PromptLink
1.0.0
此存储库包含我们的纸质代码“ PickertLink:利用大型语言模型进行跨源生物医学概念链接”。
在本文中,我们介绍了链接的生物医学概念,该任务的目的是基于其语义含义和生物医学知识来跨来源/系统的生物医学概念。它完全依靠概念名称,因此可以涵盖更广泛的现实应用程序。此任务不同于现有任务,例如实体链接,实体对齐和本体匹配,这些任务取决于其他上下文或拓扑信息。下图描述了生物医学概念链接任务的玩具示例。
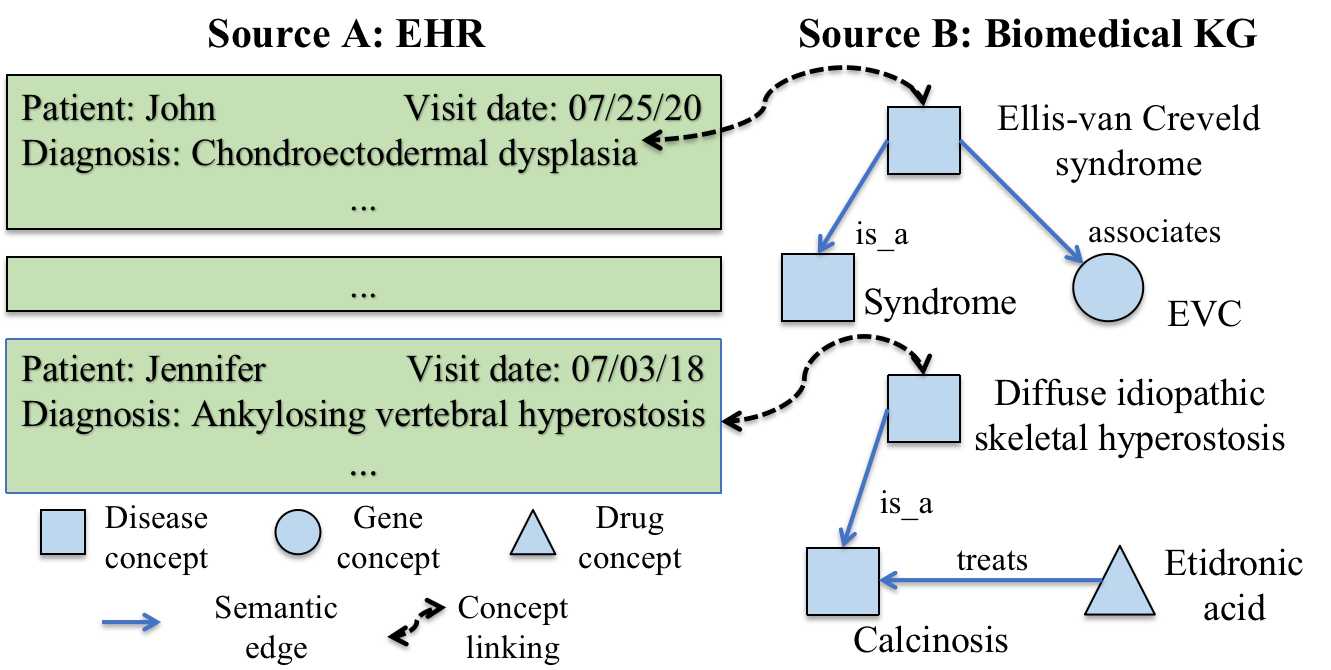
图1:玩具示例。左:EHR中的概念。右:生物医学kg中的概念。
Pickerlink是一种新型的生物医学概念,将利用大型语言模型(LLM)的框架联系起来。它首先采用专门研究生物医学的预训练的语言模型来产生适合LLM上下文窗口中的候选概念。然后,它利用LLM通过两个阶段的提示来链接概念。第一阶段的提示旨在从LLM中获取概念链接任务的生物医学先验知识,而第二阶段的提示则迫使LLM反思自己的预测以进一步提高其可靠性。下图说明了Pickerlink框架的概述。
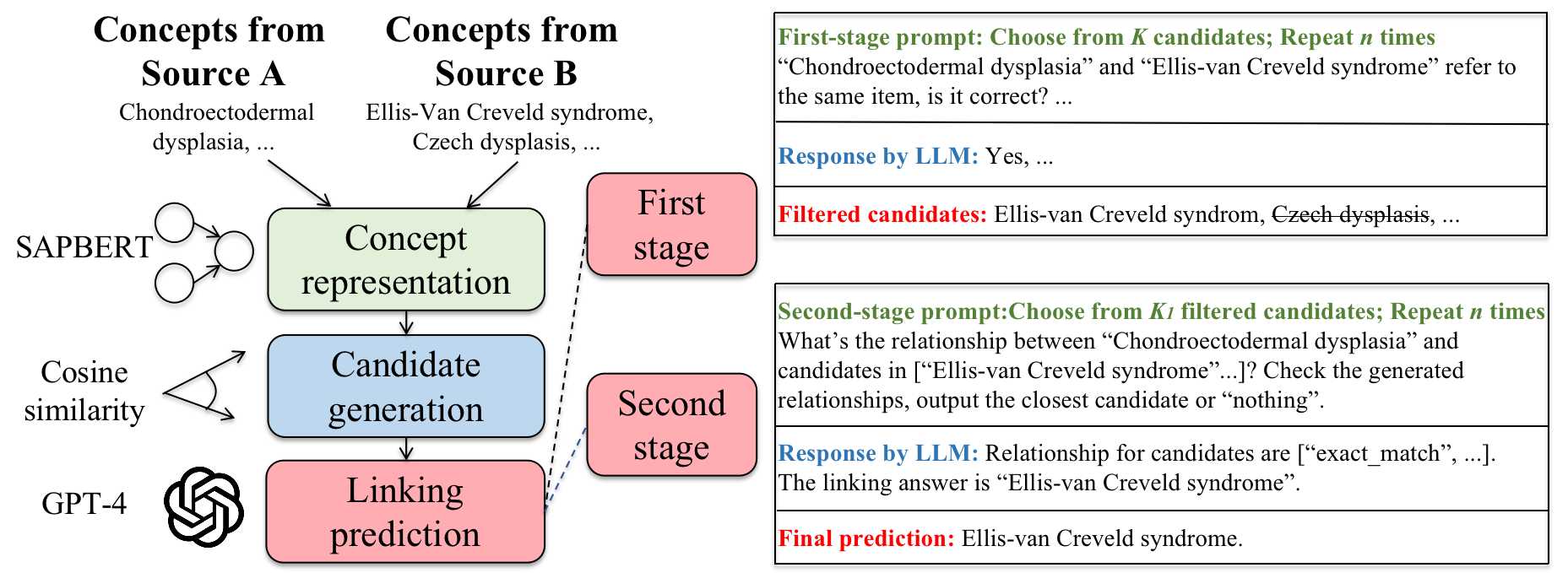
图2:我们提出的下午链接框架的概述。
[“ unignts.txt”文件可用于自动下载Python软件包]
Python == 3.8.10
EditDistance == 0.6.2
火== 0.5.0
numpy == 1.19.5
OpenAi == 0.28.1
熊猫== 1.3.4
rank_bm25 == 0.2.2
Scipy == 1.12.0
simString-fast == 0.3.0
textDistance == 4.6.1
TORCH == 1.10.0+CU111
TQDM == 4.66.1
变形金刚== 4.33.3
We curate two biomedical concept linking benchmark datasets: MIID (MIMIC-III-iBKH-Disease) and CISE (CRADLE-iBKH-Side-Effect), using data from MIMIC-III EHR dataset MIMIC Link, CRADLE EHR dataset (a private EHR dataset collected from a large healthcare system in the United States), iBKH KG dataset IBKH链接和UMLS编码系统UMLS链接。由于医疗数据和隐私注意事项的敏感性,对数据共享存在限制。为了访问这些医疗数据集,可能需要进行适当的培训和证书。有关数据访问或其他相关查询的进一步帮助,请随时与我们的作者团队联系。
大多数代码存储在三个文件夹中:“ gen_candidates”,“ gen_gpt_responses”和“ baselines”。可以分别在这些文件夹中找到更多细节。
文件夹“ gen_candidates”:此文件夹包含Pickerlink概念表示和候选生成过程的代码。
文件夹“ gen_gpt_responses”:此文件夹显示了如何利用LLM检索最终预测答案。
文件夹“ Baselines”:此文件夹包含用于运行所有基线方法的代码,包括BM25,Levenshtein距离,Biobert和Sapbert。


