tgn
1.0.0
| 动态图 | TGN |
|---|---|
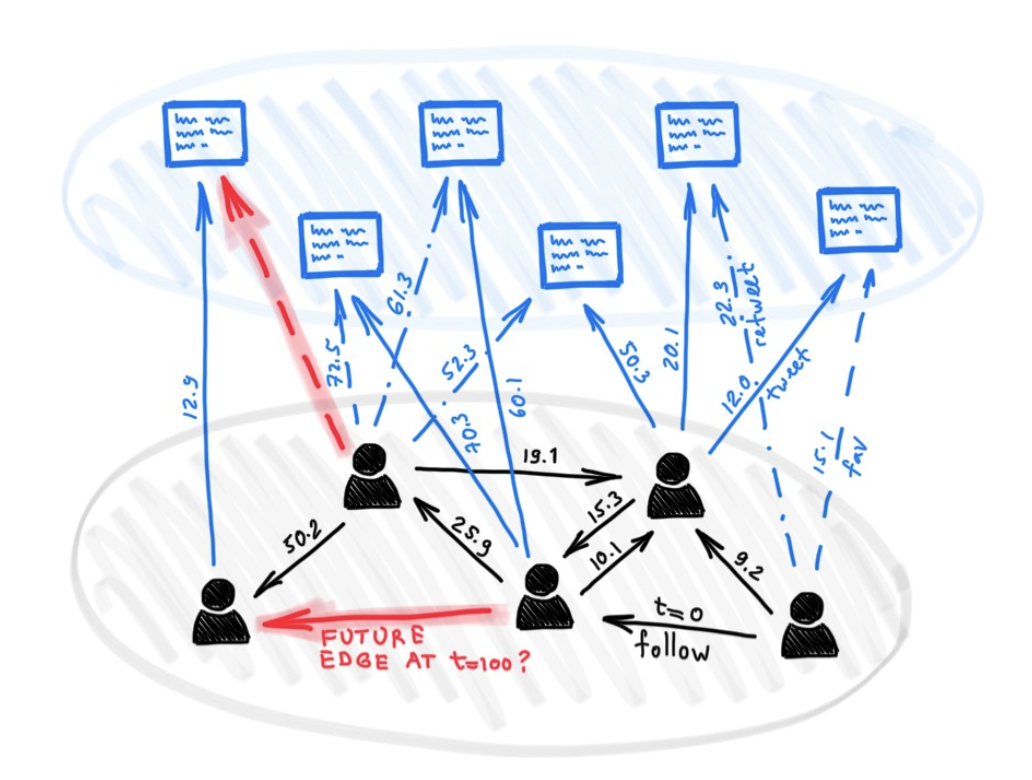 |  |
尽管有很多用于图形深度学习的不同模型,但到目前为止,很少有人提出用于处理某种动态性质的图表(例如随着时间的推移而发展的特征或连接性)。
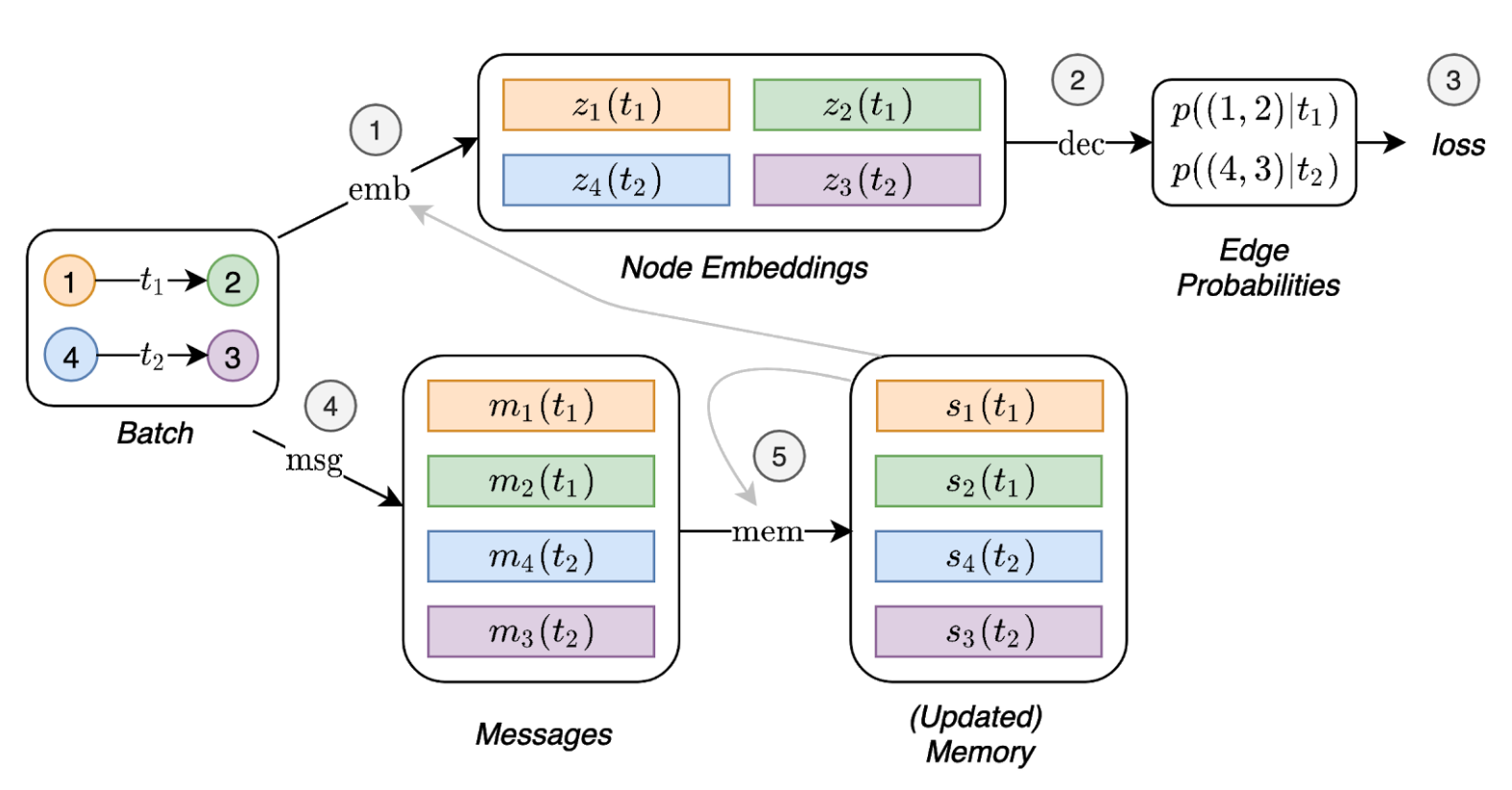
在本文中,我们提出了时间图网络(TGNS),这是一个通用,有效的框架,用于在动态图上进行深度学习,表示为定时事件的序列。得益于内存模块和基于图的运算符的新型组合,TGN能够显着优于以前的方法,同时更有效地计算了。
我们进一步表明,在动态图上学习的几种以前的学习模型可以作为我们框架的特定实例施放。我们对框架的不同组成部分进行了详细的消融研究,并设计了最佳的配置,该配置可以在动态图的几个跨性和归纳性预测任务上实现最新性能。
依赖项(带Python> = 3.7):
pandas==1.1.0
torch==1.6.0
scikit_learn==0.23.1
从此处下载示例数据集(例如Wikipedia和Reddit),然后将其CSV文件存储在名为data/文件夹中。
我们使用密集的npy格式以二进制格式保存功能。如果不存在边缘功能或节点特征,则将被零的向量取代。
python utils/preprocess_data.py --data wikipedia --bipartite
python utils/preprocess_data.py --data reddit --bipartite
使用链接预测任务的自我监督学习:
# TGN-attn: Supervised learning on the wikipedia dataset
python train_self_supervised.py --use_memory --prefix tgn-attn --n_runs 10
# TGN-attn-reddit: Supervised learning on the reddit dataset
python train_self_supervised.py -d reddit --use_memory --prefix tgn-attn-reddit --n_runs 10
对动态节点分类的监督学习(这需要从自我监督任务中进行训练的模型,例如运行上面的命令):
# TGN-attn: self-supervised learning on the wikipedia dataset
python train_supervised.py --use_memory --prefix tgn-attn --n_runs 10
# TGN-attn-reddit: self-supervised learning on the reddit dataset
python train_supervised.py -d reddit --use_memory --prefix tgn-attn-reddit --n_runs 10
### Wikipedia Self-supervised
# Jodie
python train_self_supervised.py --use_memory --memory_updater rnn --embedding_module time --prefix jodie_rnn --n_runs 10
# DyRep
python train_self_supervised.py --use_memory --memory_updater rnn --dyrep --use_destination_embedding_in_message --prefix dyrep_rnn --n_runs 10
### Reddit Self-supervised
# Jodie
python train_self_supervised.py -d reddit --use_memory --memory_updater rnn --embedding_module time --prefix jodie_rnn_reddit --n_runs 10
# DyRep
python train_self_supervised.py -d reddit --use_memory --memory_updater rnn --dyrep --use_destination_embedding_in_message --prefix dyrep_rnn_reddit --n_runs 10
### Wikipedia Supervised
# Jodie
python train_supervised.py --use_memory --memory_updater rnn --embedding_module time --prefix jodie_rnn --n_runs 10
# DyRep
python train_supervised.py --use_memory --memory_updater rnn --dyrep --use_destination_embedding_in_message --prefix dyrep_rnn --n_runs 10
### Reddit Supervised
# Jodie
python train_supervised.py -d reddit --use_memory --memory_updater rnn --embedding_module time --prefix jodie_rnn_reddit --n_runs 10
# DyRep
python train_supervised.py -d reddit --use_memory --memory_updater rnn --dyrep --use_destination_embedding_in_message --prefix dyrep_rnn_reddit --n_runs 10
命令在不同模块的消融研究中复制所有结果:
# TGN-2l
python train_self_supervised.py --use_memory --n_layer 2 --prefix tgn-2l --n_runs 10
# TGN-no-mem
python train_self_supervised.py --prefix tgn-no-mem --n_runs 10
# TGN-time
python train_self_supervised.py --use_memory --embedding_module time --prefix tgn-time --n_runs 10
# TGN-id
python train_self_supervised.py --use_memory --embedding_module identity --prefix tgn-id --n_runs 10
# TGN-sum
python train_self_supervised.py --use_memory --embedding_module graph_sum --prefix tgn-sum --n_runs 10
# TGN-mean
python train_self_supervised.py --use_memory --aggregator mean --prefix tgn-mean --n_runs 10
optional arguments:
-d DATA, --data DATA Data sources to use (wikipedia or reddit)
--bs BS Batch size
--prefix PREFIX Prefix to name checkpoints and results
--n_degree N_DEGREE Number of neighbors to sample at each layer
--n_head N_HEAD Number of heads used in the attention layer
--n_epoch N_EPOCH Number of epochs
--n_layer N_LAYER Number of graph attention layers
--lr LR Learning rate
--patience Patience of the early stopping strategy
--n_runs Number of runs (compute mean and std of results)
--drop_out DROP_OUT Dropout probability
--gpu GPU Idx for the gpu to use
--node_dim NODE_DIM Dimensions of the node embedding
--time_dim TIME_DIM Dimensions of the time embedding
--use_memory Whether to use a memory for the nodes
--embedding_module Type of the embedding module
--message_function Type of the message function
--memory_updater Type of the memory updater
--aggregator Type of the message aggregator
--memory_update_at_the_end Whether to update the memory at the end or at the start of the batch
--message_dim Dimension of the messages
--memory_dim Dimension of the memory
--backprop_every Number of batches to process before performing backpropagation
--different_new_nodes Whether to use different unseen nodes for validation and testing
--uniform Whether to sample the temporal neighbors uniformly (or instead take the most recent ones)
--randomize_features Whether to randomize node features
--dyrep Whether to run the model as DyRep
@inproceedings { tgn_icml_grl2020 ,
title = { Temporal Graph Networks for Deep Learning on Dynamic Graphs } ,
author = { Emanuele Rossi and Ben Chamberlain and Fabrizio Frasca and Davide Eynard and Federico
Monti and Michael Bronstein } ,
booktitle = { ICML 2020 Workshop on Graph Representation Learning } ,
year = { 2020 }
}

