บรรณาธิการของ Downcodes ได้เรียนรู้ว่า Tencent Youtu Lab ร่วมมือกับทีมวิจัยของ Shanghai Jiao Tong University เพื่อพัฒนาวิธีการเพิ่มพูนความรู้ที่ก้าวล้ำ ซึ่งนำมาซึ่งการเปลี่ยนแปลงครั้งยิ่งใหญ่ในการเพิ่มประสิทธิภาพโมเดลขนาดใหญ่ วิธีการนี้ไม่ต้องการการปรับแต่งโมเดลแบบดั้งเดิม ดึงความรู้โดยตรงจากข้อมูลโอเพ่นซอร์ส ลดความซับซ้อนของกระบวนการเพิ่มประสิทธิภาพอย่างมาก และเหนือกว่าเทคโนโลยีล้ำสมัย (SOTA) ในงานหลายอย่าง เทคโนโลยีที่เป็นนวัตกรรมนี้แก้ปัญหาวิธีการปรับแต่งแบบจำลองแบบดั้งเดิมได้อย่างมีประสิทธิภาพโดยอาศัยข้อมูลที่มีคำอธิบายประกอบและทรัพยากรการประมวลผลจำนวนมาก และมอบความเป็นไปได้ใหม่ๆ สำหรับการส่งเสริมโมเดลขนาดใหญ่ในการใช้งานจริง
Tencent Youtu Lab และทีมวิจัยของ Shanghai Jiao Tong University ร่วมกันเปิดตัววิธีการเพิ่มพูนความรู้ที่ปฏิวัติวงการ ซึ่งเปิดเส้นทางใหม่สำหรับการเพิ่มประสิทธิภาพโมเดลขนาดใหญ่ เทคโนโลยีที่เป็นนวัตกรรมนี้ละทิ้งข้อจำกัดของการปรับแต่งโมเดลแบบดั้งเดิม ดึงความรู้โดยตรงจากข้อมูลโอเพ่นซอร์ส ลดความซับซ้อนของกระบวนการเพิ่มประสิทธิภาพโมเดลอย่างมาก และบรรลุประสิทธิภาพที่โดดเด่นเหนือกว่าเทคโนโลยีล้ำสมัย (SOTA) ในงานหลายอย่าง
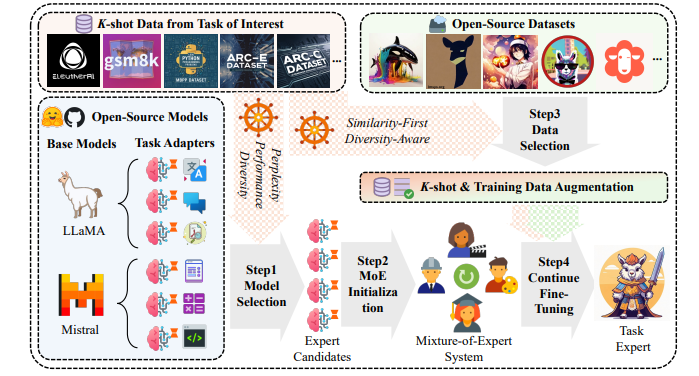
ในช่วงไม่กี่ปีที่ผ่านมา แม้ว่าโมเดลภาษาขนาดใหญ่ (LLM) จะมีความก้าวหน้าอย่างมากในสาขาต่างๆ แต่ก็ยังเผชิญกับความท้าทายมากมายในการใช้งานจริง วิธีการปรับแต่งแบบจำลองแบบดั้งเดิมอย่างละเอียดต้องใช้ข้อมูลที่มีคำอธิบายประกอบและทรัพยากรการประมวลผลจำนวนมาก ซึ่งมักจะทำได้ยากสำหรับธุรกิจเชิงปฏิบัติจำนวนมาก แม้ว่าชุมชนโอเพ่นซอร์สจะจัดเตรียมโมเดลที่ปรับแต่งอย่างละเอียดและชุดข้อมูลคำสั่งไว้มากมาย แต่วิธีการใช้ทรัพยากรเหล่านี้อย่างมีประสิทธิภาพ และปรับปรุงขีดความสามารถของงานและประสิทธิภาพการทำงานทั่วไปของโมเดลที่มีตัวอย่างที่มีป้ายกำกับจำกัด ยังคงเป็นปัญหาที่อุตสาหกรรมต้องเผชิญมาโดยตลอด
เพื่อตอบสนองต่อปัญหานี้ ทีมวิจัยได้เสนอกรอบการทดลองใหม่ที่เน้นการใช้ความรู้โอเพ่นซอร์สเพื่อเพิ่มความสามารถของโมเดลภายใต้เงื่อนไขของข้อมูลธุรกิจจริงที่มีป้ายกำกับ K-shot เฟรมเวิร์กนี้ใช้ประโยชน์จากมูลค่าของกลุ่มตัวอย่างที่มีจำกัดอย่างเต็มที่ และให้การปรับปรุงประสิทธิภาพสำหรับโมเดลภาษาขนาดใหญ่ในงานกำหนดทิศทาง
นวัตกรรมหลักของการวิจัยครั้งนี้ ได้แก่ :
การเลือกแบบจำลองที่มีประสิทธิภาพ: เพิ่มศักยภาพของแบบจำลองที่มีอยู่ให้สูงสุดภายใต้เงื่อนไขข้อมูลที่จำกัดโดยการประเมินความซับซ้อนของการอนุมาน ประสิทธิภาพของแบบจำลอง และความสมบูรณ์ของความรู้อย่างครอบคลุม
การเพิ่มประสิทธิภาพการดึงความรู้: ออกแบบวิธีการดึงความรู้ที่เกี่ยวข้องจากข้อมูลโอเพ่นซอร์ส ด้วยกลยุทธ์การคัดกรองข้อมูลที่สมดุลระหว่างความคล้ายคลึงและความหลากหลาย โดยจะให้ข้อมูลเสริมแก่โมเดลพร้อมทั้งลดความเสี่ยงในการติดตั้งมากเกินไป
ระบบแบบจำลองแบบปรับเปลี่ยนได้: ระบบแบบปรับได้ตามโครงสร้างแบบจำลองแบบผู้เชี่ยวชาญแบบไฮบริด ได้รับการสร้างขึ้นเพื่อให้เกิดการเสริมความรู้ระหว่างแบบจำลองที่มีประสิทธิภาพหลายแบบ และปรับปรุงประสิทธิภาพโดยรวม
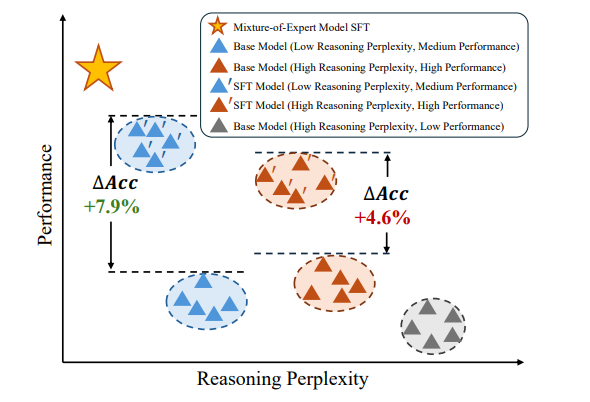
ในระหว่างระยะทดลอง ทีมวิจัยได้ทำการประเมินที่ครอบคลุมโดยใช้ชุดข้อมูลโอเพ่นซอร์ส 6 ชุด ผลลัพธ์แสดงให้เห็นว่าวิธีการใหม่นี้มีประสิทธิภาพเหนือกว่าวิธีพื้นฐานและวิธีการที่ทันสมัยอื่นๆ ในงานต่างๆ ด้วยการแสดงภาพรูปแบบการเปิดใช้งานของผู้เชี่ยวชาญ การศึกษายังพบว่าการมีส่วนร่วมของผู้เชี่ยวชาญแต่ละคนในแบบจำลองนั้นเป็นสิ่งที่ขาดไม่ได้ ซึ่งเป็นการยืนยันถึงประสิทธิผลของวิธีการนี้อีกด้วย
งานวิจัยนี้ไม่เพียงแต่แสดงให้เห็นถึงศักยภาพมหาศาลของความรู้โอเพ่นซอร์สในสาขาแบบจำลองขนาดใหญ่เท่านั้น แต่ยังให้แนวคิดใหม่สำหรับการพัฒนาเทคโนโลยีปัญญาประดิษฐ์ในอนาคต โดยทำลายข้อจำกัดของการเพิ่มประสิทธิภาพโมเดลแบบดั้งเดิม และมอบโซลูชันที่เป็นไปได้สำหรับองค์กรและสถาบันการวิจัย เพื่อปรับปรุงประสิทธิภาพของโมเดลภายใต้ทรัพยากรที่จำกัด
เนื่องจากเทคโนโลยีนี้ได้รับการปรับปรุงและส่งเสริมอย่างต่อเนื่อง เราจึงมีเหตุผลที่เชื่อได้ว่าเทคโนโลยีนี้จะมีบทบาทสำคัญในการยกระดับอุตสาหกรรมต่างๆ อย่างชาญฉลาด ความร่วมมือระหว่าง Tencent Youtu และ Shanghai Jiao Tong University ไม่เพียงแต่เป็นแบบอย่างของความร่วมมือระหว่างสถาบันการศึกษาและอุตสาหกรรมเท่านั้น แต่ยังเป็นก้าวสำคัญในการส่งเสริมเทคโนโลยีปัญญาประดิษฐ์ในระดับที่สูงขึ้นอีกด้วย
ที่อยู่กระดาษ: https://www.arxiv.org/pdf/2408.15915
ผลการวิจัยนี้ให้แนวคิดใหม่และแนวทางแก้ไขที่เป็นไปได้สำหรับการเพิ่มประสิทธิภาพโมเดลขนาดใหญ่ มีศักยภาพอย่างมากในการใช้งานจริง และคุ้มค่ากับการรอคอยการใช้งานและการพัฒนาเพิ่มเติมในอนาคต บรรณาธิการของ Downcodes จะยังคงให้ความสนใจกับการพัฒนาล่าสุดในสาขานี้และนำเสนอรายงานที่น่าตื่นเต้นแก่ผู้อ่านมากขึ้น