cost2fitness
1.0.0
피트니스 값에 대한 전환 비용 값 (더 적음)을위한 PYPI 패키지 (더 많음).
pip install cost2fitness
이것은 변환을위한 몇 가지 방법을 포함하는 패키지입니다. 그러나이를 사용하는 주요 방법은 비용 값 (적은 점)에서 체력 값 (더 나은 것)으로 전환하고 그 반대도 마찬가지입니다. 사용하면 도움이 될 수 있습니다
몇 가지 간단한 변압기가 있습니다. 각 변압기는 입력 배열을 새로운 표현으로 변환하는 name 필드 및 transform(array) 메소드를 포함하는 BaseTransformer 클래스의 서브 클래스입니다.
체크리스트 :
ReverseByAverage ,AntiMax ,AntiMaxPercent(percent) ,Min2Zero ,Min2Value(value) ,ProbabilityView (데이터를 확률로 변환),SimplestReverse ,AlwaysOnes (배열의 반환),NewAvgByMult(new_average) ,NewAvgByShift(new_average)Divider(divider_number_or_array) (배열을 숫자 또는 배열로 나눕니다. 고정 된 시작 정규화에 유용합니다)Argmax (배열에서 최대 요소의 위치를 반환)Prob2Class(threshold = 0.5) (확률을 클래스로 변환하기 위해 0/1)ToNumber (첫 번째 요소를 얻음으로써 배열을 1 숫자로 변환)파일에서 간단한 논리를 사용하여 변압기를 만들 수 있습니다.
import numpy as np
from cost2fitness import Min2Zero
tf = Min2Zero ()
arr_of_scores = np . array ([ 10 , 8 , 7 , 5 , 8 , 9 , 20 , 12 , 6 , 18 ])
tf . transform ( arr_of_scores )
# array([ 5, 3, 2, 0, 3, 4, 15, 7, 1, 13]) 또한 Pl 파이프 라인을 사용하여 이러한 변압기를 결합 할 수 있습니다. 예를 들어:
import numpy as np
from cost2fitness import ReverseByAverage , AntiMax , Min2Zero , Pl
pipe = Pl ([
Min2Zero (),
ReverseByAverage (),
AntiMax ()
])
arr_of_scores = np . array ([ 10 , 8 , 7 , 5 , 8 , 9 ])
# return each result of pipeline transformation (with input)
pipe . transform ( arr_of_scores , return_all_steps = True )
#array([[10. , 8. , 7. , 5. , 8. ,
# 9. ],
# [ 5. , 3. , 2. , 0. , 3. ,
# 4. ],
# [ 0.66666667, 2.66666667, 3.66666667, 5.66666667, 2.66666667,
# 1.66666667],
# [ 5. , 3. , 2. , 0. , 3. ,
# 4. ]])
# return only result of transformation
pipe . transform ( arr_of_scores , return_all_steps = False )
#array([5., 3., 2., 0., 3., 4.]) 플롯 변환 프로세스 결과를 플롯하기위한 plot_scores 함수가 있습니다. 그것은 논쟁이 있습니다 :
scores : 구조 [start_values, first_transform(start_values), second_transform(first_transform), ...] 가있는 2d numpy 배열 2d numpy 배열, 여기서 각 객체는 1D 배열의 스코어 (값/비용/피트니스)입니다.names : None /문자열 목록, 플롯 레이블의 각 단계의 선택 이름. 기본값은 None 입니다.kind : STR, '옆' 의 선택 사항 각각의 새로운 열은 이전 옆에 있습니다. '아래'는 이전에 새로운 음모가있을 것입니다. 기본값은 '옆'입니다.save_as : None /str, 플롯을 저장하기위한 옵션 파일 경로. 기본값은 None 입니다. 암호
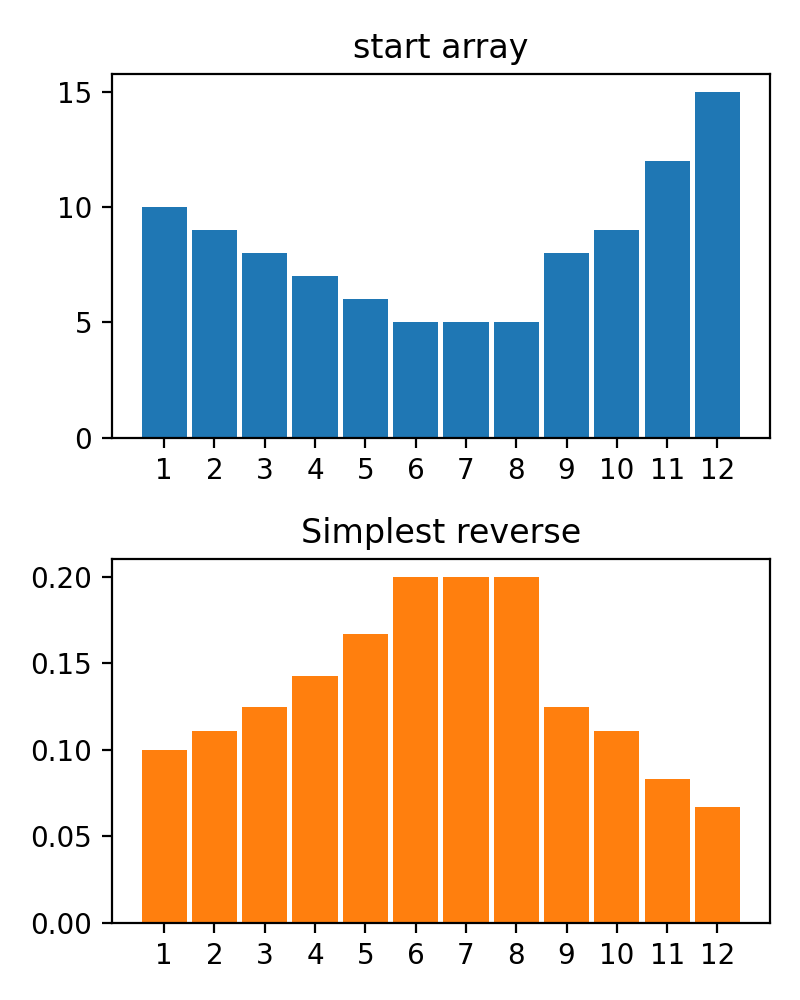
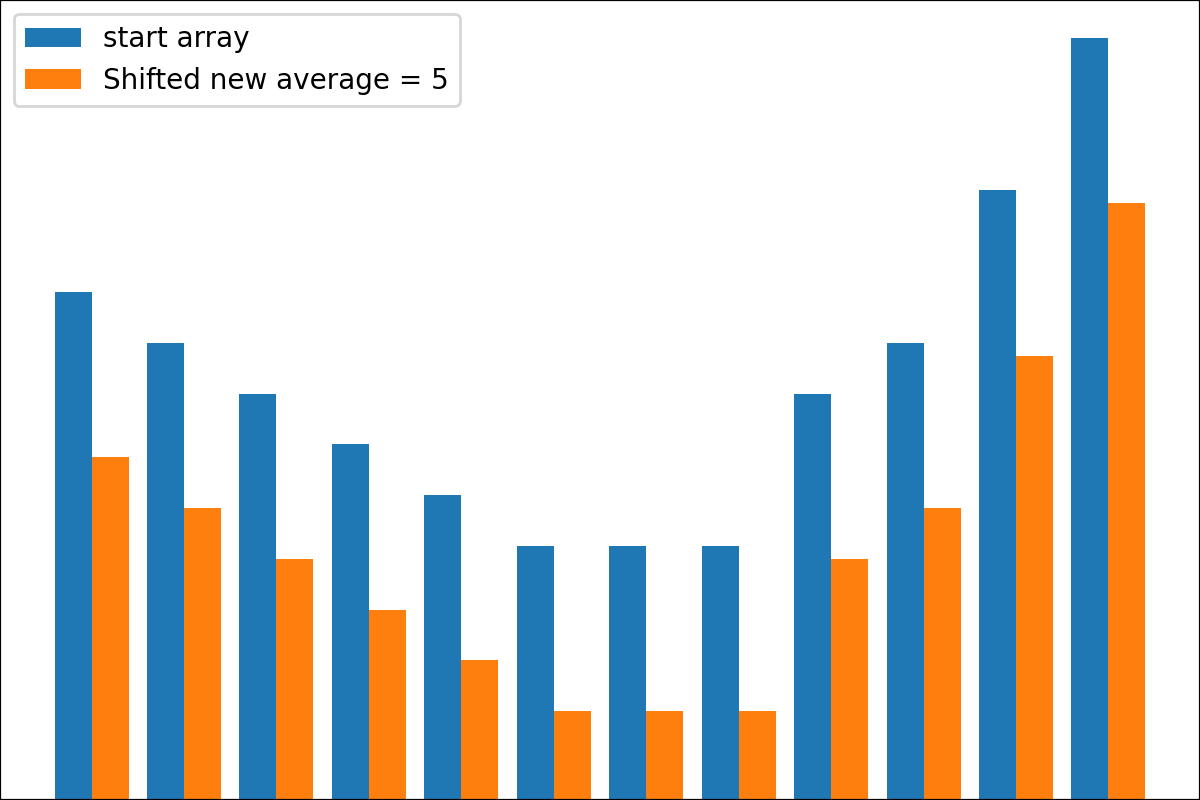
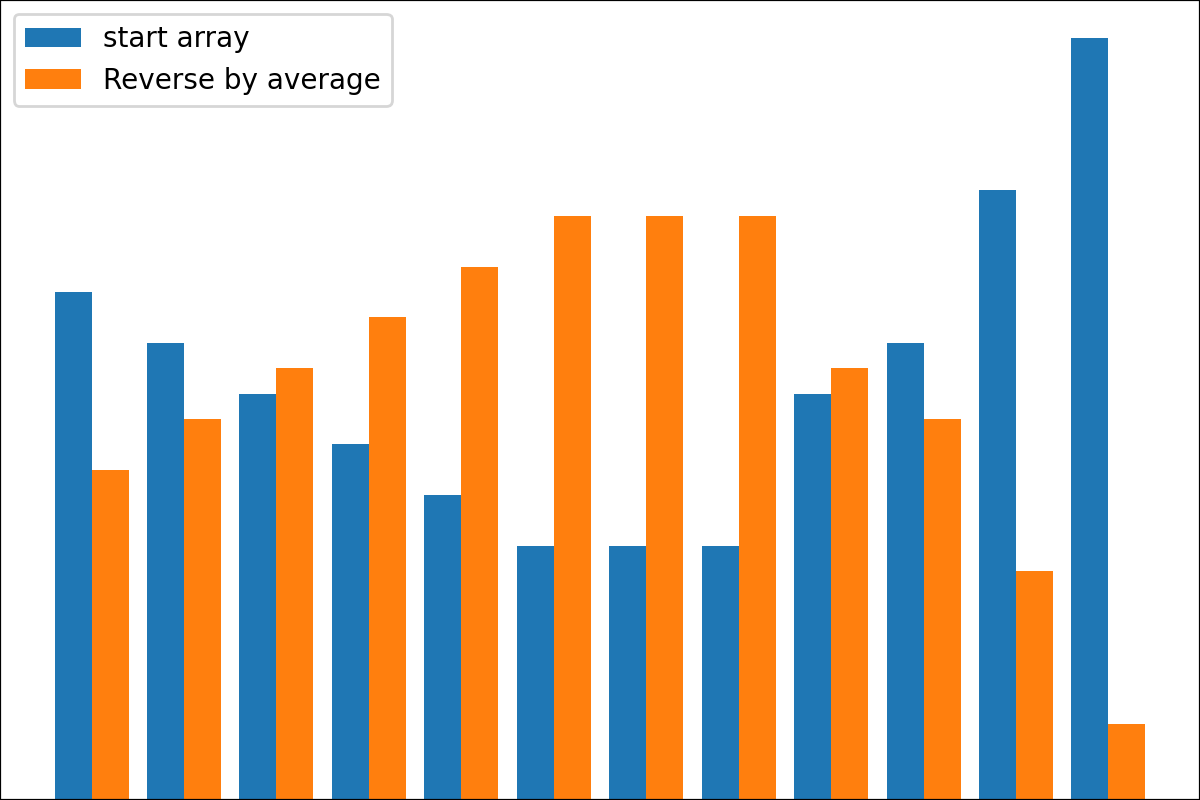
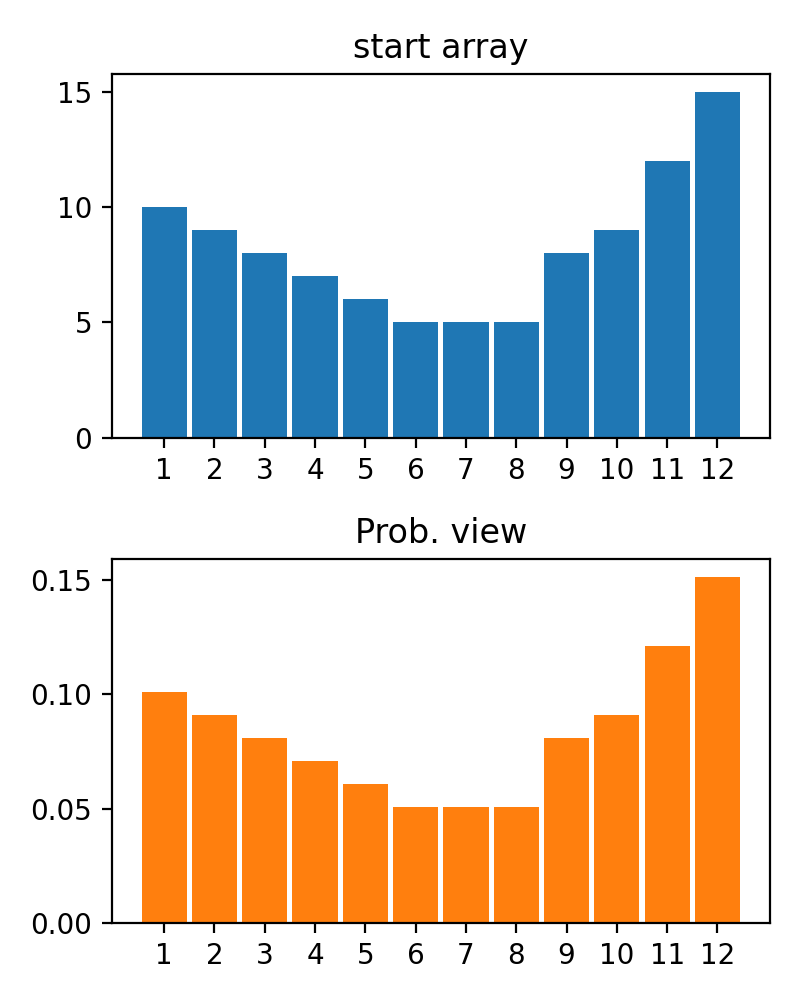
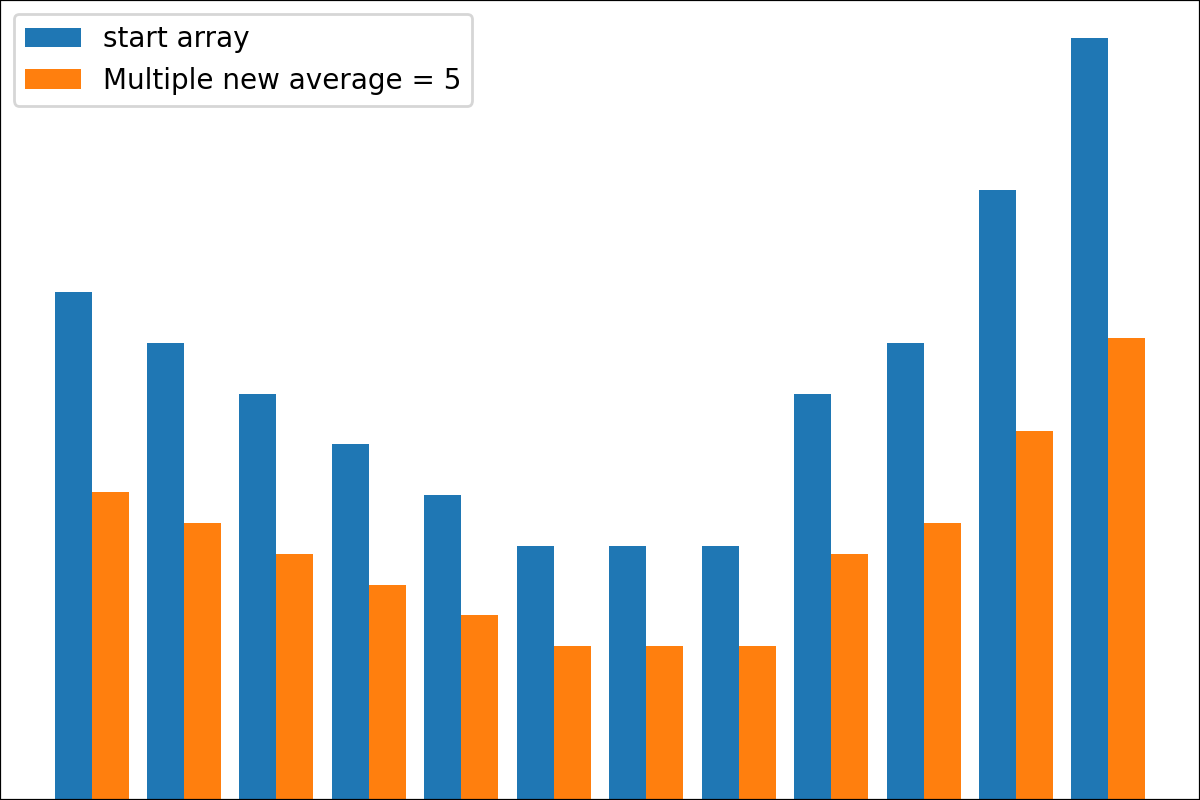
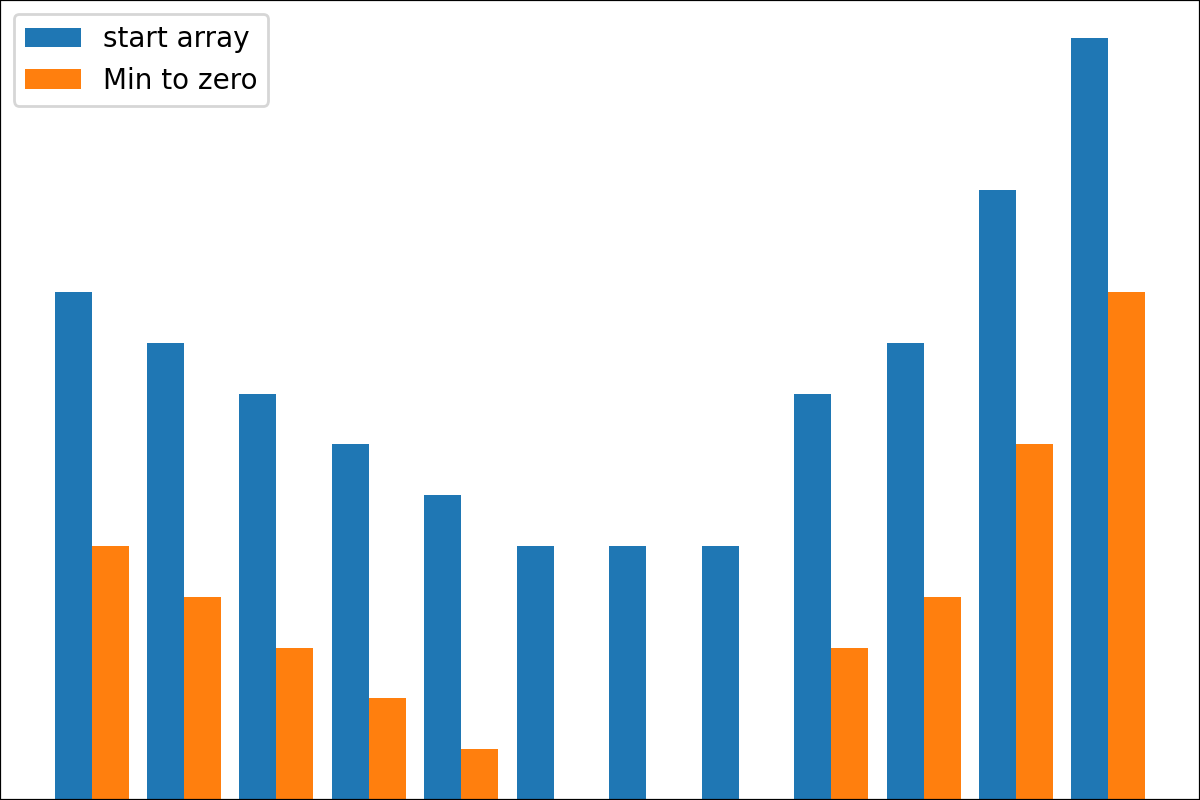
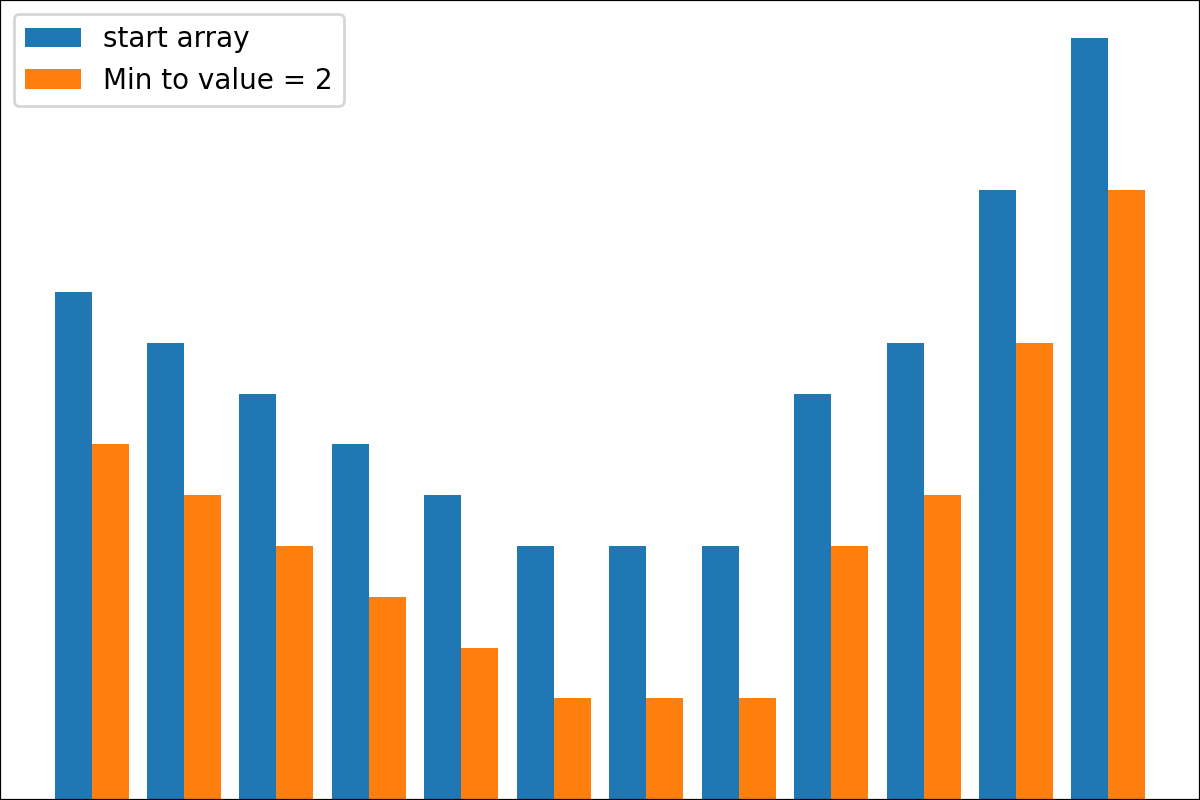
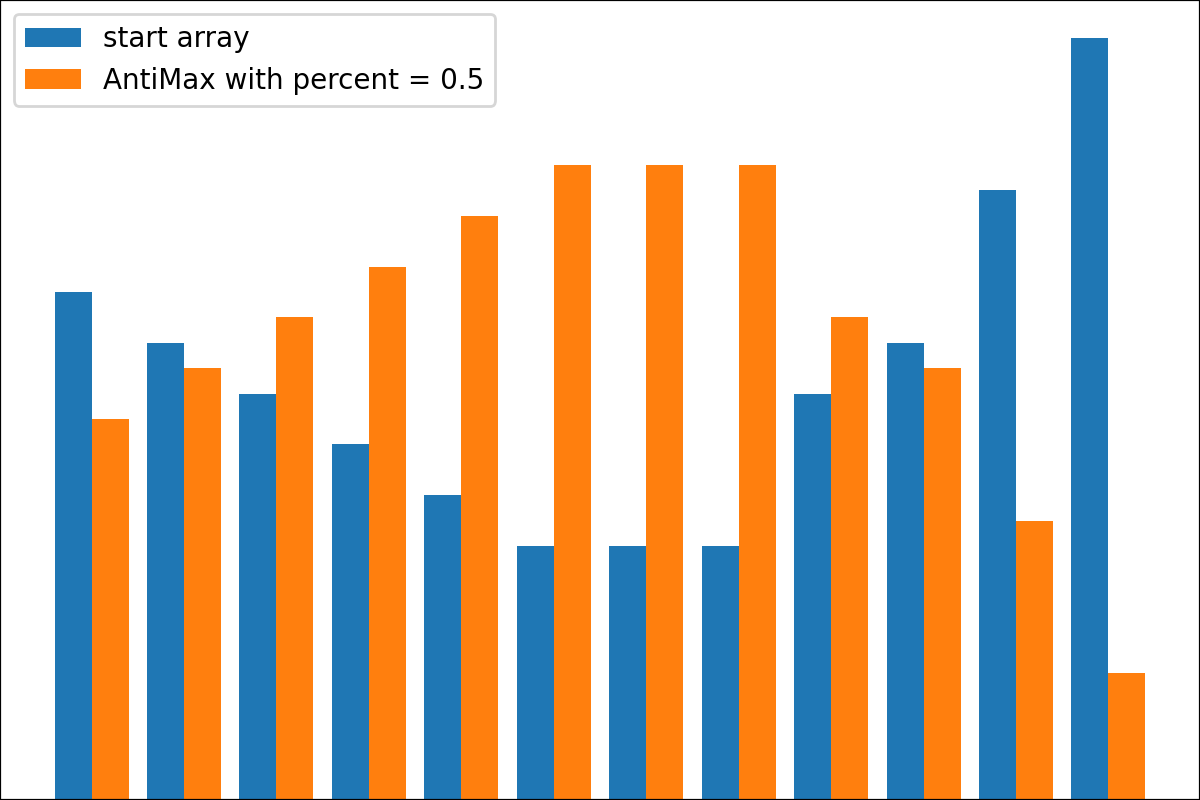
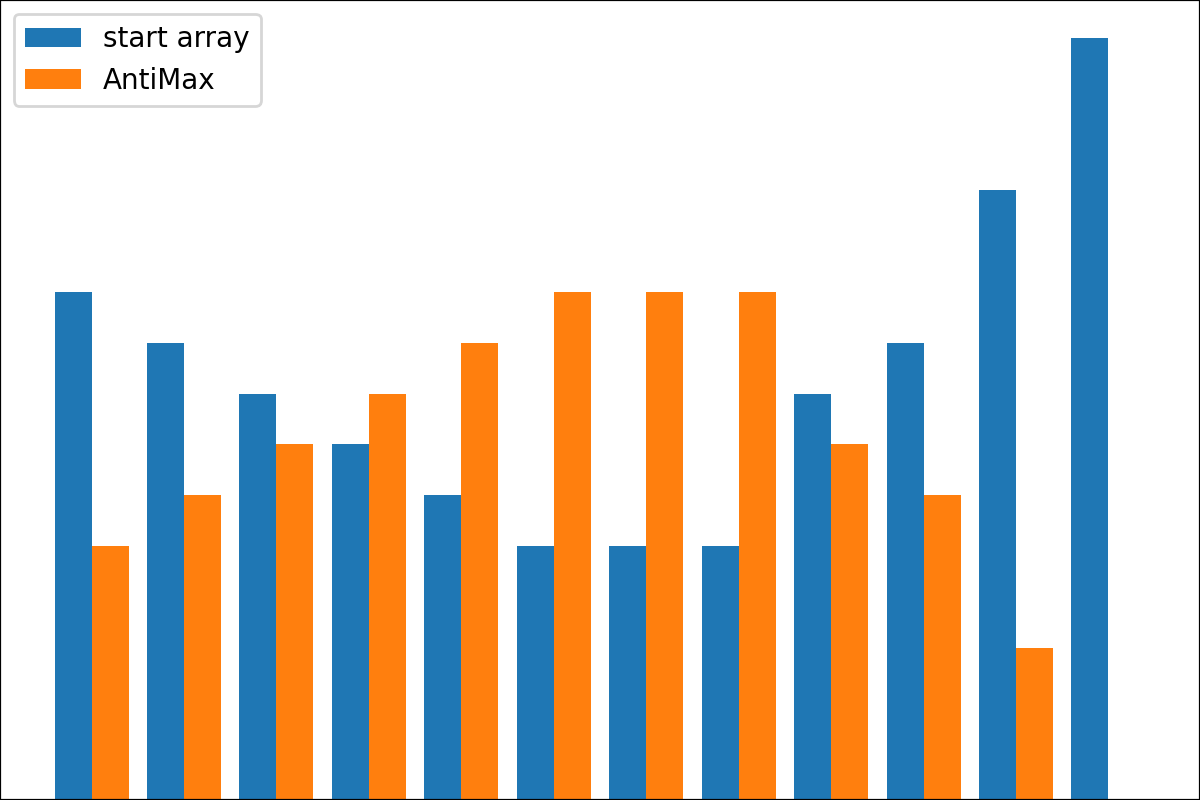
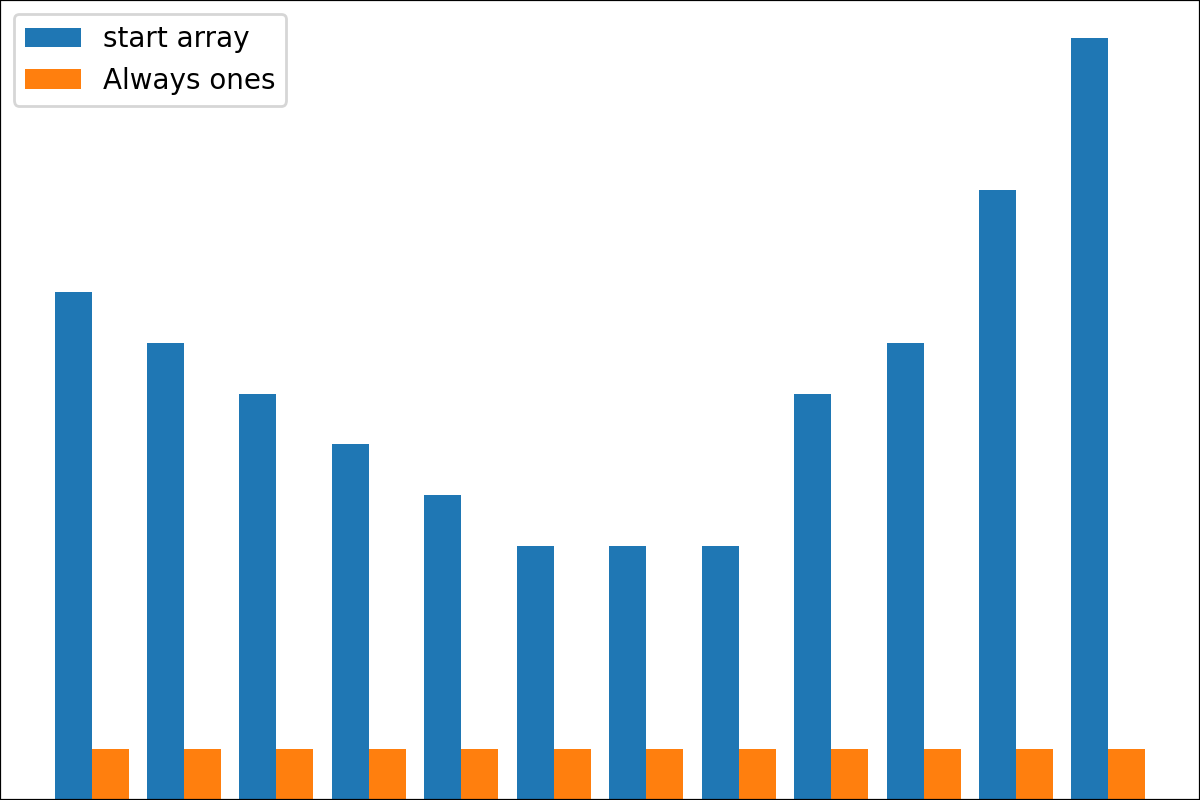
암호
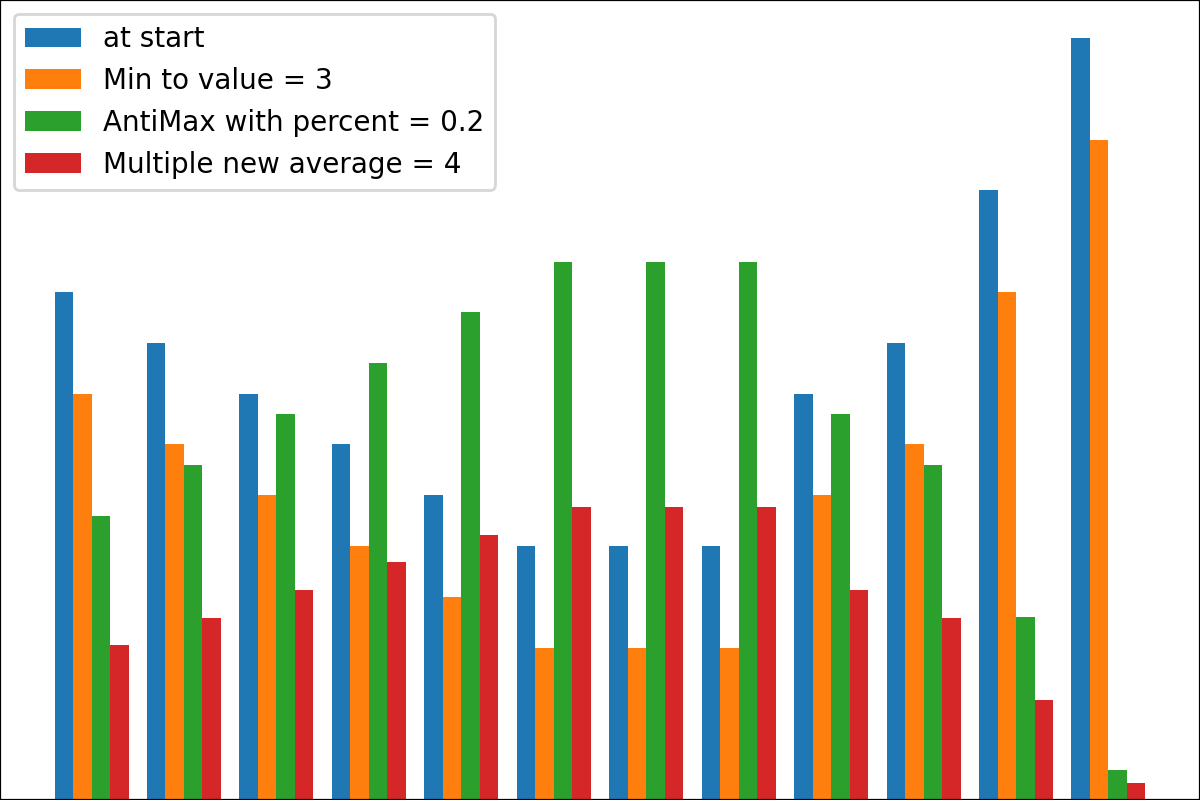
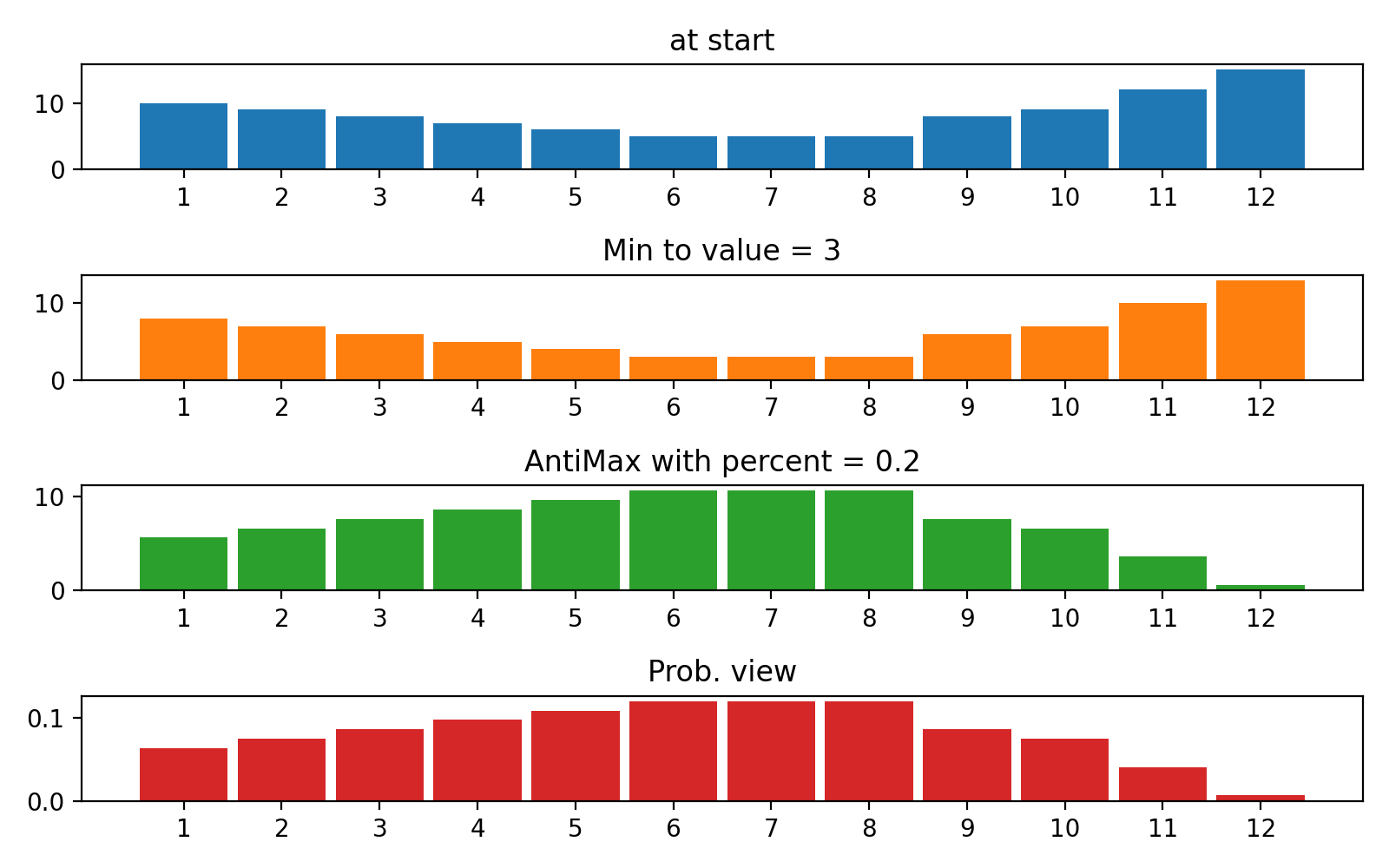
일부 강화 학습 작업이있는 간단한 네트워크를 사용해야하기 때문에 기본 신경망 도구를 만들었지 만 Keras와 같은 일반적인 패키지는 예측 (전방 전파) 만 필요하면 여러 번만 느리게 작동합니다. 따라서 이러한 경우에 간단한 Numpy 기반 패키지를 사용하는 것이 더 빠릅니다.
신경망을 생성하기 위해이 변압기 논리를 사용하는 것은 그리 어렵지 않았습니다. 따라서이 패키지에는 다음 신경 네트워크 계층이 변압기로 제공됩니다.
활성화 :
SoftmaxReluLeakyRelu(alpha = 0.01)SigmoidTanhArcTanSwish(beta = 0.25)SoftplusSoftsignElu(alpha)Selu(alpha, scale)밀도가 높은 레이어 도구 :
Bias(bias_len, bias_array = None) - 길이 bias_len 의 바이어스를 추가합니다. bias_array None 무작위 바이어스를 사용합니다MatrixDot(from_size, to_size, matrix_array = None)NNStep(from_size, to_size, matrix_array = None, bias_array = None) - MatrixDot 이고 함께 바이어스를 만들고 싶다면 더 빨리 만들고 싶다면 Bias 그리고 신경망과 같은 pipeline 객체를 사용하는 몇 가지 헬퍼 방법이 있습니다 (물론 전달 전파 에만 해당).
pipeline 객체 방법 :
get_shapes() - NN에 필요한 배열 모양 목록을 얻으려면total_weights() - 전체 NN에 대한 가중치를 얻습니다set_weights(weights) - NN의 세트 웨이트 (필요한 모양의 배열 목록)혼자 기능 :
arr_to_weigths(arr, shapes) -1d-array array arr shapes 가있는 배열 목록으로 변환하여 set_weights 메소드에 넣습니다.가장 간단한 예를 참조하십시오


