baichuan Qlora Tuning
1.0.0
จาก Qlora คำแนะนำนั้นได้รับการปรับแต่งอย่างละเอียดสำหรับโมเดลขนาดใหญ่ของ Baichuan-7b
mpi4py
transformers == 4.28 . 1
peft == 0.3 . 0
icetk
deepspeed == 0.9 . 2
accelerate
cpm_kernels
sentencepiece == 0.1 . 99
peft = 0.3 . 0
torch = 2.0 . 0 เวอร์ชันล่าสุดก็โอเค
--data
----msra
------train.txt
------eval.txt
--checkpoint
----baichuan
------adapter_model
--model_hub
----baichuan-7B
--baichuan_qlora.py # 训练
--dataset.py # 处理数据
--predict.py # 交互式闲聊
--test_baichuan.py # 测试baichuan模型
--train.log # 训练日志
รูปแบบข้อมูลใน train.txt และ eval.txt เหมือนกันและแต่ละพฤติกรรมเป็นตัวอย่างซึ่งเป็นพิเศษ:
{ "instruct" : "你现在是一个实体识别模型,你需要提取文本里面的人名、地名、机构名,如果存在结果,返回'实体_实体类型',不同实体间用n分隔。如果没有结果,回答'没有'。" , "query" : "文本:因有关日寇在京掠夺文物详情,藏界较为重视,也是我们收藏北京史料中的要件之一。" , "answer" : "日_地名n京_地名n北京_地名" }คำแนะนำคือคำแนะนำการสืบค้นคือข้อความและคำตอบคือผลลัพธ์ มันสามารถสร้างขึ้นได้ด้วยตัวเองตามข้อมูลของคุณเอง
ชื่อของทั้งสามคอลัมน์สามารถกำหนดได้ใน baichuan_qlora.py
ไปที่หน้ากอดเพื่อดาวน์โหลดไฟล์ที่เกี่ยวข้องของ Baichuan-7b ถึง model_hub/baichuan-7b หลังจากการดาวน์โหลดเสร็จสมบูรณ์คุณสามารถใช้ python test_baichuan.pt เพื่อทดสอบโมเดล หลังจากสร้างชุดข้อมูลให้เรียกใช้โดยตรง:
python baichaun_qlora . py หลังจากการฝึกอบรมเสร็จสมบูรณ์คุณสามารถใช้คำแนะนำต่อไปนี้เพื่อทำการคาดการณ์:
python predict . py - - model_name "baichuan" - - base_model "./model_hub/baichuan-7B" - - tokenizer_path "./model_hub/baichuan-7B" - - lora_model "./checkpoint/baichuan/adapter_model" - - with_prompt - - interactiveผลการทำนาย:
加载模型耗时: 0.6068947672843933分钟
loading peft model
Start inference with instruction mode .
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
+ 当前使用的模型是: baichuan
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
+ 该模式下仅支持单轮问答,无多轮对话能力。
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
Input :你现在是一个实体识别模型,你需要提取文本里面的人名、地名、机构名,如果存在结果,返回'实体_实体类型' ,不同实体间用n分隔。如果没有结果,回答'没有' 。文本:我们是受到郑振铎先生、阿英先生著作的启示,从个人条件出发,瞄准现代出版史研究的空白,重点集藏解放区、国民党毁禁出版物。
Response : 郑振铎_人名
阿英_人名
Input :你现在是一个实体识别模型,你需要提取文本里面的人名、地名、机构名,如果存在结果,返回'实体_实体类型' ,不同实体间用n分隔。如果没有结果,回答'没有' 。文本:藏书家、作家姜德明先生在1997年出版的书话专集《文林枝叶》中以“爱书的朋友”为题,详细介绍了我们夫妇的藏品及三口之家以书为友、好乐清贫的逸闻趣事。
Response : 姜德明_人名
Input :你现在是一个实体识别模型,你需要提取文本里面的人名、地名、机构名,如果存在结果,返回'实体_实体类型' ,不同实体间用n分隔。如果没有结果,回答'没有' 。文本:去年,我们又被评为“北京市首届家庭藏书状元明星户”。
Response : 北京_地名มันมีเอฟเฟกต์บางอย่าง แต่ก็ไม่ค่อยดี อาจต้องมีการปรับพารามิเตอร์และการฝึกอบรมเป็นเวลานาน
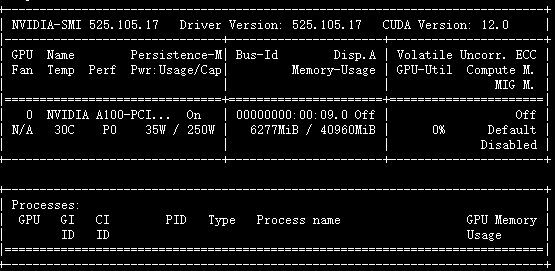
หน่วยความจำวิดีโอที่คาดการณ์:
https://github.com/wp931120/baichuan_sft_lora
https://github.com/baichuan-inc/baichuan-7b
https://github.com/artidoro/qlora/
https://github.com/taishan1994/qlora-chinese-llm


