cost2fitness
1.0.0
แพ็คเกจ PYPI สำหรับค่าต้นทุนการแปลง (น้อยกว่าดีกว่า) สำหรับค่าการออกกำลังกาย (มากกว่านั้นดีกว่า) และในทางกลับกัน
pip install cost2fitness
นี่คือแพ็คเกจที่มีหลายวิธีสำหรับการแปลงอาร์เรย์ NumPy ขึ้นอยู่กับเครื่องชั่งค่าเฉลี่ยและอื่น ๆ แต่วิธีหลักในการใช้คือการแปลงจากค่าต้นทุน (น้อยกว่า) ไปยังค่าความฟิต (มากกว่านั้นดีกว่า) และในทางกลับกัน มันจะเป็นประโยชน์อย่างมากเมื่อคุณใช้
มีหม้อแปลงง่ายๆหลายตัว แต่ละหม้อแปลงเป็นคลาสย่อยของคลาส BaseTransformer ที่มีฟิลด์ name และวิธี transform(array) ซึ่งแปลงอาร์เรย์อินพุตเป็นการแสดงใหม่
รายการตรวจสอบ:
ReverseByAverageAntiMaxAntiMaxPercent(percent)Min2ZeroMin2Value(value)ProbabilityView (แปลงข้อมูลเป็นความน่าจะเป็น)SimplestReverseAlwaysOnes (ส่งคืนอาร์เรย์ของคน)NewAvgByMult(new_average) ,NewAvgByShift(new_average)Divider(divider_number_or_array) (หารอาร์เรย์ตามหมายเลขหรืออาร์เรย์มีประโยชน์สำหรับการเริ่มต้นเริ่มต้นใหม่)Argmax (ส่งคืนตำแหน่งขององค์ประกอบสูงสุดในอาร์เรย์)Prob2Class(threshold = 0.5) (เพื่อแปลงความน่าจะเป็นเป็นคลาส 0/1)ToNumber (แปลงอาร์เรย์เป็นหมายเลขหนึ่งโดยรับองค์ประกอบแรก)คุณสามารถสร้างหม้อแปลงของคุณโดยใช้ตรรกะง่าย ๆ จากไฟล์
import numpy as np
from cost2fitness import Min2Zero
tf = Min2Zero ()
arr_of_scores = np . array ([ 10 , 8 , 7 , 5 , 8 , 9 , 20 , 12 , 6 , 18 ])
tf . transform ( arr_of_scores )
# array([ 5, 3, 2, 0, 3, 4, 15, 7, 1, 13]) คุณยังสามารถรวมหม้อแปลงเหล่านี้โดยใช้ Pl Pipeline ตัวอย่างเช่น:
import numpy as np
from cost2fitness import ReverseByAverage , AntiMax , Min2Zero , Pl
pipe = Pl ([
Min2Zero (),
ReverseByAverage (),
AntiMax ()
])
arr_of_scores = np . array ([ 10 , 8 , 7 , 5 , 8 , 9 ])
# return each result of pipeline transformation (with input)
pipe . transform ( arr_of_scores , return_all_steps = True )
#array([[10. , 8. , 7. , 5. , 8. ,
# 9. ],
# [ 5. , 3. , 2. , 0. , 3. ,
# 4. ],
# [ 0.66666667, 2.66666667, 3.66666667, 5.66666667, 2.66666667,
# 1.66666667],
# [ 5. , 3. , 2. , 0. , 3. ,
# 4. ]])
# return only result of transformation
pipe . transform ( arr_of_scores , return_all_steps = False )
#array([5., 3., 2., 0., 3., 4.]) มีฟังก์ชั่น plot_scores สำหรับการพล็อตผลลัพธ์กระบวนการแปลง มันมีข้อโต้แย้ง:
scores : 2d numpy array 2d numpy array ที่มีโครงสร้าง [start_values, first_transform(start_values), second_transform(first_transform), ...] โดยที่แต่ละวัตถุเป็น 1D-Array ของคะแนน (ค่า/ค่าใช้จ่าย/ฟิตเนส)names : None /รายการสตริงชื่อเสริมสำหรับแต่ละขั้นตอนสำหรับป้ายกำกับพล็อต ค่าเริ่มต้นคือ Nonekind : STR, ตัวเลือกสำหรับ 'ข้าง' คอลัมน์ใหม่แต่ละคอลัมน์จะอยู่ข้างๆก่อนหน้า; สำหรับ 'Under' จะมีพล็อตใหม่ภายใต้ก่อนหน้านี้ ค่าเริ่มต้นคือ 'ข้าง'save_as : None /str, เส้นทางไฟล์เสริมเพื่อบันทึกพล็อต ค่าเริ่มต้นคือ None รหัส
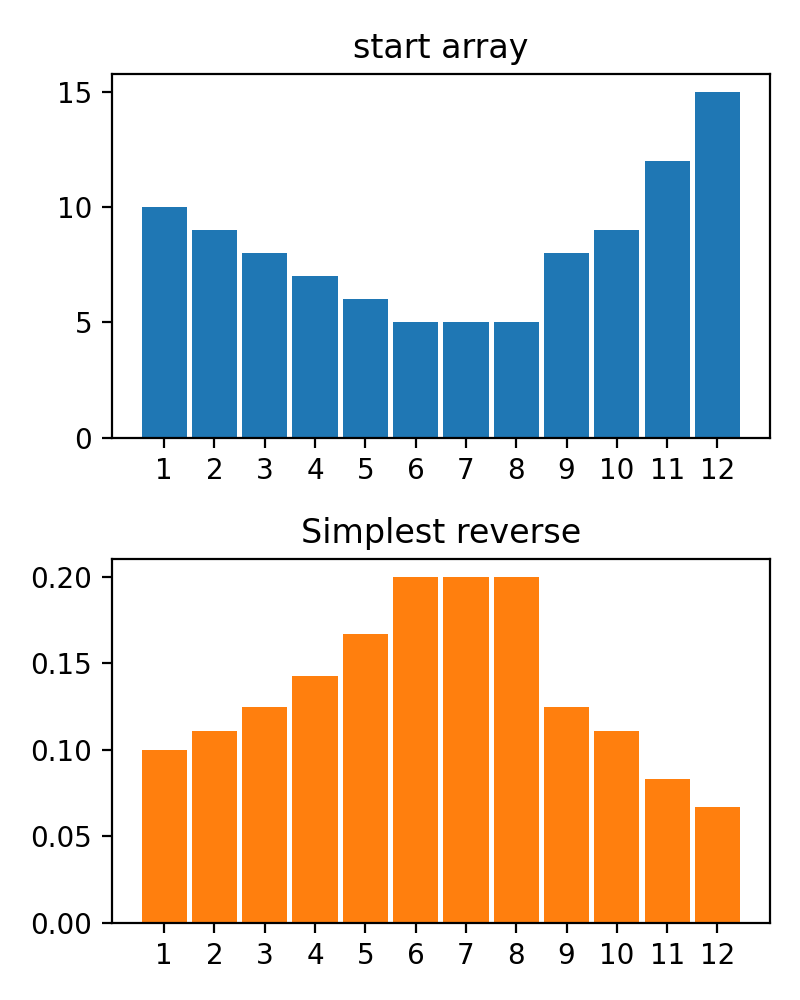
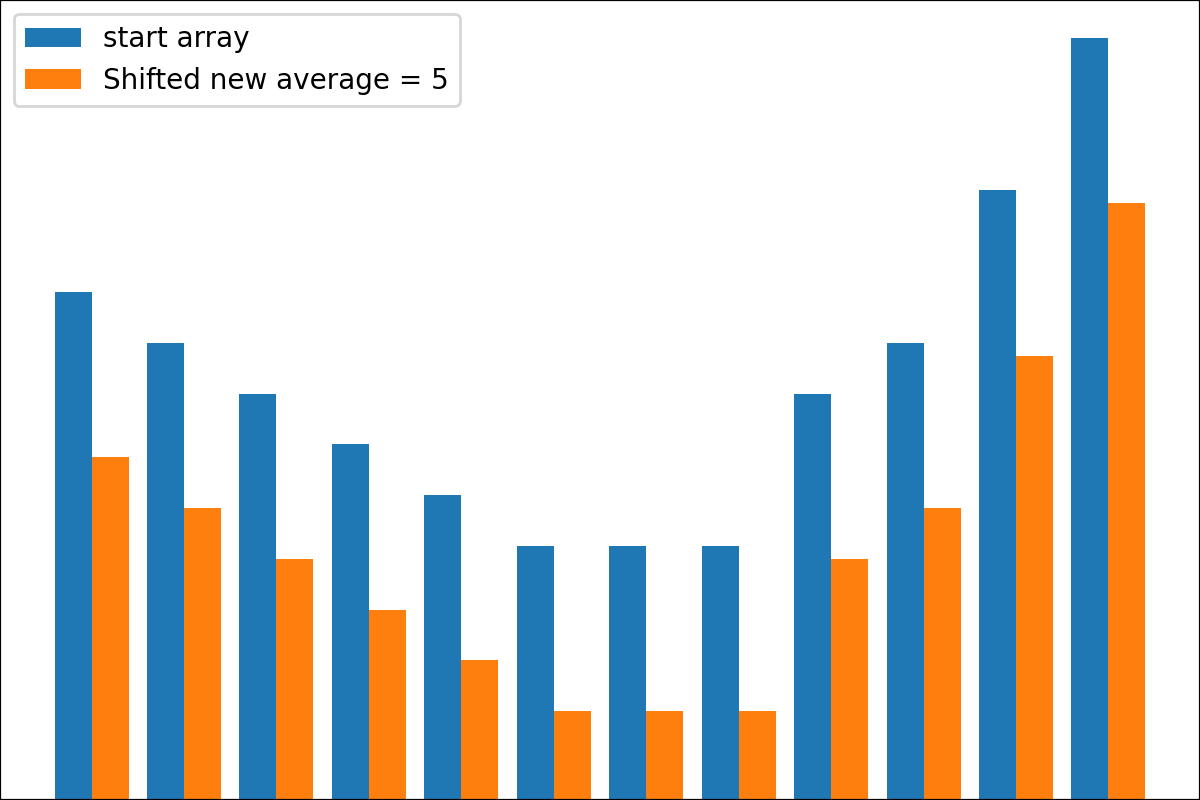
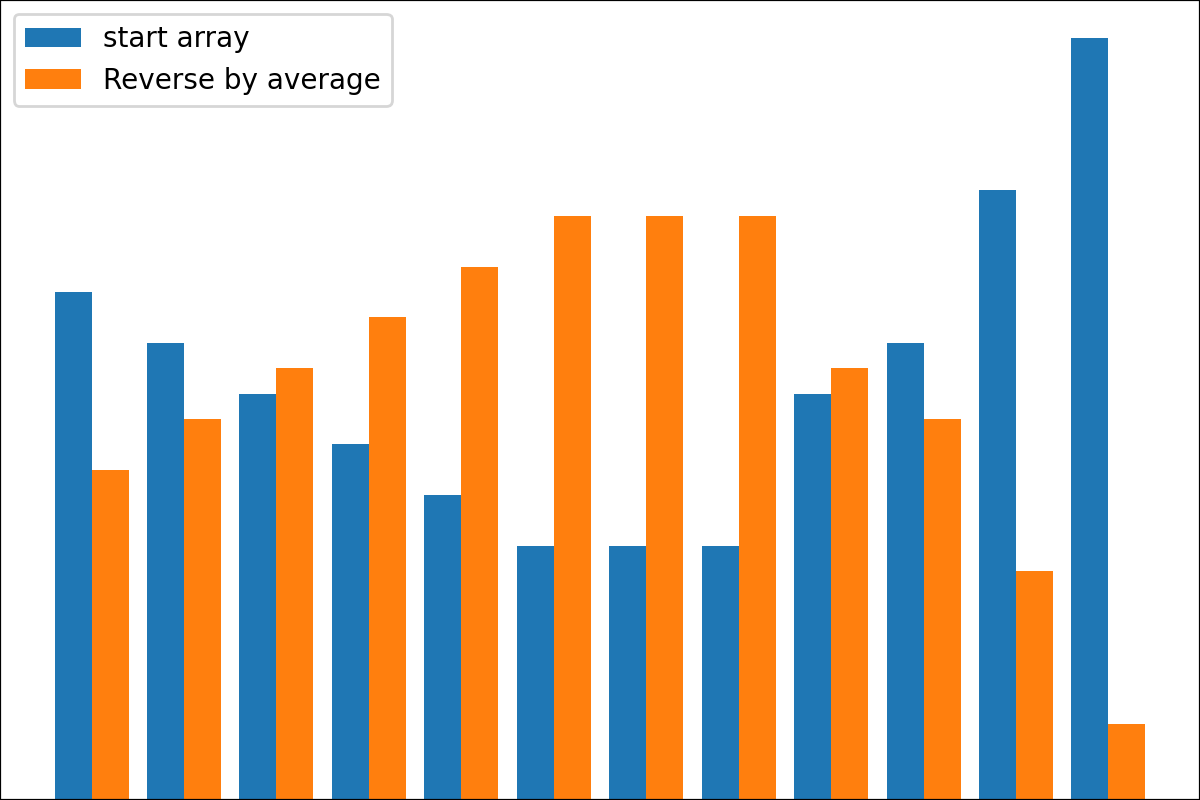
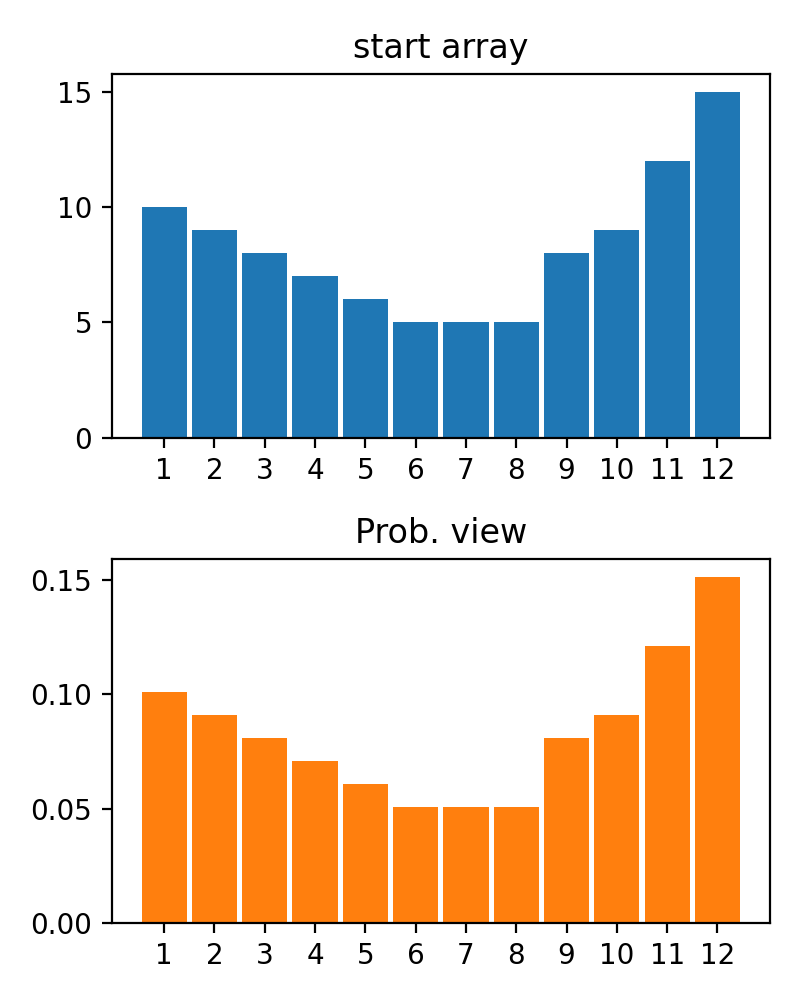
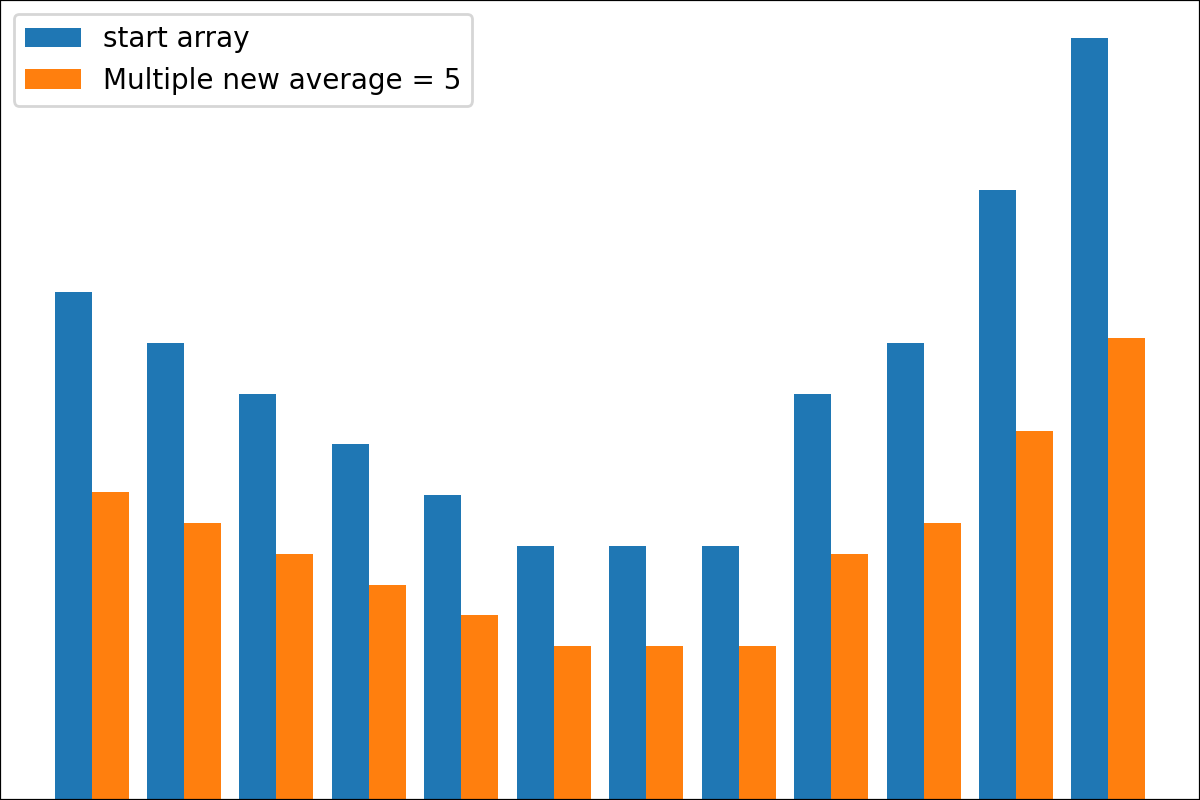
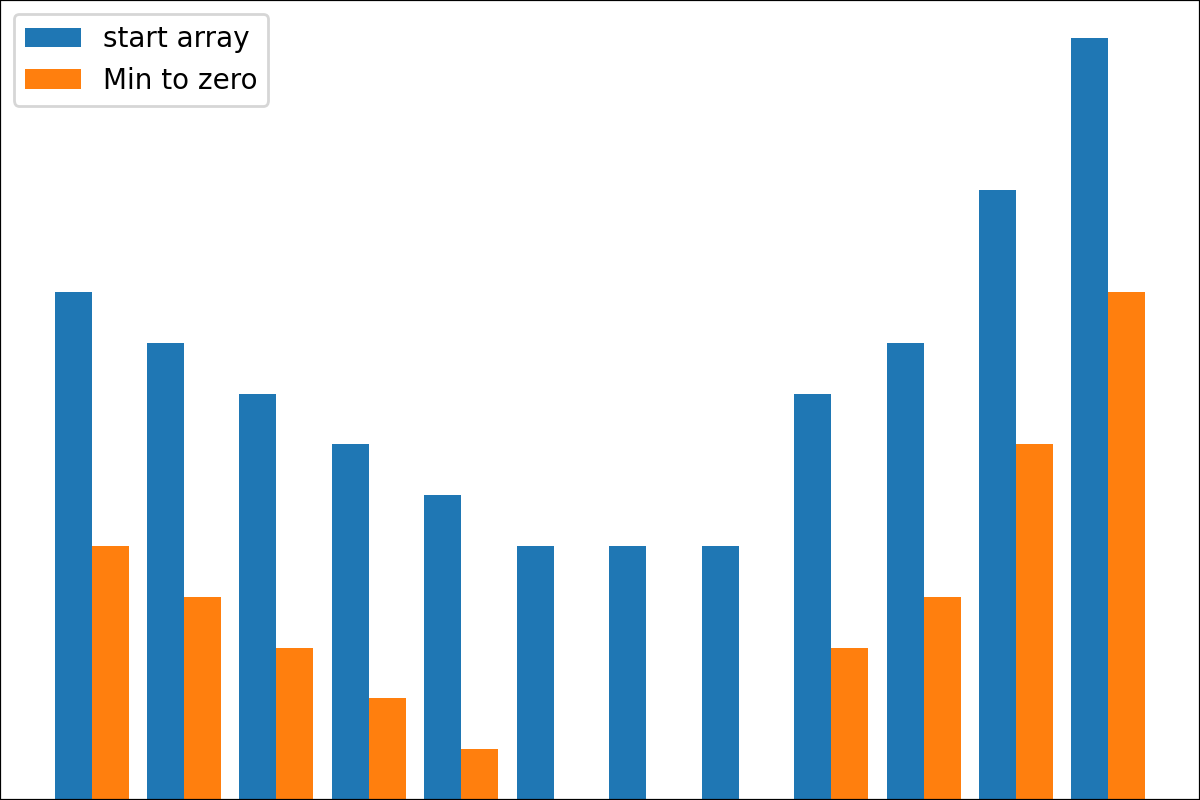
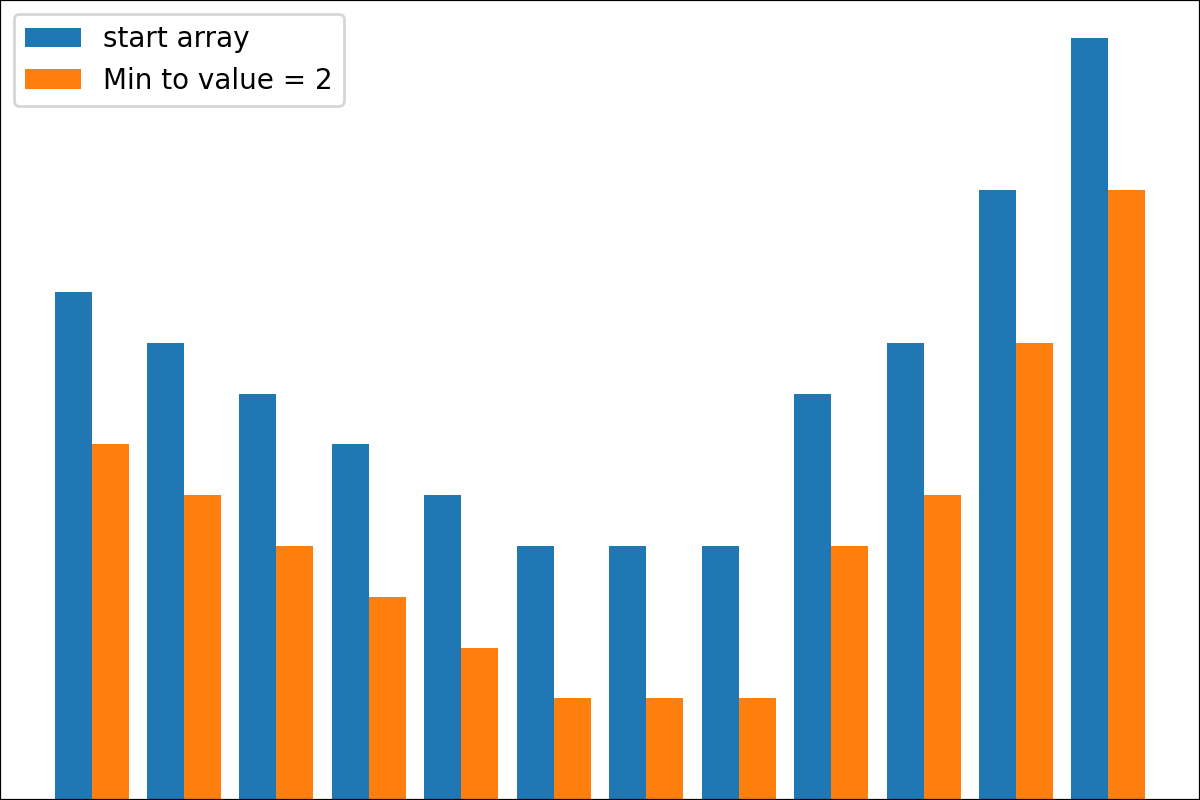
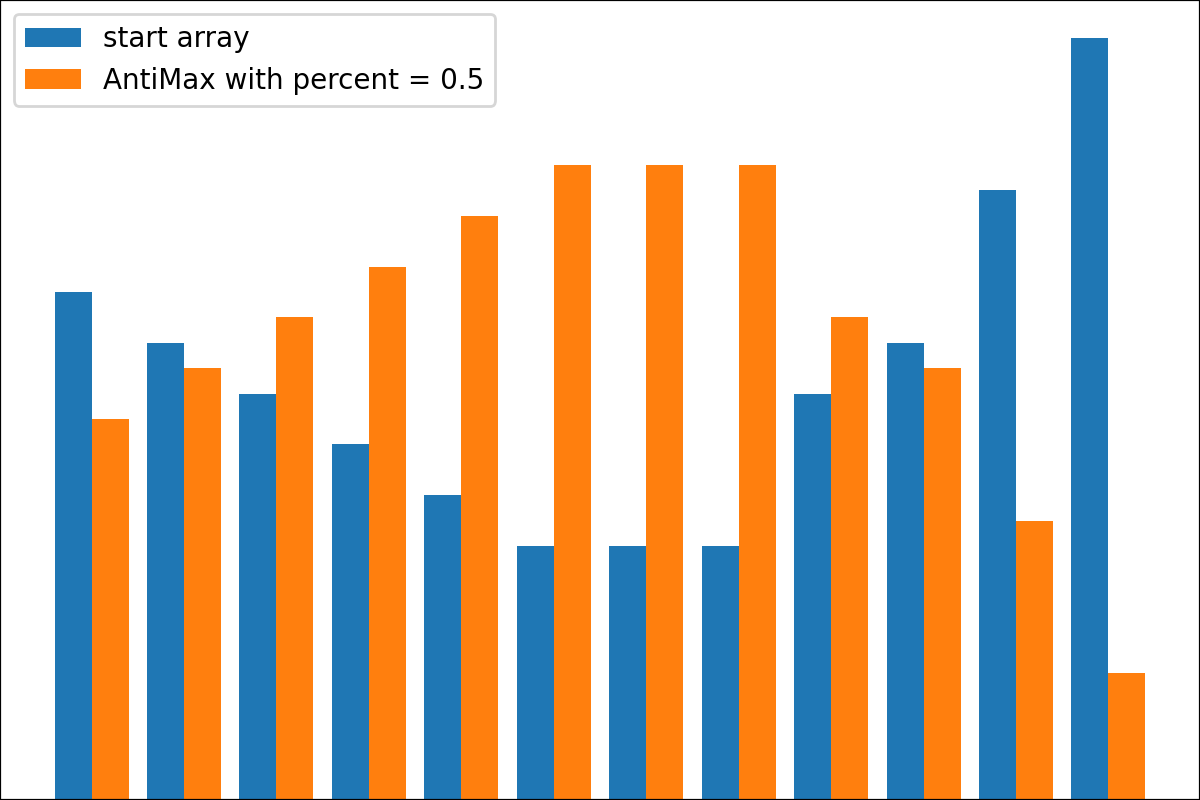
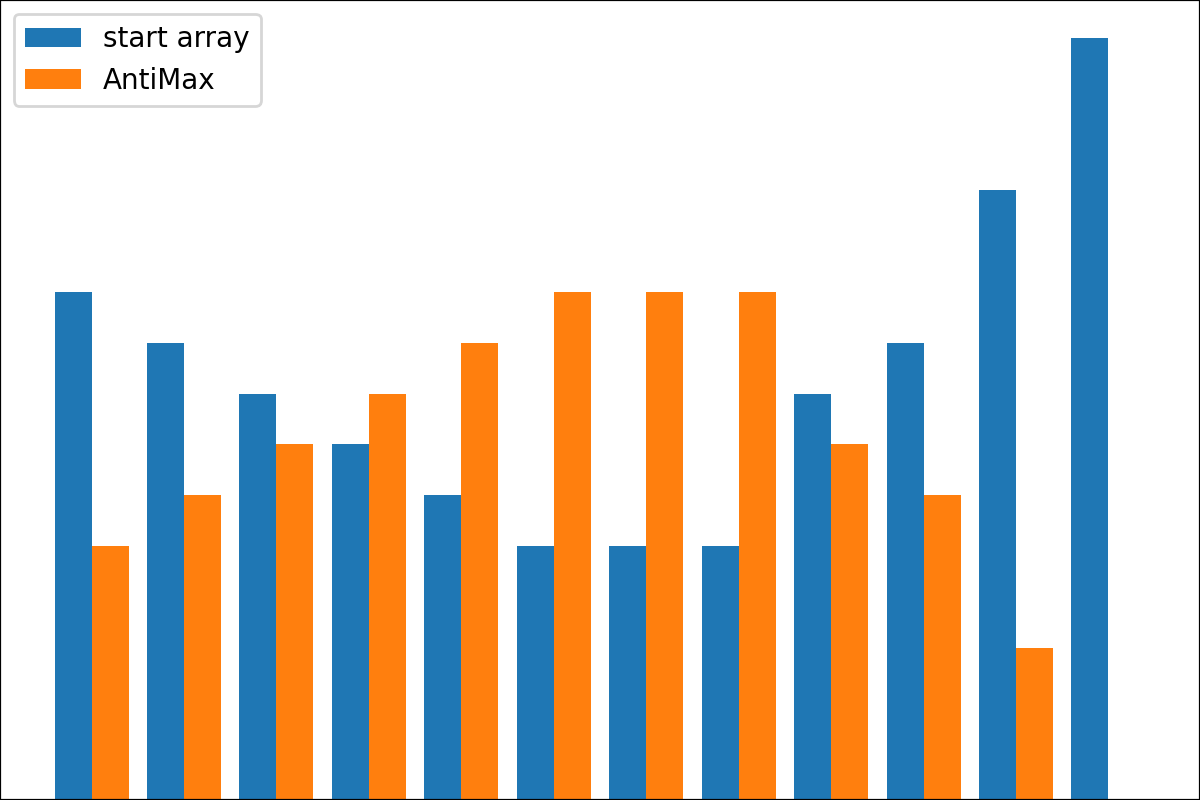
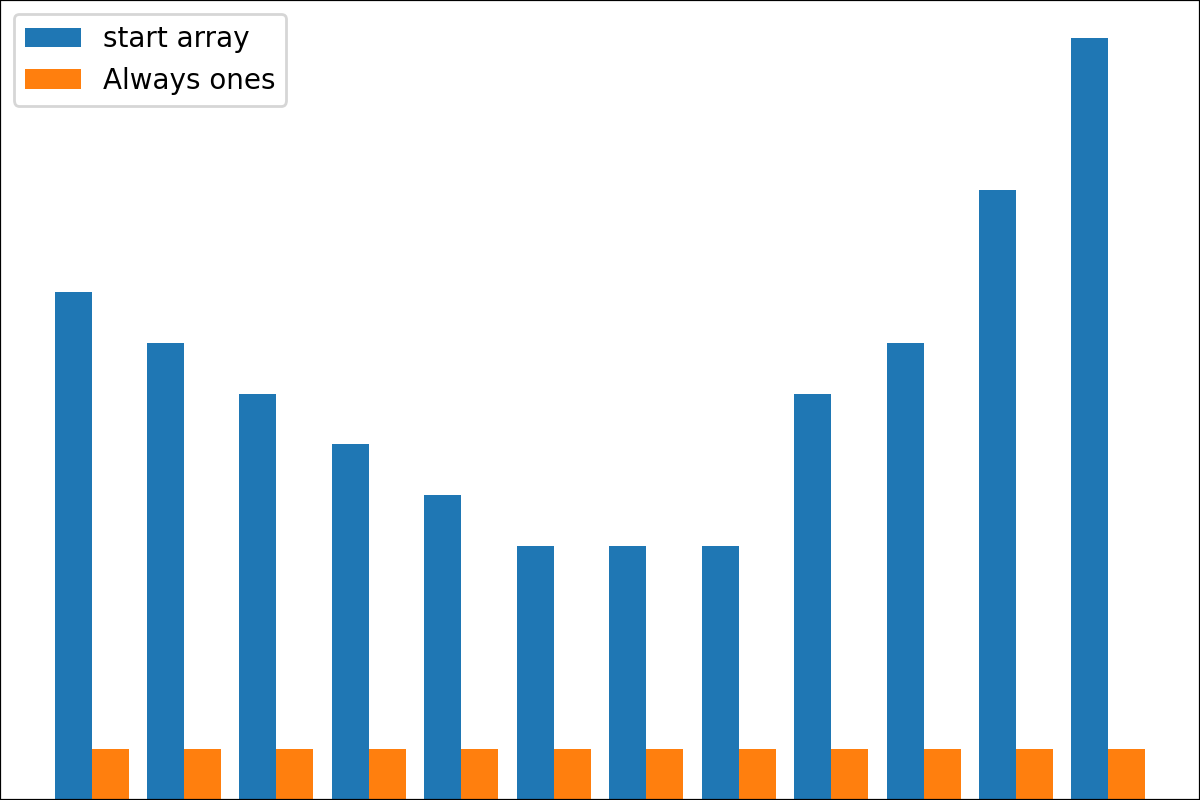
รหัส
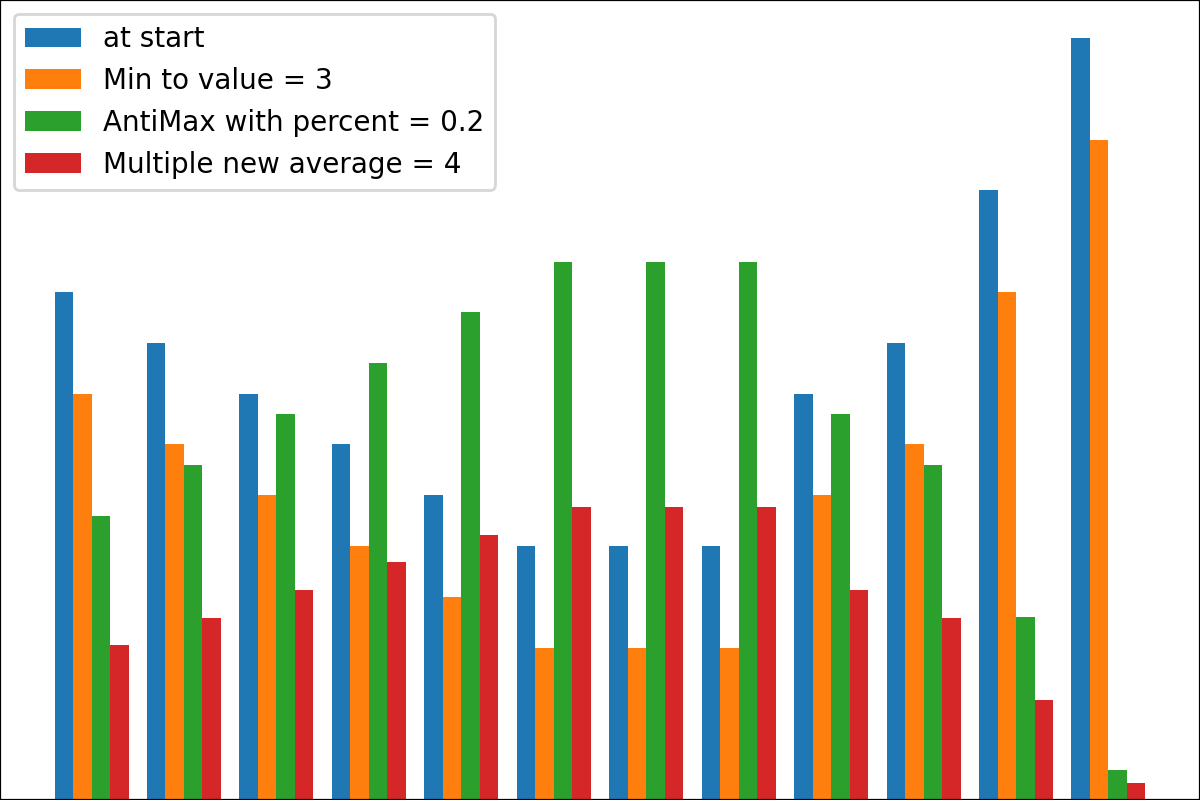
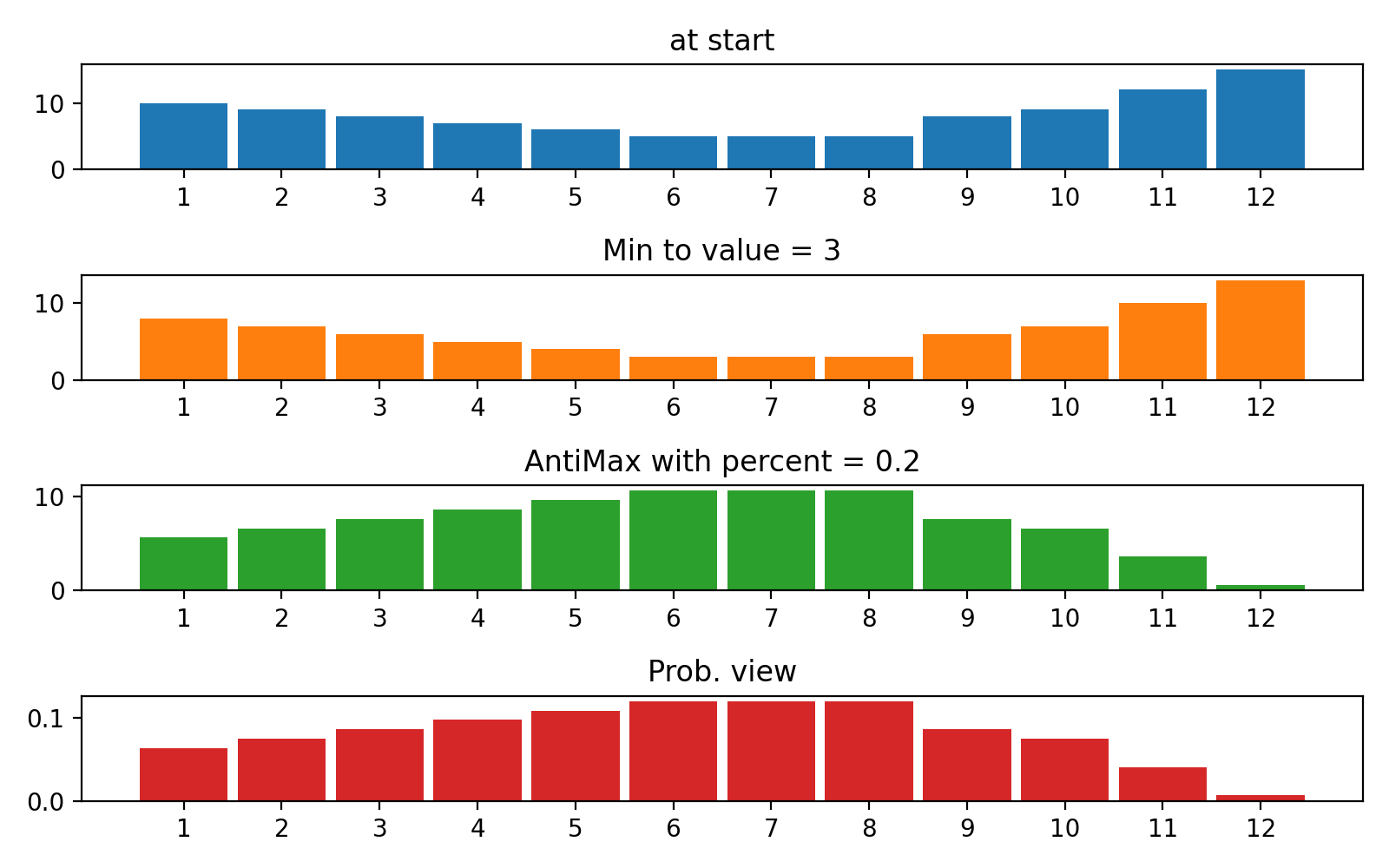
ฉันได้สร้างเครื่องมือเครือข่ายประสาทขั้นพื้นฐานที่นี่เพราะจำเป็นอย่างยิ่งที่จะต้องใช้เครือข่ายง่าย ๆ กับงาน การเรียนรู้เสริมแรง บางอย่าง แต่แพ็คเกจทั่วไปเช่น Keras ทำงานช้ามากถ้าคุณต้องการเพียงแค่การทำนาย (การแพร่กระจายไปข้างหน้า) เพียง 1 ตัวอย่าง แต่หลายครั้ง ดังนั้นจะเร็วขึ้นในการใช้แพ็คเกจที่ใช้ NumPy อย่างง่ายสำหรับกรณีเหล่านี้
มันไม่ยากเลยที่จะใช้ตรรกะของหม้อแปลงนี้สำหรับการสร้างเครือข่ายประสาท ดังนั้นแพ็คเกจนี้จึงมีเลเยอร์เครือข่ายประสาทต่อไปเป็นหม้อแปลง:
การเปิดใช้งาน :
SoftmaxReluLeakyRelu(alpha = 0.01)SigmoidTanhArcTanSwish(beta = 0.25)SoftplusSoftsignElu(alpha)Selu(alpha, scale)เครื่องมือเลเยอร์หนาแน่น :
Bias(bias_len, bias_array = None) - เพื่อเพิ่มอคติที่มีความยาว bias_len หาก bias_array None ให้ใช้อคติแบบสุ่มMatrixDot(from_size, to_size, matrix_array = None)NNStep(from_size, to_size, matrix_array = None, bias_array = None) - มันคือ MatrixDot และ Bias ด้วยกันถ้าคุณต้องการสร้างพวกเขาเร็วขึ้น และมีวิธีการช่วยเหลือหลายวิธีในการใช้วัตถุ pipeline เช่นเครือข่ายประสาท (สำหรับ การแพร่กระจายไปข้างหน้า แน่นอน):
วิธีการของ pipeline : วิธีการ :
get_shapes() - เพื่อรับรายการรูปร่างของอาร์เรย์ที่จำเป็นสำหรับ NNtotal_weights() - รับน้ำหนักสำหรับ NN โดยรวมset_weights(weights) - ตั้งน้ำหนัก (เป็นรายการอาร์เรย์ที่มีรูปร่างที่ต้องการ) สำหรับ nnฟังก์ชั่นเดียว :
arr_to_weigths(arr, shapes) -แปลง 1D-array arr เป็นรายการอาร์เรย์ที่มีรูปร่าง shapes เพื่อวางไว้ในวิธี set_weightsดูตัวอย่างที่ง่ายที่สุด


