baichuan Qlora Tuning
1.0.0
Com base em Qlora, as instruções são ajustadas para o modelo Big Big Baichuan-7b.
mpi4py
transformers == 4.28 . 1
peft == 0.3 . 0
icetk
deepspeed == 0.9 . 2
accelerate
cpm_kernels
sentencepiece == 0.1 . 99
peft = 0.3 . 0
torch = 2.0 . 0 A versão mais recente está ok.
--data
----msra
------train.txt
------eval.txt
--checkpoint
----baichuan
------adapter_model
--model_hub
----baichuan-7B
--baichuan_qlora.py # 训练
--dataset.py # 处理数据
--predict.py # 交互式闲聊
--test_baichuan.py # 测试baichuan模型
--train.log # 训练日志
Os formatos de dados em Train.txt e Eval.txt são os mesmos, e cada comportamento é uma amostra, que é especificamente:
{ "instruct" : "你现在是一个实体识别模型,你需要提取文本里面的人名、地名、机构名,如果存在结果,返回'实体_实体类型',不同实体间用n分隔。如果没有结果,回答'没有'。" , "query" : "文本:因有关日寇在京掠夺文物详情,藏界较为重视,也是我们收藏北京史料中的要件之一。" , "answer" : "日_地名n京_地名n北京_地名" }Instruct é a instrução, a consulta é o texto e a resposta é o resultado. Pode ser construído por si só com base em seus próprios dados.
Os nomes dessas três colunas podem ser definidos em baichuan_qlora.py.
Vá para o rosto abraçado para baixar os arquivos relevantes de Baichuan-7b para Model_Hub/Baichuan-7b. Após a conclusão do download, você pode usar python test_baichuan.pt para testar o modelo. Depois de construir o conjunto de dados, execute -o diretamente:
python baichaun_qlora . py Após a conclusão do treinamento, você pode usar as seguintes instruções para fazer previsões:
python predict . py - - model_name "baichuan" - - base_model "./model_hub/baichuan-7B" - - tokenizer_path "./model_hub/baichuan-7B" - - lora_model "./checkpoint/baichuan/adapter_model" - - with_prompt - - interactiveResultados de previsão:
加载模型耗时: 0.6068947672843933分钟
loading peft model
Start inference with instruction mode .
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
+ 当前使用的模型是: baichuan
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
+ 该模式下仅支持单轮问答,无多轮对话能力。
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == =
Input :你现在是一个实体识别模型,你需要提取文本里面的人名、地名、机构名,如果存在结果,返回'实体_实体类型' ,不同实体间用n分隔。如果没有结果,回答'没有' 。文本:我们是受到郑振铎先生、阿英先生著作的启示,从个人条件出发,瞄准现代出版史研究的空白,重点集藏解放区、国民党毁禁出版物。
Response : 郑振铎_人名
阿英_人名
Input :你现在是一个实体识别模型,你需要提取文本里面的人名、地名、机构名,如果存在结果,返回'实体_实体类型' ,不同实体间用n分隔。如果没有结果,回答'没有' 。文本:藏书家、作家姜德明先生在1997年出版的书话专集《文林枝叶》中以“爱书的朋友”为题,详细介绍了我们夫妇的藏品及三口之家以书为友、好乐清贫的逸闻趣事。
Response : 姜德明_人名
Input :你现在是一个实体识别模型,你需要提取文本里面的人名、地名、机构名,如果存在结果,返回'实体_实体类型' ,不同实体间用n分隔。如果没有结果,回答'没有' 。文本:去年,我们又被评为“北京市首届家庭藏书状元明星户”。
Response : 北京_地名Tem certos efeitos, mas não é muito bom. Pode exigir ajuste de parâmetros e treinamento por mais tempo.
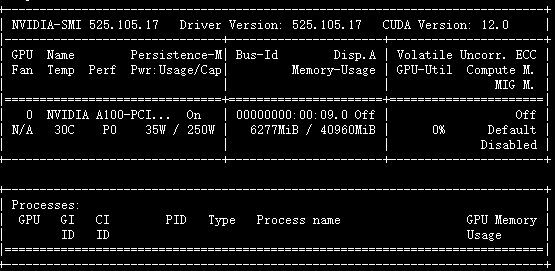
Memória de vídeo prevista:
https://github.com/wp931120/baichuan_sft_lora
https://github.com/baichuan-inc/baichuan-7b
https://github.com/artidoro/qlora/
https://github.com/taishan1994/qlora-chinese-llm


