ctrlora
1.0.0


ภาพถูกบีบอัดสำหรับความเร็วในการโหลด
Ctrlora: เฟรมเวิร์กที่ขยายได้และมีประสิทธิภาพสำหรับการสร้างภาพที่ควบคุมได้
Yifeng Xu 1,2 , Zhenliang HE 1 , Shiguang Shan 1,2 , Xilin Chen 1,2
1 ห้องปฏิบัติการสำคัญของ AI Safety, Institute of Computing Technology, CAS, China
2 มหาวิทยาลัยวิทยาศาสตร์แห่งมหาวิทยาลัยวิทยาศาสตร์จีน
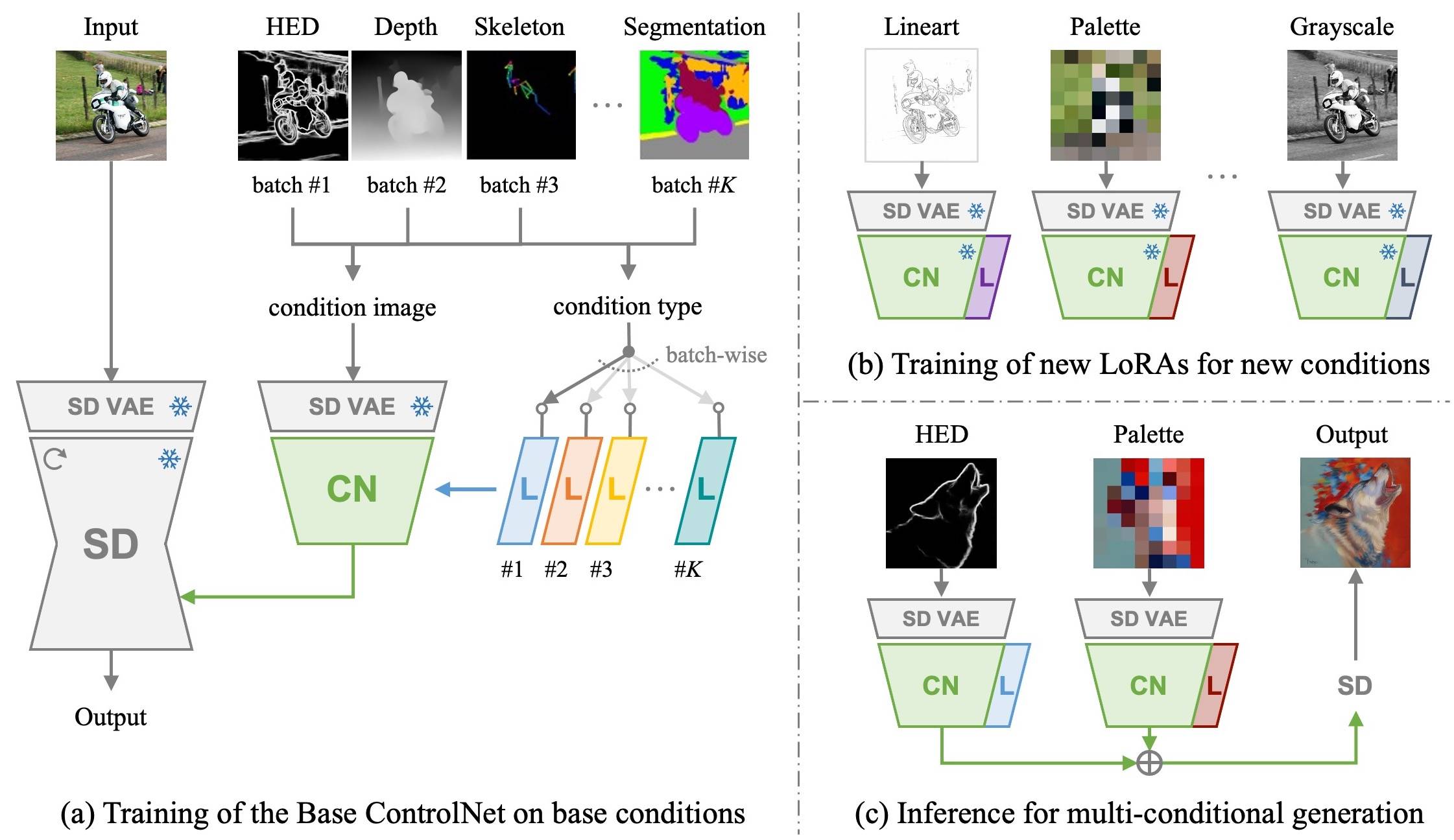
ก่อนอื่นเราฝึกอบรม ฐานควบคุมฐาน พร้อมกับ loras เฉพาะเงื่อนไข บนเงื่อนไขฐานด้วยชุดข้อมูลขนาดใหญ่ จากนั้นฐานควบคุมของเราสามารถปรับให้เข้ากับเงื่อนไขใหม่โดย New Loras ด้วย น้อยถึง 1,000 ภาพและน้อยกว่า 1 ชั่วโมงใน GPU เดียว -
 |
|---|
 |
|---|
 |
|---|
 |
|---|
โคลน repo นี้:
git clone --depth 1 https://github.com/xyfJASON/ctrlora.git
cd ctrloraสร้างและเปิดใช้งานสภาพแวดล้อม conda ใหม่:
conda create -n ctrlora python=3.10
conda activate ctrloraติดตั้ง pytorch และการพึ่งพาอื่น ๆ :
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
pip install -r requirements.txt เราให้แบบจำลองที่ผ่านการฝึกฝนของเราที่นี่ กรุณาใส่ ฐานควบคุม ( ctrlora_sd15_basecn700k.ckpt ) ลงใน ./ckpts/ctrlora-basecn ctrlora-basecn และ loras เข้าสู่ ./ckpts/ctrlora-loras ctrlora-loras อนุสัญญาการตั้งชื่อของ LORAS คือ ctrlora_sd15_<basecn>_<condition>.ckpt สำหรับเงื่อนไขพื้นฐานและ ctrlora_sd15_<basecn>_<condition>_<images>_<steps>.ckpt สำหรับเงื่อนไขใหม่
คุณต้องดาวน์โหลด โมเดลที่ใช้ SD1.5 และใส่ลงใน ./ckpts/sd15 ckpts/SD15 แบบจำลองที่ใช้ในงานของเรา:
v1-5-pruned.ckpt ): อย่างเป็นทางการ / กระจกpython app/gradio_ctrlora.pyต้องใช้ RAM GPU อย่างน้อย 9GB/21GB เพื่อสร้างภาพหนึ่ง/สี่ภาพ 512x512
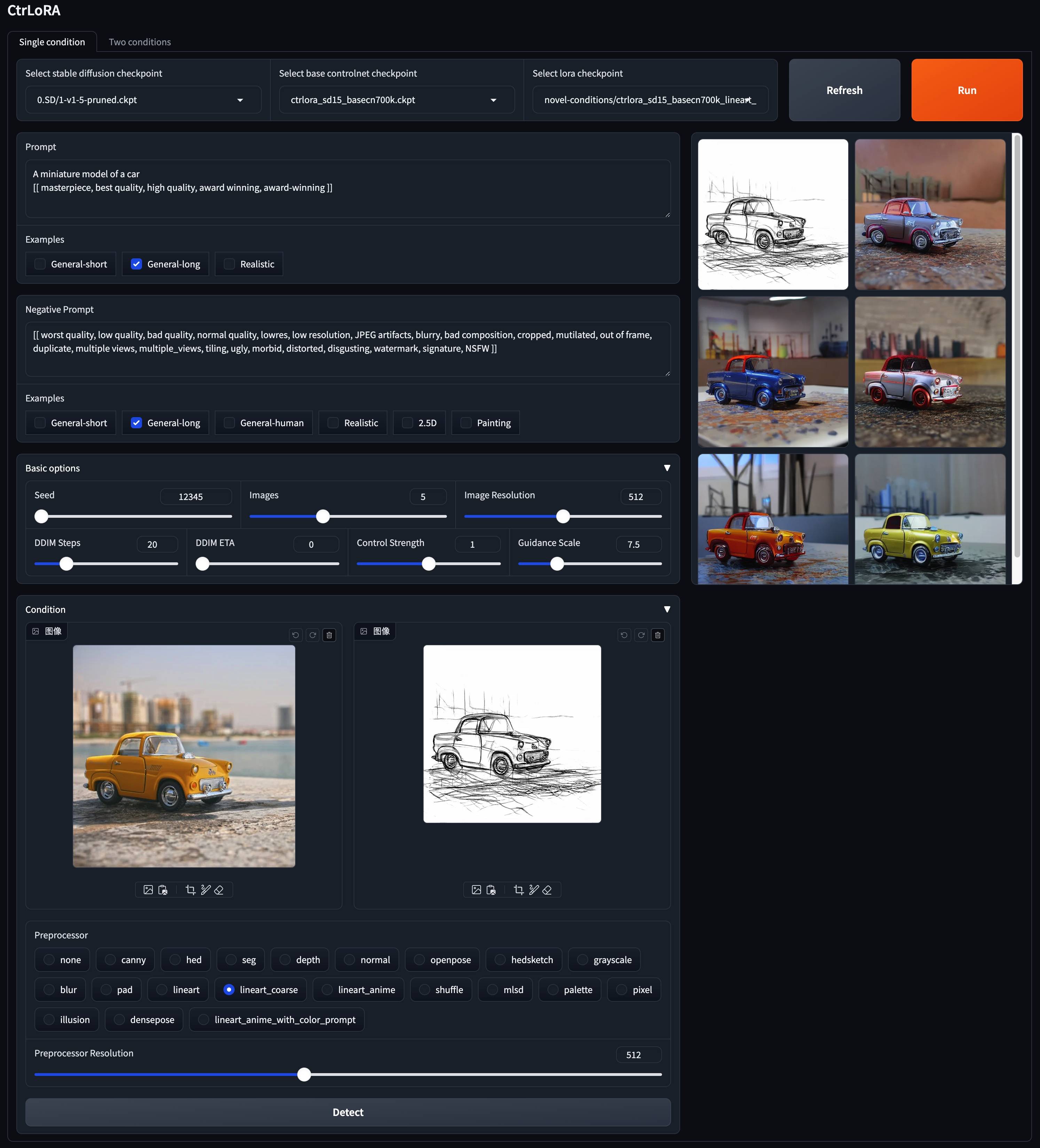
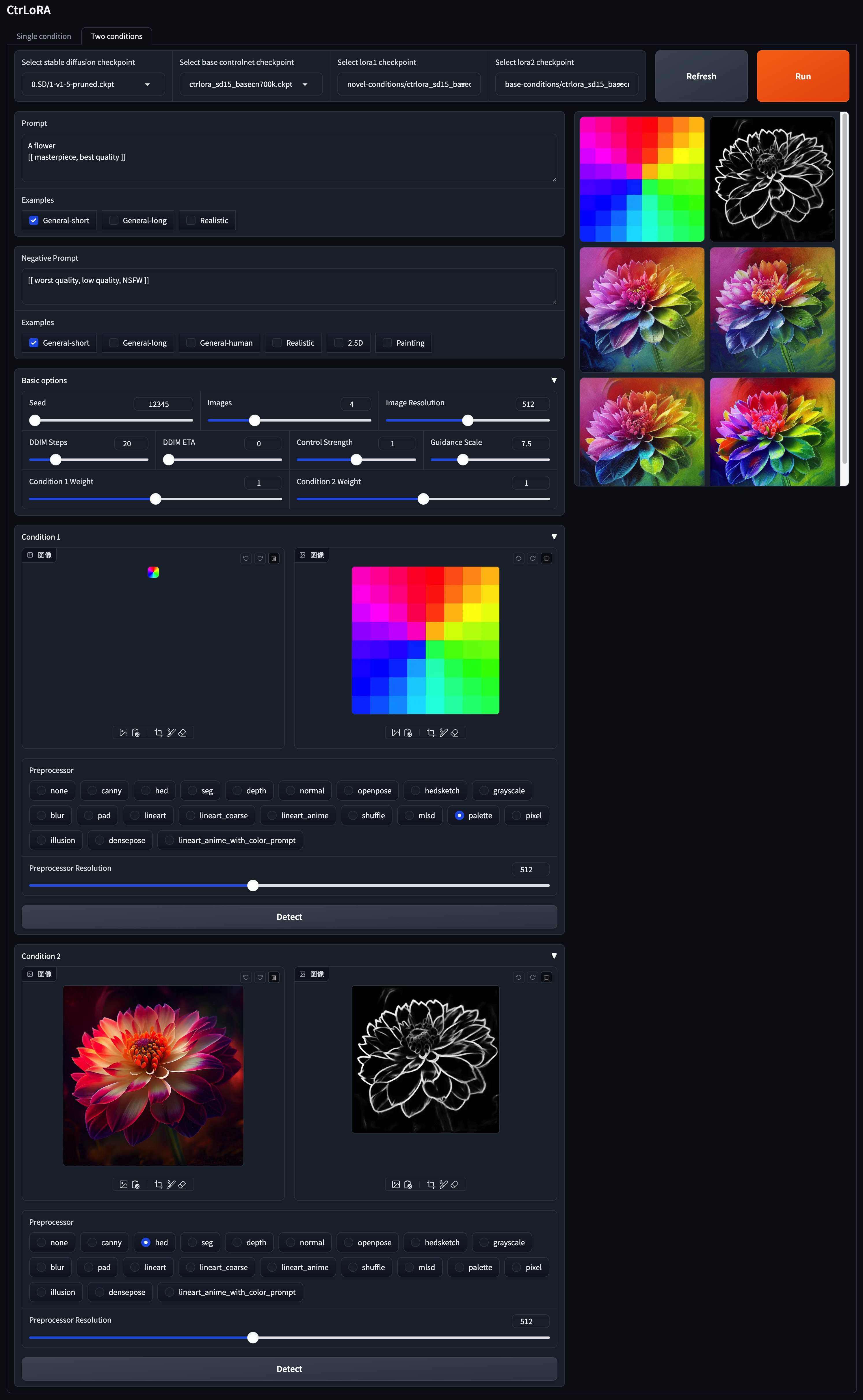
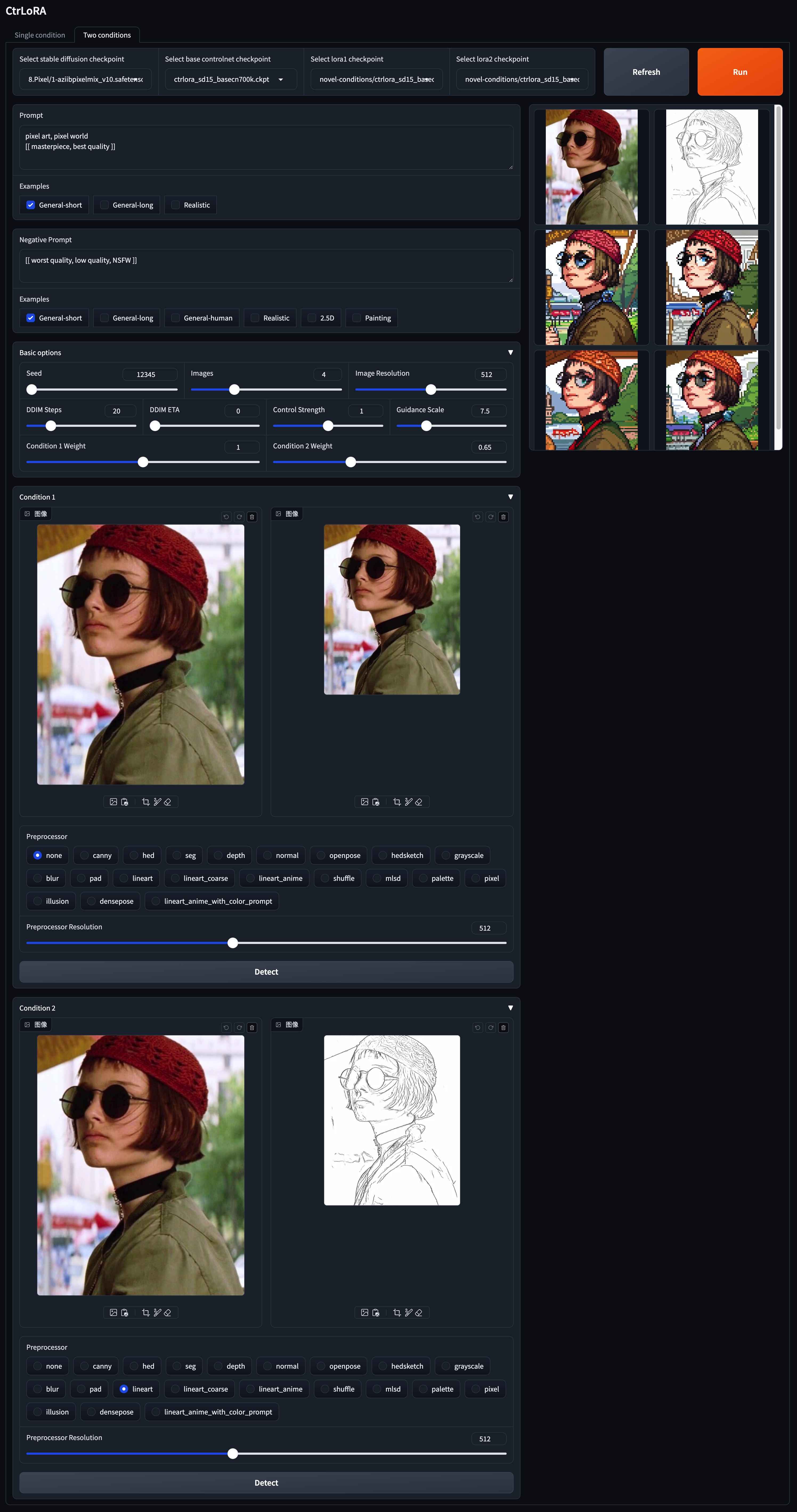
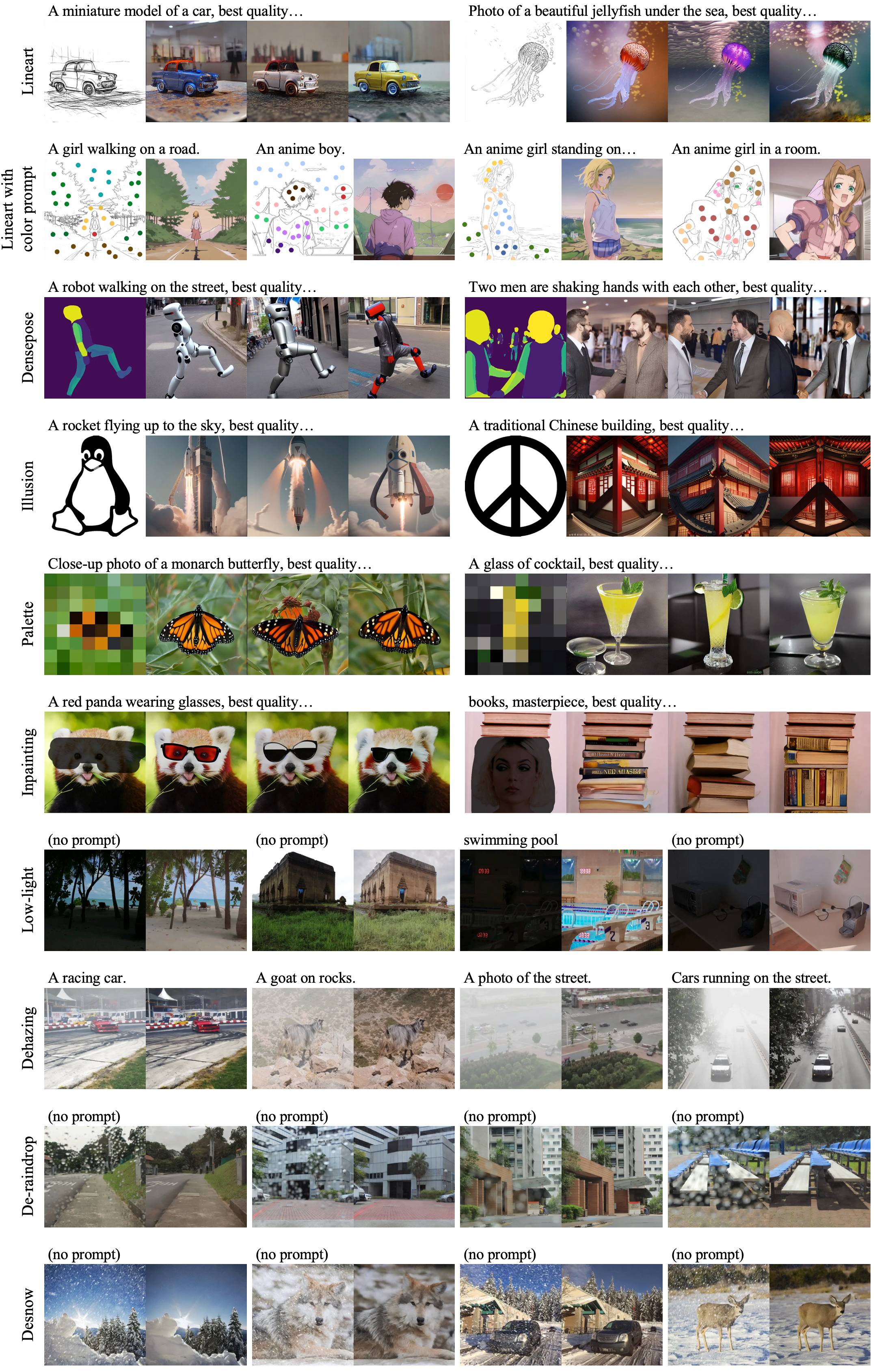
ขึ้นอยู่กับฐานควบคุมของเราคุณสามารถฝึกอบรม LORA สำหรับสภาพที่กำหนดเองของคุณด้วยภาพน้อยเพียง 1,000 ภาพและน้อยกว่า 1 ชั่วโมงใน GPU เดียว (20GB)
ก่อนอื่นให้ดาวน์โหลดการแพร่กระจายที่เสถียร v1.5 ( v1-5-pruned.ckpt ) ลงใน ./ckpts/sd15 และฐานควบคุม ( ctrlora_sd15_basecn700k.ckpt ) เข้าสู่ ./ckpts/ctrlora-basecn ctrlora-basecn ตามที่อธิบายไว้ข้างต้น
ประการที่สองใส่ข้อมูลที่กำหนดเองของคุณลงใน ./data/<custom_data_name> ด้วยโครงสร้างต่อไปนี้:
data
└── custom_data_name
├── prompt.json
├── source
│ ├── 0000.jpg
│ ├── 0001.jpg
│ └── ...
└── target
├── 0000.jpg
├── 0001.jpg
└── ...
source มามีภาพเงื่อนไขเช่นขอบกระป๋องแผนที่การแบ่งส่วนภาพความลึก ฯลฯtarget มีภาพความจริงพื้นดินที่สอดคล้องกับภาพเงื่อนไขprompt.json ควรทำตามรูปแบบเช่น {"source": "source/0000.jpg", "target": "target/0000.jpg", "prompt": "The quick brown fox jumps over the lazy dog."}ประการที่สามเรียกใช้คำสั่งต่อไปนี้เพื่อฝึก LORA สำหรับเงื่อนไขที่กำหนดเองของคุณ:
python scripts/train_ctrlora_finetune.py
--dataroot ./data/ < custom_data_name >
--config ./configs/ctrlora_finetune_sd15_rank128.yaml
--sd_ckpt ./ckpts/sd15/v1-5-pruned.ckpt
--cn_ckpt ./ckpts/ctrlora-basecn/ctrlora_sd15_basecn700k.ckpt
[--name NAME]
[--max_steps MAX_STEPS]--dataroot : เส้นทางไปยังข้อมูลที่กำหนดเอง--name : ชื่อของการทดลอง ไดเรกทอรีการบันทึกจะเป็น ./runs/name /name ค่าเริ่มต้น: เวลาปัจจุบัน--max_steps : จำนวนขั้นตอนการฝึกอบรมสูงสุด ค่าเริ่มต้น: 100000หลังจากการฝึกอบรมให้สกัดน้ำหนัก LORA ด้วยคำสั่งต่อไปนี้:
python scripts/tool_extract_weights.py -t lora --ckpt CHECKPOINT --save_path SAVE_PATH--ckpt : เส้นทางไปยังจุดตรวจที่ผลิตโดยการฝึกอบรมด้านบน--save_path : PATH เพื่อบันทึกน้ำหนัก LORA ที่แยกออกมา ในที่สุดใส่ lora ที่สกัดลงใน ./ckpts/ctrlora-loras ctrlora-loras และใช้ในการสาธิต Gradio
โปรดดูคำแนะนำที่นี่สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับการฝึกอบรมการปรับแต่งและการประเมินผล
โครงการนี้สร้างขึ้นจากการแพร่กระจายที่มั่นคงการควบคุมและ unicontrol ขอบคุณสำหรับการทำงานที่ยอดเยี่ยม!
หากคุณพบว่าโครงการนี้มีประโยชน์โปรดพิจารณาอ้าง:
@article { xu2024ctrlora ,
title = { CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation } ,
author = { Xu, Yifeng and He, Zhenliang and Shan, Shiguang and Chen, Xilin } ,
journal = { arXiv preprint arXiv:2410.09400 } ,
year = { 2024 }
}

