,例如错误修复,文档改进。对于主要贡献和新功能,请与合作者讨论相应的问题。
我关注PEP-8以获取代码样式。特别是Docstrings的风格对于生成文档很重要。


