conformer
v1.0

Conformer의 Pytorch 구현 : 음성 인식을위한 Convolution-Augmented Transformer.
Transformer 모델은 컨텐츠 기반 글로벌 상호 작용을 캡처하는 데 능숙한 반면 CNN은 로컬 기능을 효과적으로 활용합니다. Conformer는 Convolution Neural Networks와 Transformer를 결합하여 오디오 시퀀스의 로컬 및 글로벌 종속성을 매개 변수 효율적인 방식으로 모델링합니다. Conformer는 이전 변압기 및 CNN 기반 모델보다 최첨단 정확도를 달성하는 것보다 훨씬 능가합니다.
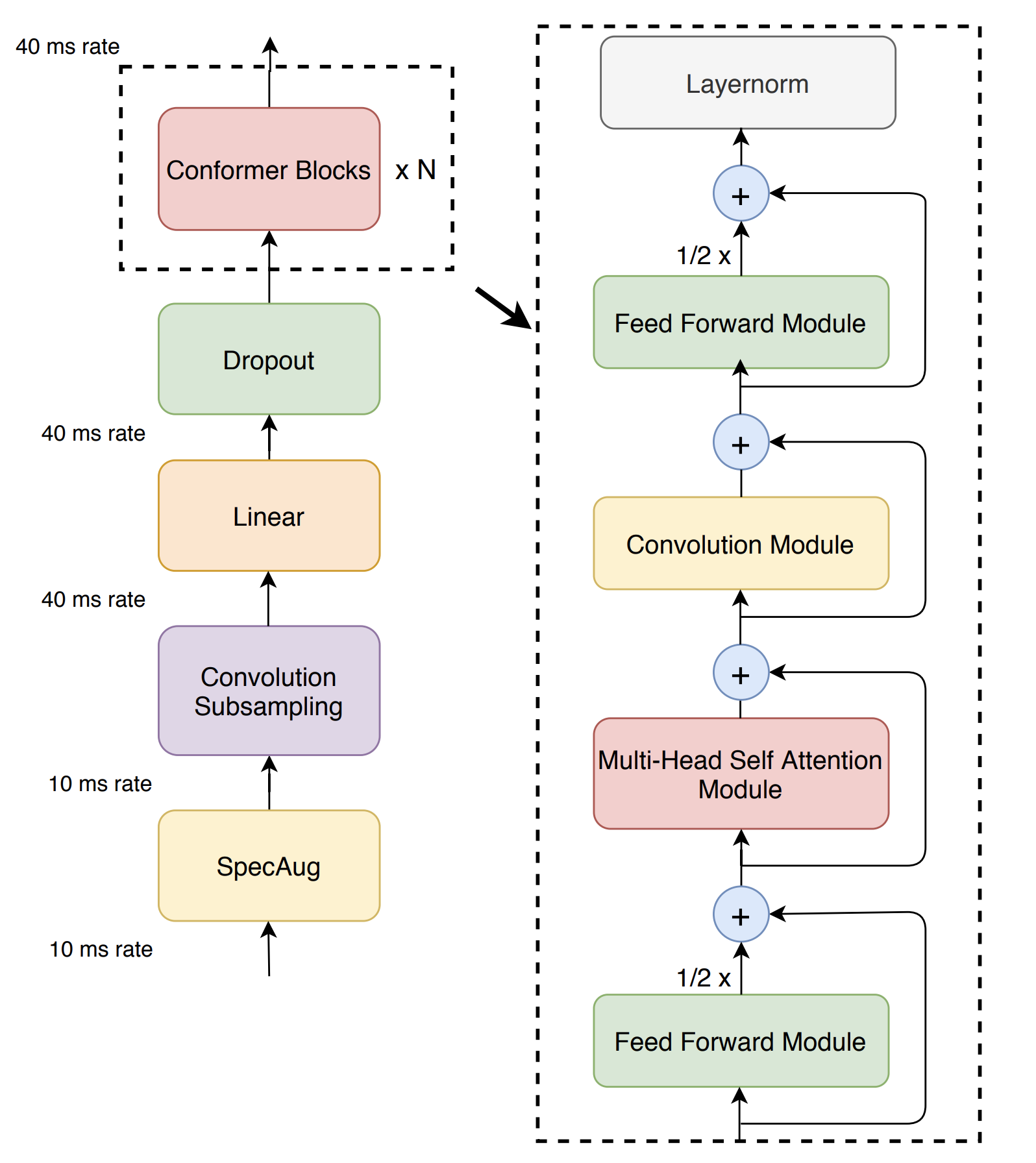
이 저장소에는 모델 코드 만 포함되지만 OpenSpeee에서 Conformer로 훈련 할 수 있습니다.
이 프로젝트는 Python 3.7 이상을 권장합니다. 이 프로젝트를위한 새로운 가상 환경을 만드는 것이 좋습니다 (가상 Env 또는 Conda 사용).
pip install numpy (Numpy 설치 문제는 여기를 참조하십시오).현재 SetUptools를 사용하여 소스 코드에서만 설치를 지원합니다. 소스 코드를 확인하고 다음 명령을 실행하십시오.
pip install -e .
import torch
import torch . nn as nn
from conformer import Conformer
batch_size , sequence_length , dim = 3 , 12345 , 80
cuda = torch . cuda . is_available ()
device = torch . device ( 'cuda' if cuda else 'cpu' )
criterion = nn . CTCLoss (). to ( device )
inputs = torch . rand ( batch_size , sequence_length , dim ). to ( device )
input_lengths = torch . LongTensor ([ 12345 , 12300 , 12000 ])
targets = torch . LongTensor ([[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 5 , 6 , 2 ],
[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 5 , 2 , 0 ],
[ 1 , 3 , 3 , 3 , 3 , 3 , 4 , 2 , 0 , 0 ]]). to ( device )
target_lengths = torch . LongTensor ([ 9 , 8 , 7 ])
model = Conformer ( num_classes = 10 ,
input_dim = dim ,
encoder_dim = 32 ,
num_encoder_layers = 3 ). to ( device )
# Forward propagate
outputs , output_lengths = model ( inputs , input_lengths )
# Calculate CTC Loss
loss = criterion ( outputs . transpose ( 0 , 1 ), targets , output_lengths , target_lengths ) 질문, 버그 보고서 및 기능 요청이 있으면 Github 또는
연락처 [email protected] 제발.
모든 종류의 피드백이나 기여에 감사드립니다. 버그 수정, 문서 개선과 같은 작은 문제를 자유롭게 진행하십시오. 주요 기여 및 새로운 기능은 해당 문제로 협력자와 토론하십시오.
코드 스타일에 대해 PEP-8을 따릅니다. 특히 문서화 스타일은 문서를 생성하는 데 중요합니다.


