Downcodes の編集者は、Tencent Youtu Lab が上海交通大学の研究チームと協力して、大規模モデルの最適化に革命的な変化をもたらした画期的な知識強化手法を開発したことを知りました。この方法は、従来のモデルの微調整を必要とせず、オープンソース データから知識を直接抽出し、最適化プロセスを大幅に簡素化し、複数のタスクにおいて最先端のテクノロジー (SOTA) を上回ります。この革新的なテクノロジーは、従来のモデル微調整手法が大量の注釈付きデータとコンピューティング リソースに依存するという問題を効果的に解決し、実用的なアプリケーションで大規模モデルを推進するための新たな可能性を提供します。
Tencent Youtu Lab と上海交通大学の研究チームは共同で革新的な知識強化手法を開始し、大規模モデル最適化の新たな道を切り開きました。この革新的なテクノロジーは、従来のモデルの微調整の制限を放棄し、オープンソース データから直接知識を抽出し、モデルの最適化プロセスを大幅に簡素化し、複数のタスクで最先端のテクノロジー (SOTA) を超える優れたパフォーマンスを実現します。
近年、大規模言語モデル (LLM) はさまざまな分野で大きな進歩を遂げていますが、実用化には依然として多くの課題があります。従来のモデルの微調整方法では、大量の注釈付きデータとコンピューティング リソースが必要ですが、多くの実際のビジネスではこれを達成するのが困難なことがよくあります。オープンソース コミュニティは豊富な微調整モデルと命令データ セットを提供していますが、これらのリソースを効果的に活用し、限られたラベル付きサンプルでモデルのタスク機能と汎化パフォーマンスを向上させる方法は、業界が常に直面している問題です。
この問題に対応して、研究チームは、オープンソースの知識を使用して、K-shot ラベル付きの実際のビジネスデータの条件下でモデルの機能を強化することに焦点を当てた、新しい実験フレームワークを提案しました。このフレームワークは、限られたサンプルの価値を最大限に活用し、方向性のあるタスクにおける大規模な言語モデルのパフォーマンスを向上させます。
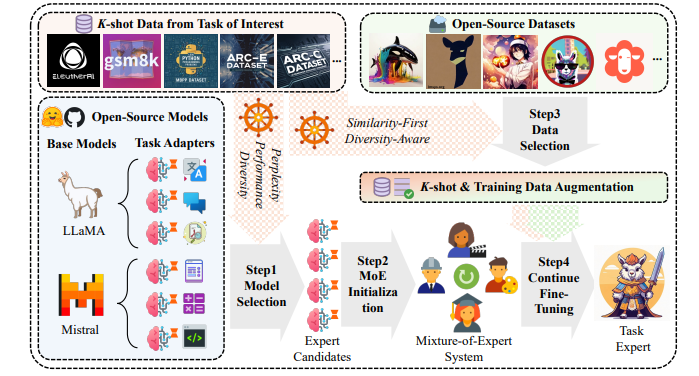
この研究の中核となるイノベーションは次のとおりです。
効率的なモデルの選択: 推論の複雑さ、モデルのパフォーマンス、知識の豊富さを包括的に評価することで、限られたデータ条件下で既存のモデルの可能性を最大化します。
知識抽出の最適化: 類似性と多様性のバランスをとったデータ スクリーニング戦略を通じて、オープンソース データから関連する知識を抽出する方法を設計し、過剰適合のリスクを軽減しながらモデルに補足情報を提供します。
適応モデルシステム:ハイブリッドエキスパートモデル構造に基づく適応システムは、複数の効果的なモデル間の知識補完を実現し、全体的なパフォーマンスを向上させるために構築されます。
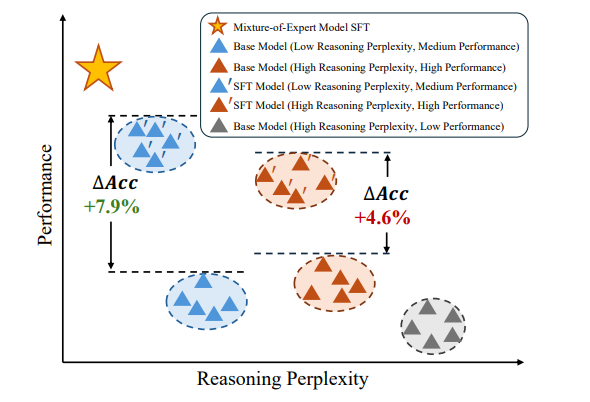
実験段階で、研究チームは 6 つのオープンソース データセットを使用して包括的な評価を実施しました。結果は、この新しい方法がさまざまなタスクにおいてベースラインや他の最先端の方法よりも優れていることを示しています。この研究では、専門家の活性化パターンを視覚化することで、各専門家のモデルへの貢献が不可欠であることもわかり、この手法の有効性がさらに確認されました。
この研究は、大規模モデルの分野におけるオープンソースの知識の大きな可能性を実証するだけでなく、人工知能技術の将来の開発に新しいアイデアを提供します。従来のモデル最適化の限界を打ち破り、限られたリソースの下でモデルのパフォーマンスを向上させるための実現可能なソリューションを企業や研究機関に提供します。
このテクノロジーは改良と促進が続けられているため、さまざまな業界のインテリジェントなアップグレードにおいて重要な役割を果たすと考える理由があります。 Tencent Youtu と上海交通大学のこの協力は、学術界と産業界の協力モデルであるだけでなく、人工知能技術をより高いレベルに推進するための重要なステップでもあります。
論文アドレス: https://www.arxiv.org/pdf/2408.15915
この研究結果は、大規模モデルの最適化に対する新しいアイデアと実現可能な解決策を提供するものであり、実用化に大きな可能性を秘めており、今後のさらなる応用と開発が期待されます。 Downcodes の編集者は、この分野の最新の開発に今後も注目し、読者にさらに刺激的なレポートをお届けしていきます。