conformer
v1.0

Pytorch-Implementierung des Konformers: Faltungsverzinsungstransformator zur Spracherkennung.
Transformatormodelle sind gut darin, inhaltsbasierte globale Interaktionen zu erfassen, während CNNs lokale Funktionen effektiv ausnutzen. Konformer kombinieren Faltung Neuronale Netze und Transformatoren, um sowohl lokale als auch globale Abhängigkeiten einer Audiosequenz auf parametereffiziente Weise zu modellieren. Der Konformer übertrifft den vorherigen Transformator- und CNN-basierten Modellen, der hochmoderne Genauigkeiten erreicht, signifikant.
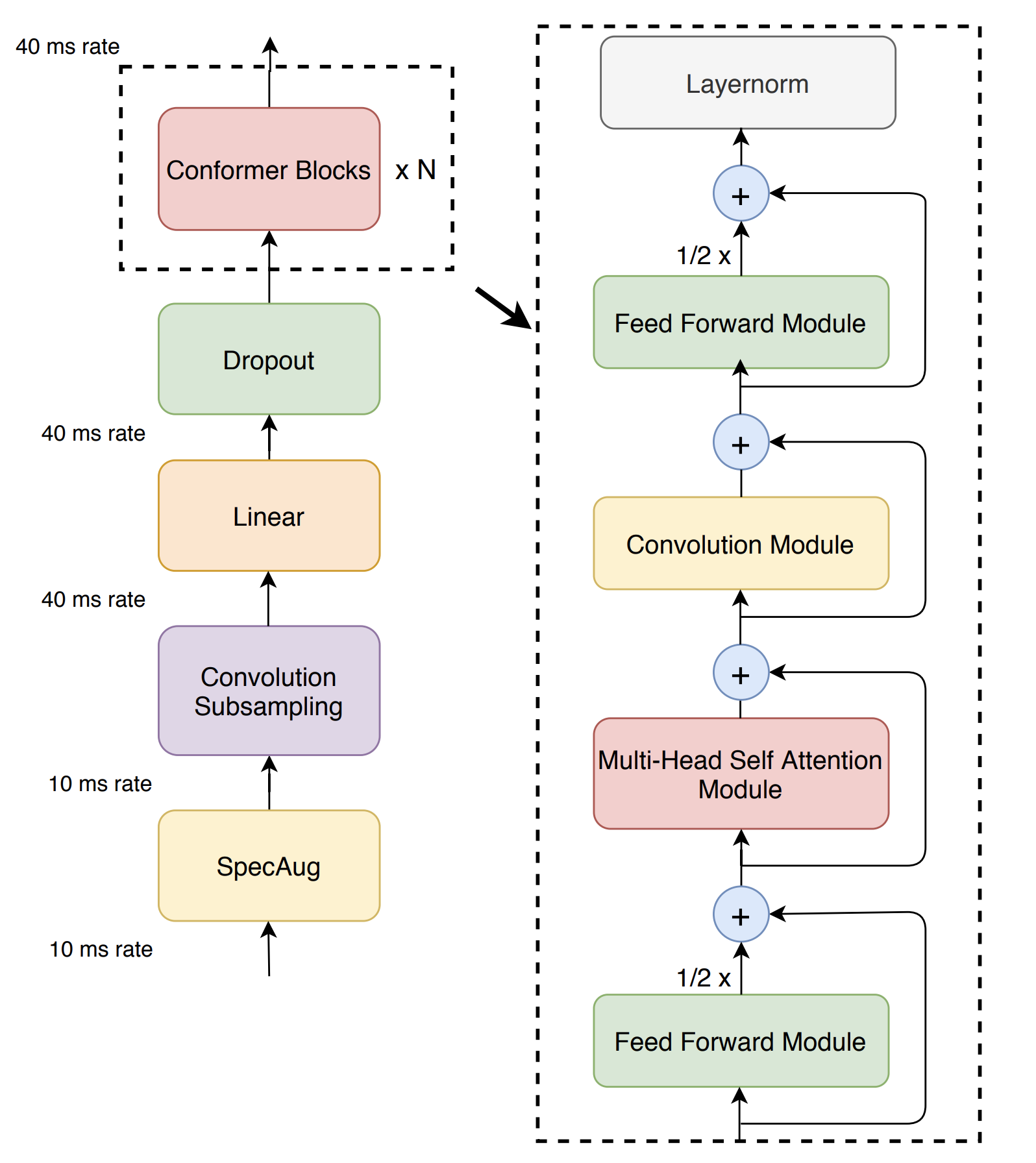
Dieses Repository enthält nur Modellcode, aber Sie können mit Konformer bei Openenspeech trainieren
Dieses Projekt empfiehlt Python 3.7 oder höher. Wir empfehlen, eine neue virtuelle Umgebung für dieses Projekt zu erstellen (unter Verwendung von Virtual Env oder Conda).
pip install numpy (siehe Problem, um Numpy zu installieren).Derzeit unterstützen wir nur die Installation vom Quellcode mithilfe von Setuptools. Schauen Sie den Quellcode an und führen Sie die folgenden Befehle aus:
pip install -e .
import torch
import torch . nn as nn
from conformer import Conformer
batch_size , sequence_length , dim = 3 , 12345 , 80
cuda = torch . cuda . is_available ()
device = torch . device ( 'cuda' if cuda else 'cpu' )
criterion = nn . CTCLoss (). to ( device )
inputs = torch . rand ( batch_size , sequence_length , dim ). to ( device )
input_lengths = torch . LongTensor ([ 12345 , 12300 , 12000 ])
targets = torch . LongTensor ([[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 5 , 6 , 2 ],
[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 5 , 2 , 0 ],
[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 2 , 0 , 0 ]]). to ( device )
target_lengths = torch . LongTensor ([ 9 , 8 , 7 ])
model = Conformer ( num_classes = 10 ,
input_dim = dim ,
encoder_dim = 32 ,
num_encoder_layers = 3 ). to ( device )
# Forward propagate
outputs , output_lengths = model ( inputs , input_lengths )
# Calculate CTC Loss
loss = criterion ( outputs . transpose ( 0 , 1 ), targets , output_lengths , target_lengths ) Wenn Sie Fragen, Fehlerberichte und Feature -Anfragen haben, öffnen Sie bitte ein Problem auf GitHub oder
Kontakte [email protected] Bitte.
Ich schätze jede Art von Feedback oder Beitrag. Fühlen Sie sich frei, mit kleinen Problemen wie Fehlerbehebungen und Verbesserungen der Dokumentation fortzusetzen. Für wichtige Beiträge und neue Funktionen besprechen Sie bitte mit den Mitarbeitern in entsprechenden Themen.
Ich folge PEP-8 für den Codestil. Insbesondere der Stil von Docstrings ist wichtig, um Dokumentation zu generieren.


