ctrlora
1.0.0


Las imágenes están comprimidas para la velocidad de carga.
Ctrlora: un marco extensible y eficiente para la generación de imágenes controlables
Yifeng Xu 1,2 , Zhenliang He 1 , Shiguang Shan 1,2 , Xilin Chen 1,2
1 Laboratorio clave de seguridad de IA, Instituto de Tecnología de Computación, CAS, China
2 Academia de Ciencias de la Universidad de China, China
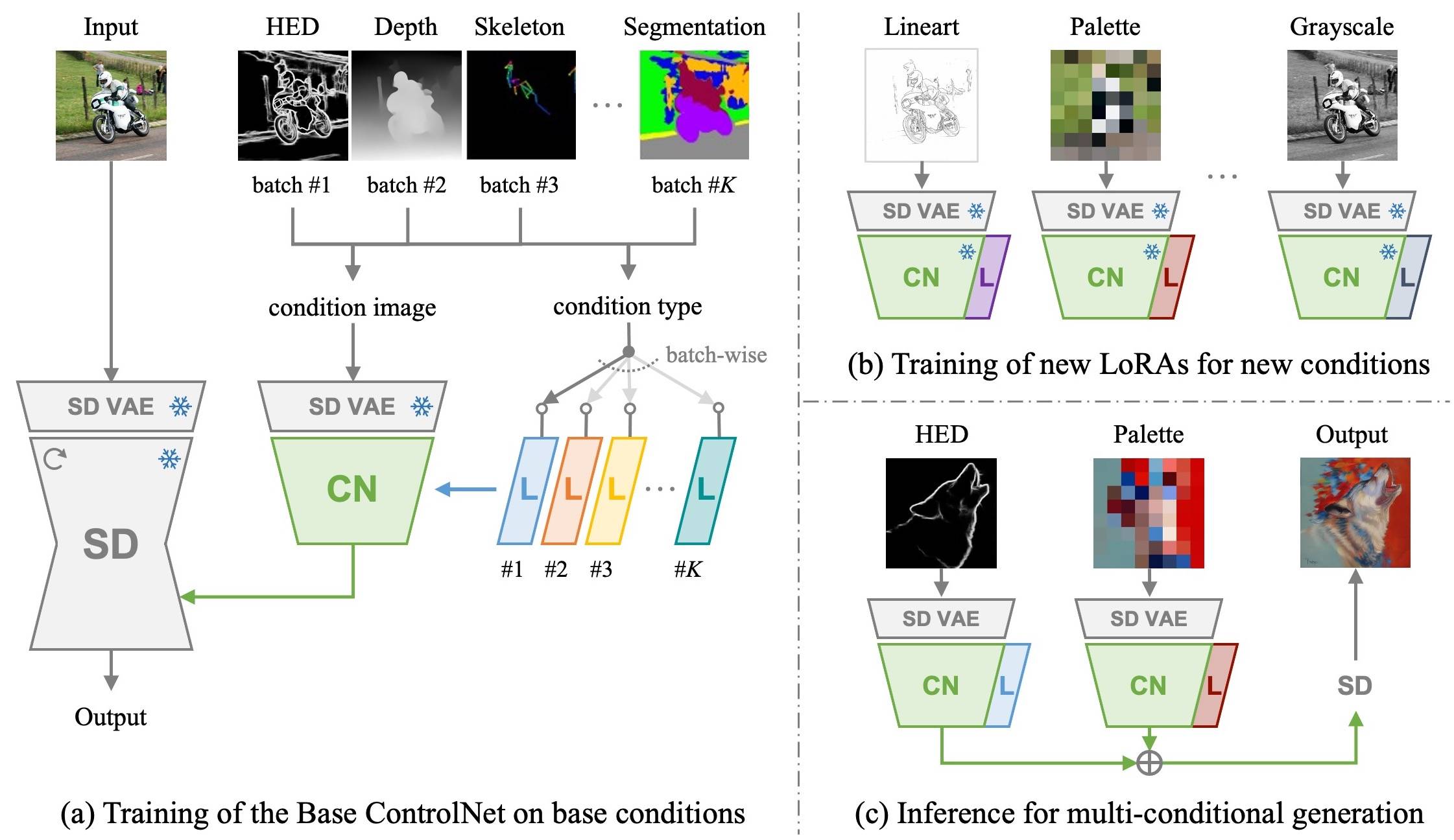
Primero entrenamos una red de control base junto con loras específicas de condición en condiciones base con un conjunto de datos a gran escala. Luego, nuestra red base se puede adaptar de manera eficiente a condiciones novedosas por las nuevas loras con tan solo 1,000 imágenes y menos de 1 hora en una sola GPU .
 |
|---|
 |
|---|
 |
|---|
 |
|---|
Clon este repositorio:
git clone --depth 1 https://github.com/xyfJASON/ctrlora.git
cd ctrloraCrear y activar un nuevo entorno de condena:
conda create -n ctrlora python=3.10
conda activate ctrloraInstale Pytorch y otras dependencias:
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
pip install -r requirements.txt Proporcionamos nuestros modelos previos a la aparición aquí. Por favor, coloque el control base ( ctrlora_sd15_basecn700k.ckpt ) en ./ckpts/ctrlora-basecn y loras en ./ckpts/ctrlora-loras . La convención de nombres de LORAS es ctrlora_sd15_<basecn>_<condition>.ckpt para condiciones base y ctrlora_sd15_<basecn>_<condition>_<images>_<steps>.ckpt para condiciones novedosas.
También debe descargar los modelos basados en SD1.5 y ponerlos en ./ckpts/sd15 . Modelos utilizados en nuestro trabajo:
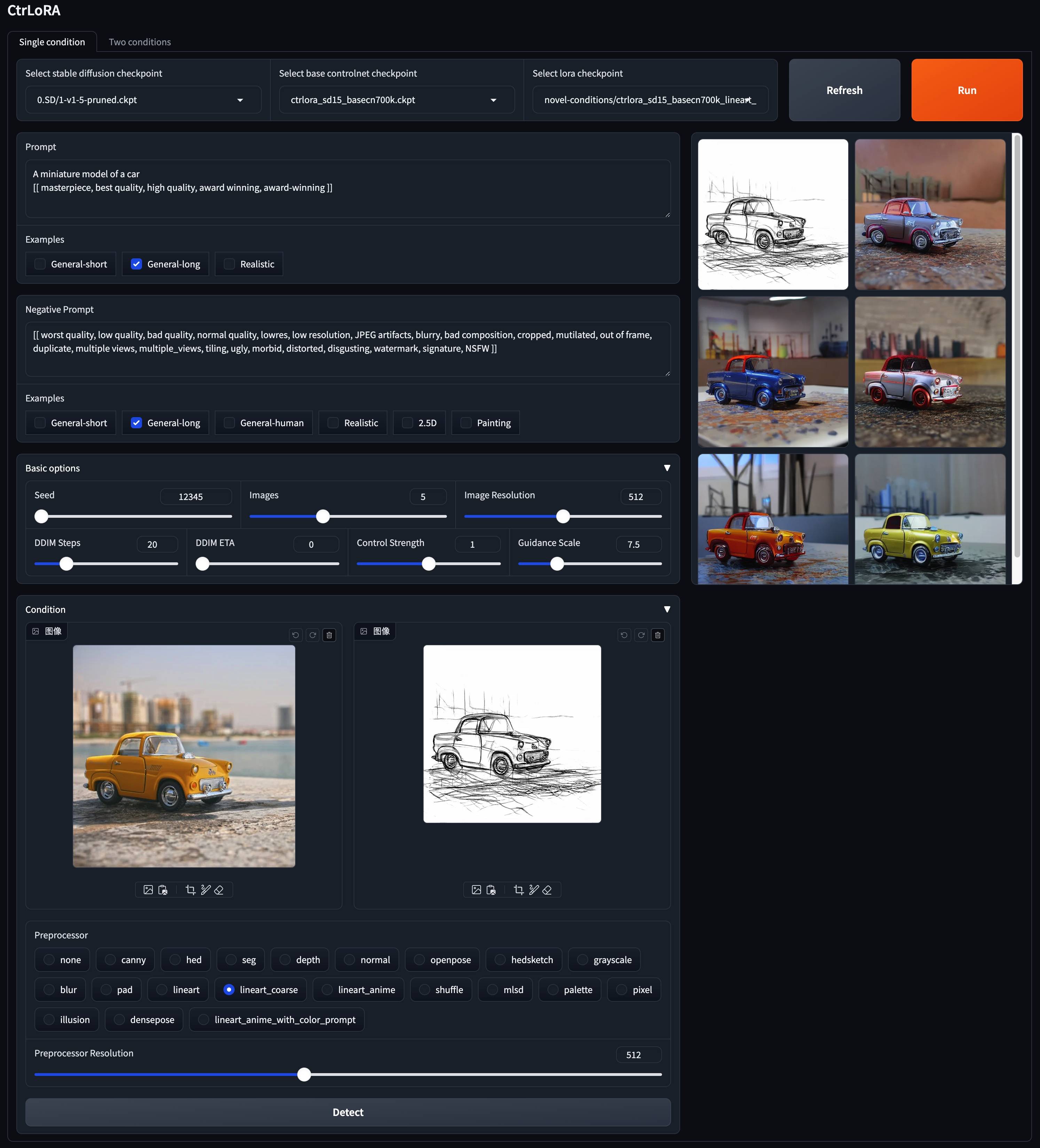
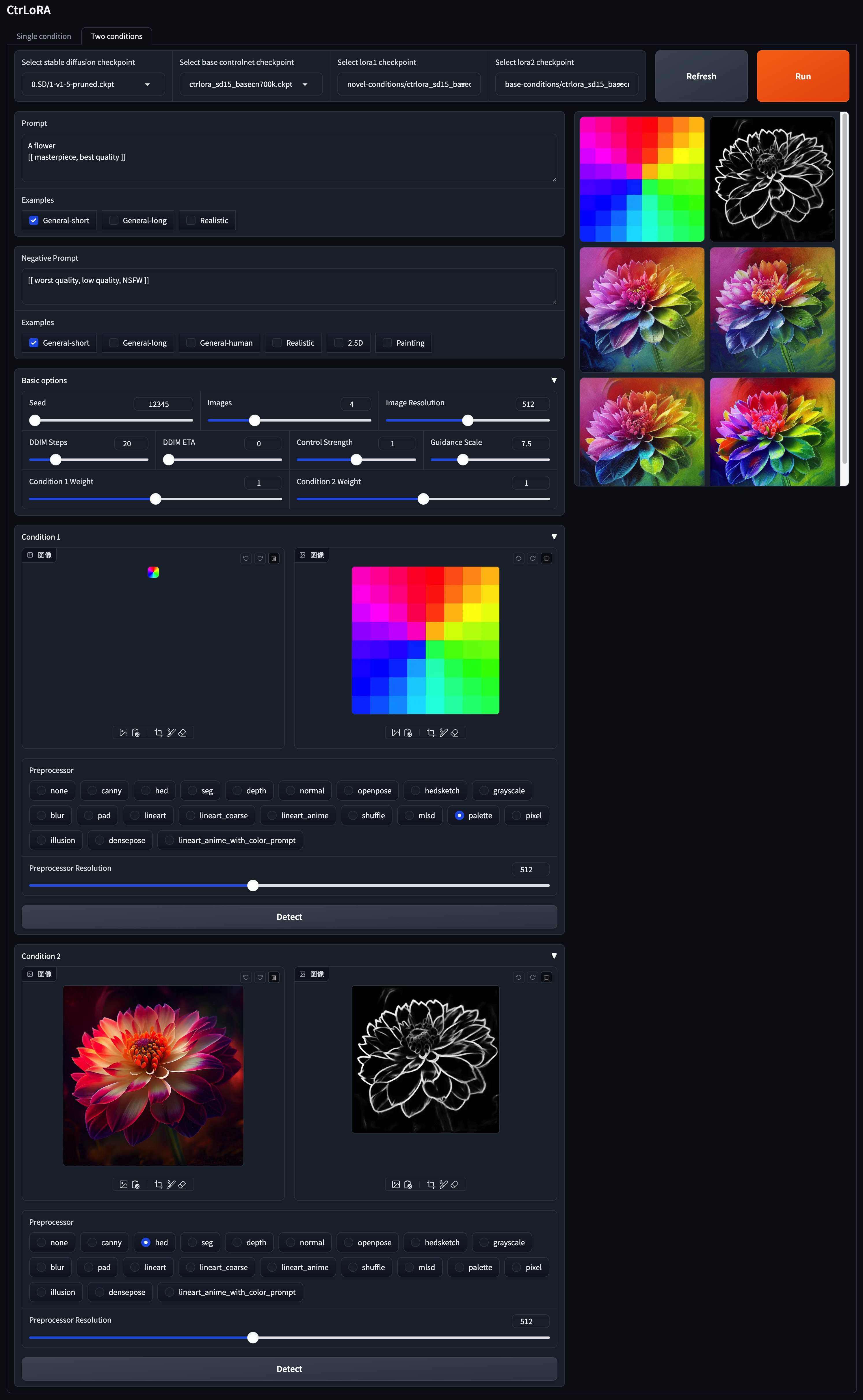
v1-5-pruned.ckpt ): Oficial / Mirrorpython app/gradio_ctrlora.pyRequiere al menos 9GB/21 GP GPU RAM para generar un lote de una/cuatro imágenes 512x512.
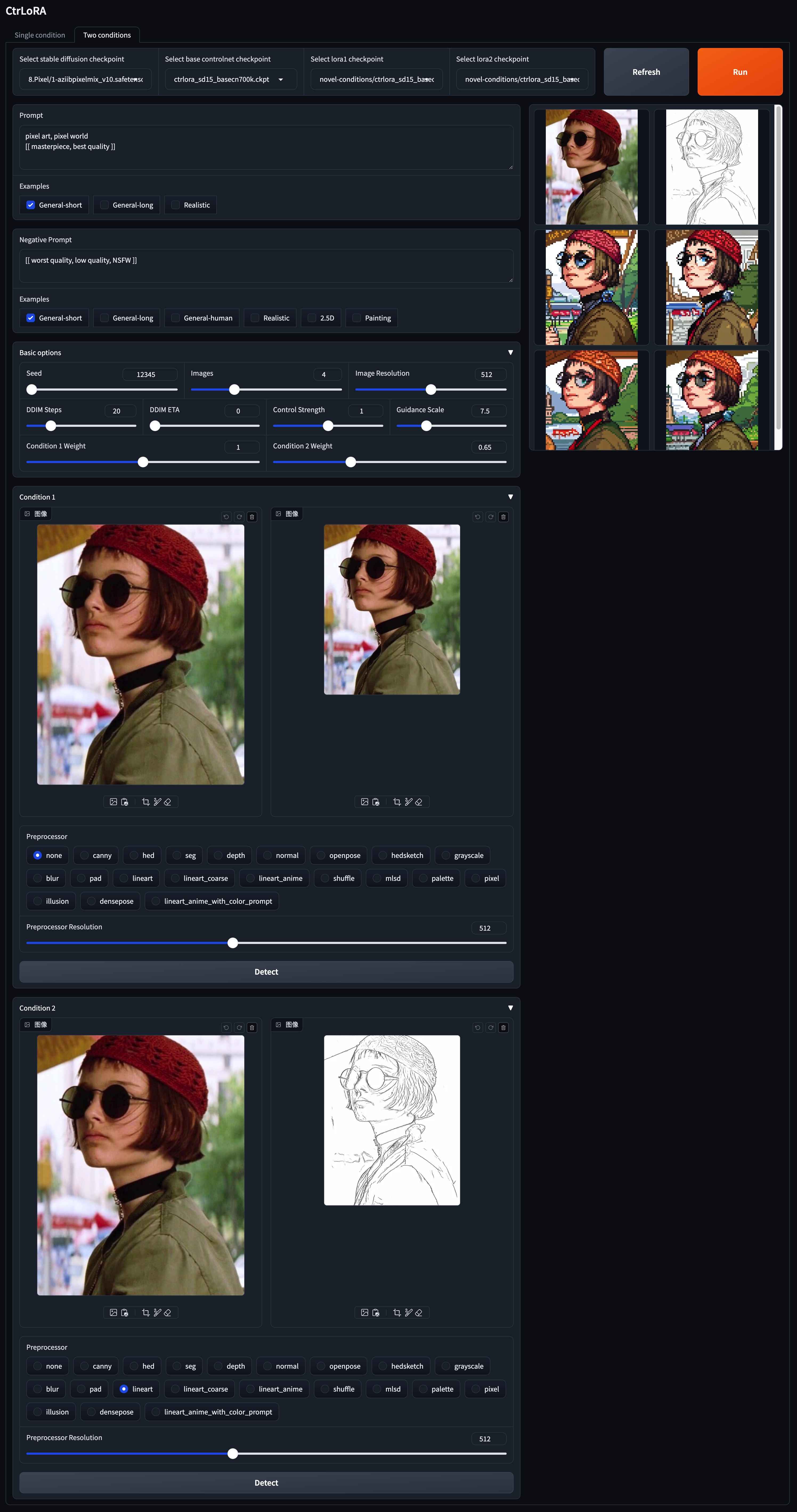
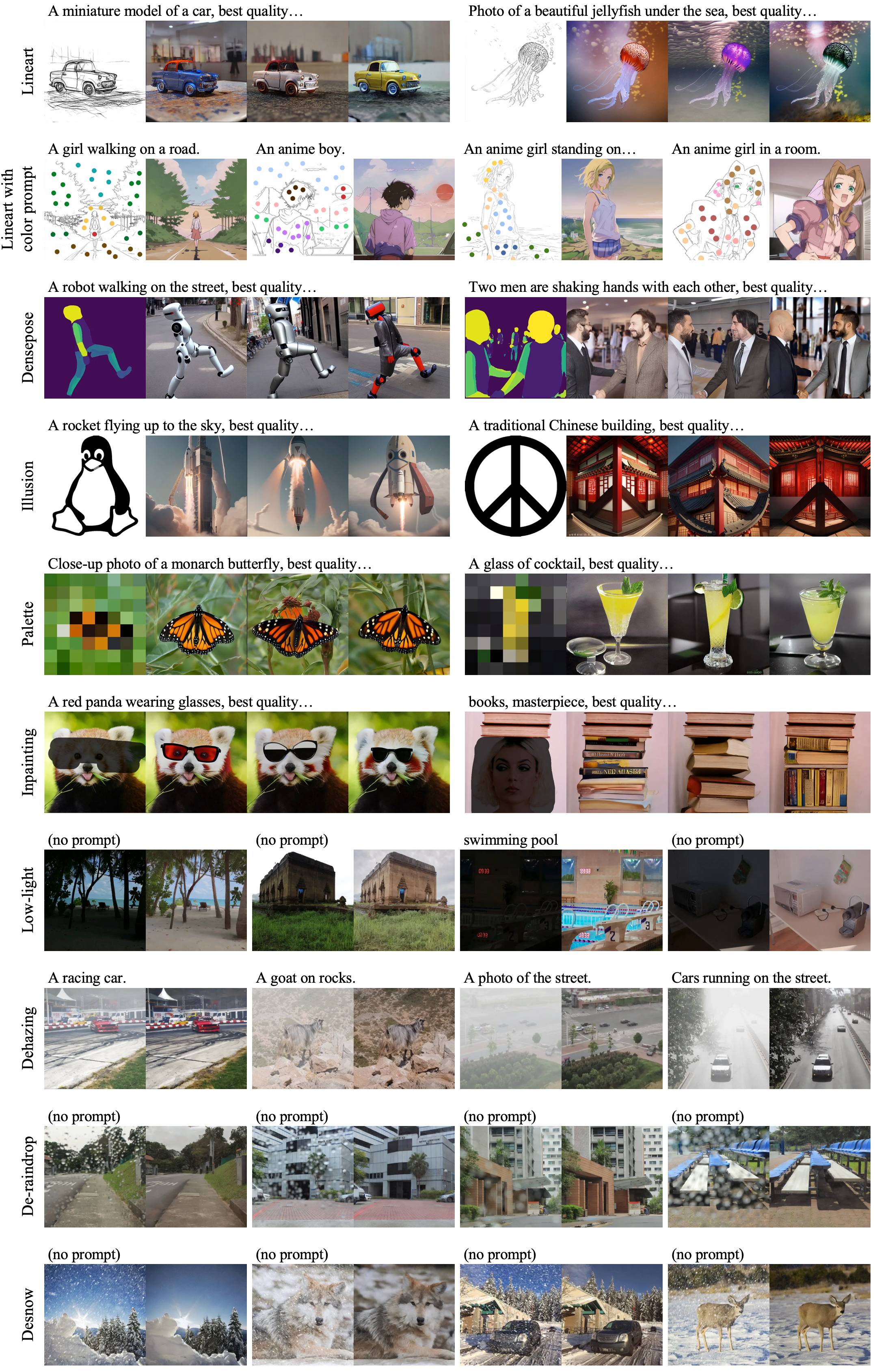
Basado en nuestra base base, puede entrenar un lora para su condición personalizada con tan solo 1,000 imágenes y menos de 1 hora en una sola GPU (20 GB).
Primero, descargue la difusión estable v1.5 ( v1-5-pruned.ckpt ) en ./ckpts/sd15 y el control base ( ctrlora_sd15_basecn700k.ckpt ) en ./ckpts/ctrlora-basecn como se describió anteriormente.
En segundo lugar, coloque sus datos personalizados en ./data/<custom_data_name> con la siguiente estructura:
data
└── custom_data_name
├── prompt.json
├── source
│ ├── 0000.jpg
│ ├── 0001.jpg
│ └── ...
└── target
├── 0000.jpg
├── 0001.jpg
└── ...
source contiene imágenes de condición, como bordes canales, mapas de segmentación, imágenes de profundidad, etc.target contiene imágenes de verdad en tierra correspondientes a las imágenes de condición.prompt.json debe seguir el formato como {"source": "source/0000.jpg", "target": "target/0000.jpg", "prompt": "The quick brown fox jumps over the lazy dog."}Tercero, ejecute el siguiente comando para entrenar la Lora para su condición personalizada:
python scripts/train_ctrlora_finetune.py
--dataroot ./data/ < custom_data_name >
--config ./configs/ctrlora_finetune_sd15_rank128.yaml
--sd_ckpt ./ckpts/sd15/v1-5-pruned.ckpt
--cn_ckpt ./ckpts/ctrlora-basecn/ctrlora_sd15_basecn700k.ckpt
[--name NAME]
[--max_steps MAX_STEPS]--dataroot : ruta a los datos personalizados.--name : nombre del experimento. El directorio de registro será ./runs/name . Valor predeterminado: hora actual.--max_steps : número máximo de pasos de entrenamiento. Valor predeterminado: 100000 .Después del entrenamiento, extraiga los pesos de Lora con el siguiente comando:
python scripts/tool_extract_weights.py -t lora --ckpt CHECKPOINT --save_path SAVE_PATH--ckpt : Ruta al punto de control producido por el entrenamiento anterior.--save_path : ruta para guardar los pesos de lora extraídos. Finalmente, coloque el Lora extraído en ./ckpts/ctrlora-loras y úselo en la demostración de Gradio.
Consulte las instrucciones aquí para obtener más detalles de capacitación, ajuste y evaluación.
Este proyecto se basa en difusión, control de control y unicontrol estables. ¡Gracias por su gran trabajo!
Si encuentra útil este proyecto, considere citar:
@article { xu2024ctrlora ,
title = { CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation } ,
author = { Xu, Yifeng and He, Zhenliang and Shan, Shiguang and Chen, Xilin } ,
journal = { arXiv preprint arXiv:2410.09400 } ,
year = { 2024 }
}

