cost2fitness
1.0.0
PYPI -Paket für Conversion -Kostenwerte (weniger ist besser) für Fitnesswerte (mehr ist besser) und umgekehrt
pip install cost2fitness
Dies ist das Paket, das verschiedene Methoden zur Transformation enthält. Die primäre Möglichkeit, dies zu verwenden, ist jedoch die Konvertierung von Kostenwerten (weniger ist besser) auf Fitnesswerte (mehr ist besser) und umgekehrt. Es kann sehr hilfreich sein, wenn Sie benutzen
Es gibt mehrere einfache Transformatoren. Jeder Transformator ist die Unterklasse der BaseTransformer -Klasse, die name Feld und die transform(array) enthält, die das Eingabearray in eine neue Darstellung umwandelt.
Checkliste:
ReverseByAverage ,AntiMax ,AntiMaxPercent(percent) ,Min2Zero ,Min2Value(value) ,ProbabilityView (konvertiert Daten in Wahrscheinlichkeiten),SimplestReverse ,AlwaysOnes (zurückgegeben),NewAvgByMult(new_average) ,NewAvgByShift(new_average)Divider(divider_number_or_array) (Divids Array auf Nummer oder Array, nützlich für die feste Startnormalisierung)Argmax (Rückgabeposition des maximalen Elements im Array)Prob2Class(threshold = 0.5) (um Wahrscheinlichkeiten in Klassen 0/1 umzuwandeln)ToNumber (konvertiert Array in eine Nummer, indem er das erste Element bekommt)Sie können Ihren Transformator mit einer einfachen Logik aus der Datei erstellen.
import numpy as np
from cost2fitness import Min2Zero
tf = Min2Zero ()
arr_of_scores = np . array ([ 10 , 8 , 7 , 5 , 8 , 9 , 20 , 12 , 6 , 18 ])
tf . transform ( arr_of_scores )
# array([ 5, 3, 2, 0, 3, 4, 15, 7, 1, 13]) Sie können diese Transformatoren auch mit Pl -Pipeline kombinieren. Zum Beispiel:
import numpy as np
from cost2fitness import ReverseByAverage , AntiMax , Min2Zero , Pl
pipe = Pl ([
Min2Zero (),
ReverseByAverage (),
AntiMax ()
])
arr_of_scores = np . array ([ 10 , 8 , 7 , 5 , 8 , 9 ])
# return each result of pipeline transformation (with input)
pipe . transform ( arr_of_scores , return_all_steps = True )
#array([[10. , 8. , 7. , 5. , 8. ,
# 9. ],
# [ 5. , 3. , 2. , 0. , 3. ,
# 4. ],
# [ 0.66666667, 2.66666667, 3.66666667, 5.66666667, 2.66666667,
# 1.66666667],
# [ 5. , 3. , 2. , 0. , 3. ,
# 4. ]])
# return only result of transformation
pipe . transform ( arr_of_scores , return_all_steps = False )
#array([5., 3., 2., 0., 3., 4.]) Es gibt die Funktion der plot_scores -Funktion zum Aufzeichnen von Transformationsprozessgebnissen. Es hat Argumente:
scores : 2d Numpy Array 2d Numpy Array mit Struktur [start_values, first_transform(start_values), second_transform(first_transform), ...] , wobei jedes Objekt 1D-Array von Scores (Werte/Kosten/Fitness) ist.names : None /String -Liste, optionale Namen für jeden Schritt für Handlungsbezeichnungen. Der Standard ist None .kind : STR, optional für 'neben' Jede neue Spalte wird neben vorherig sein; Für 'Under' wird es unter früheren eine neue Handlung geben. Der Standard ist "neben".save_as : None /str, optionalen Dateipfad zum Speichern des Diagramms. Der Standard ist None . Code
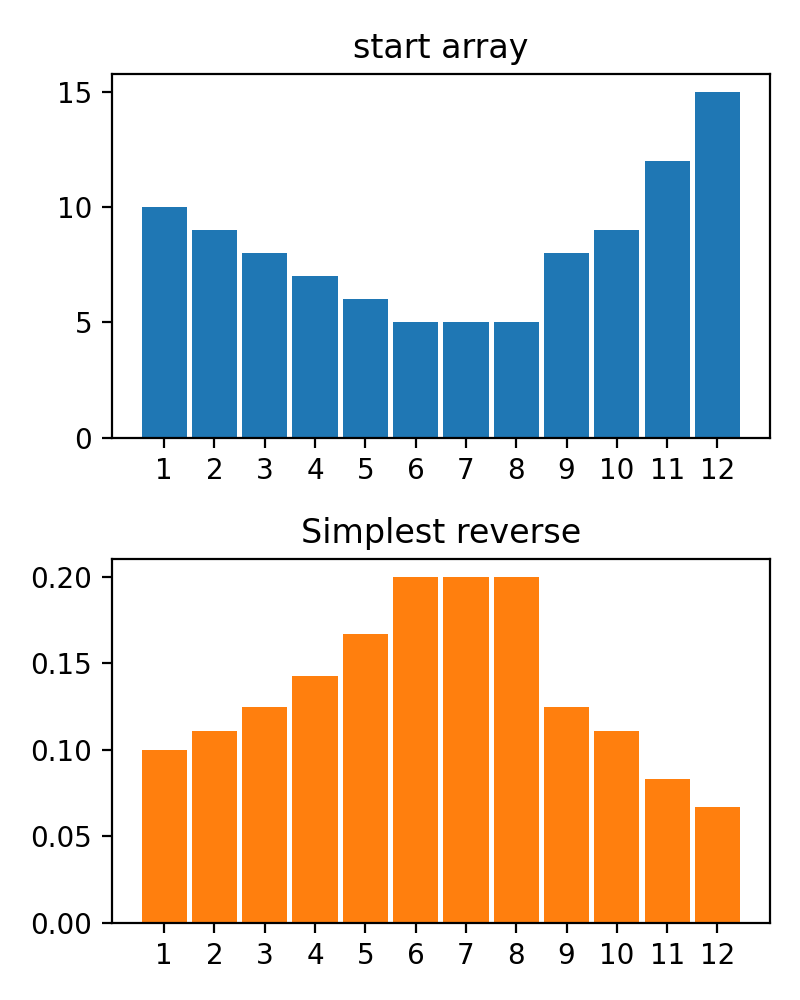
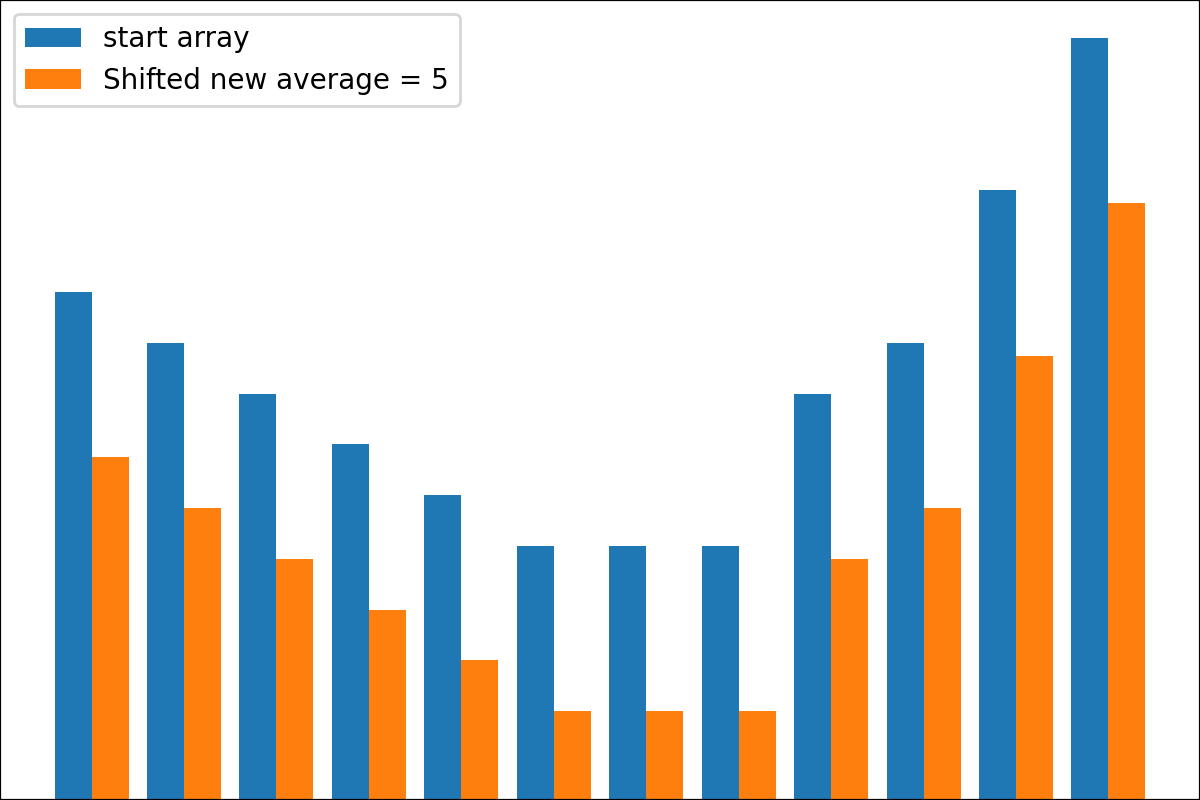
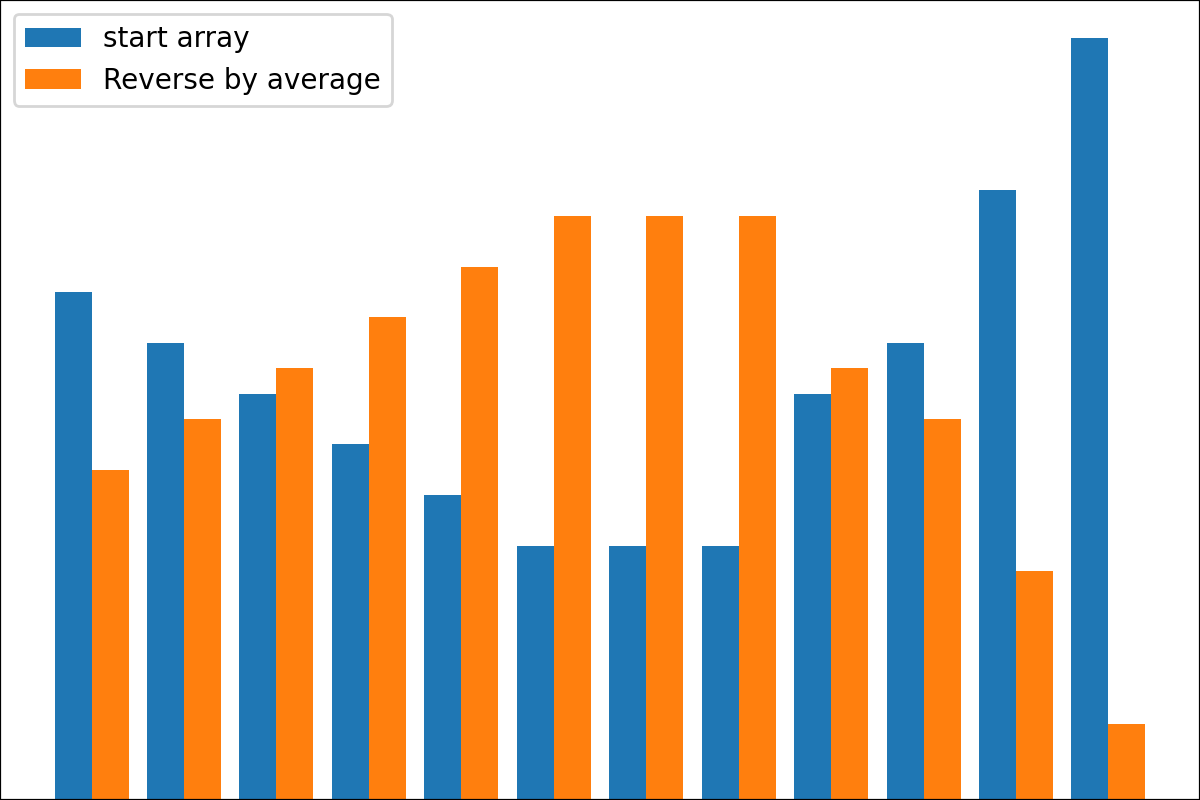
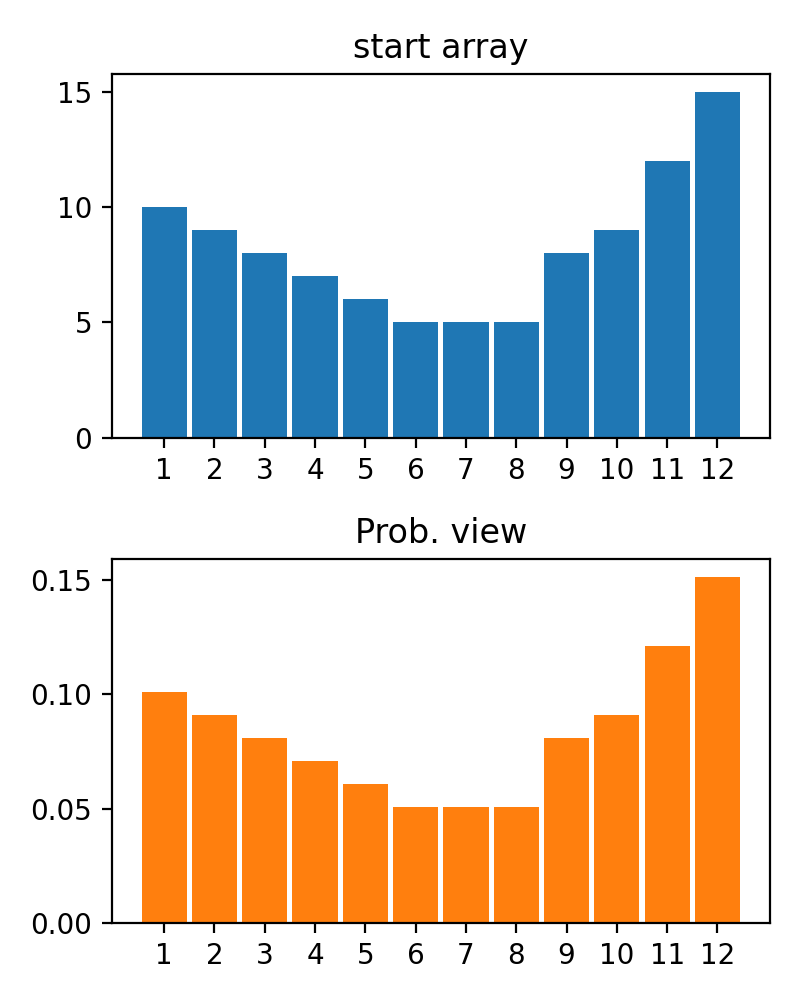
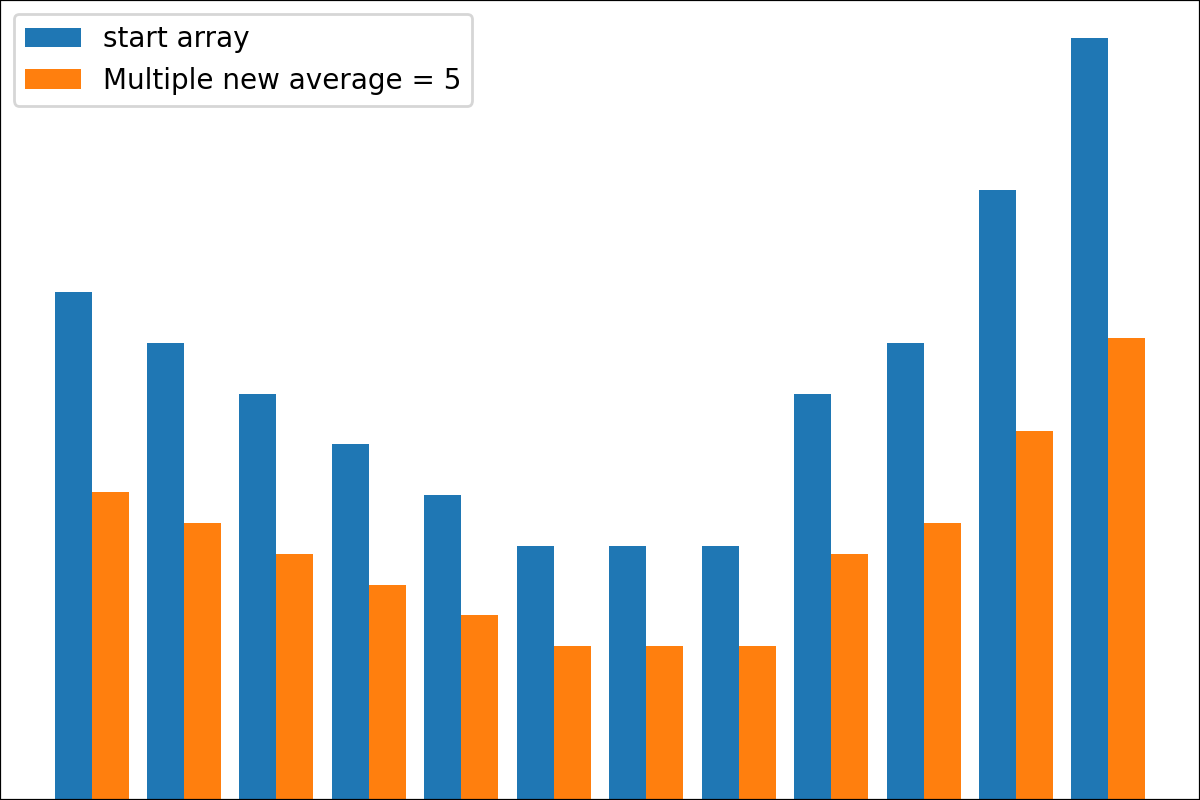
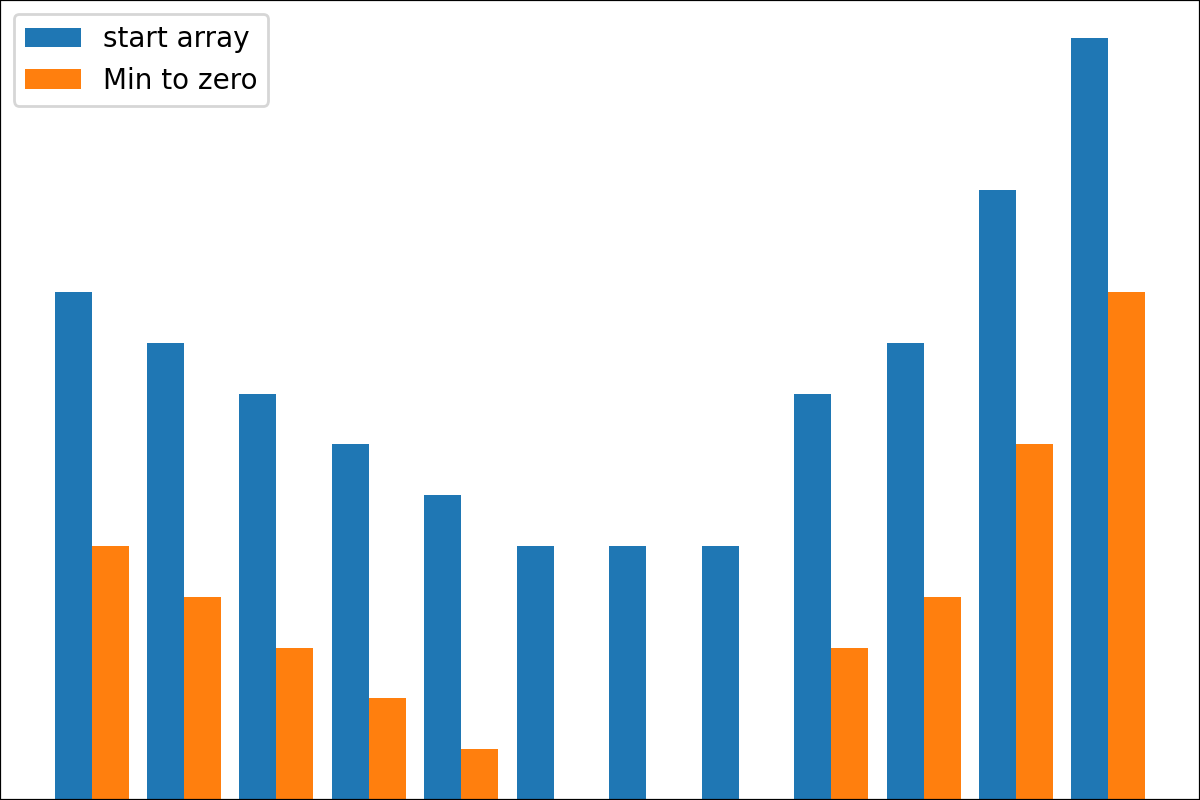
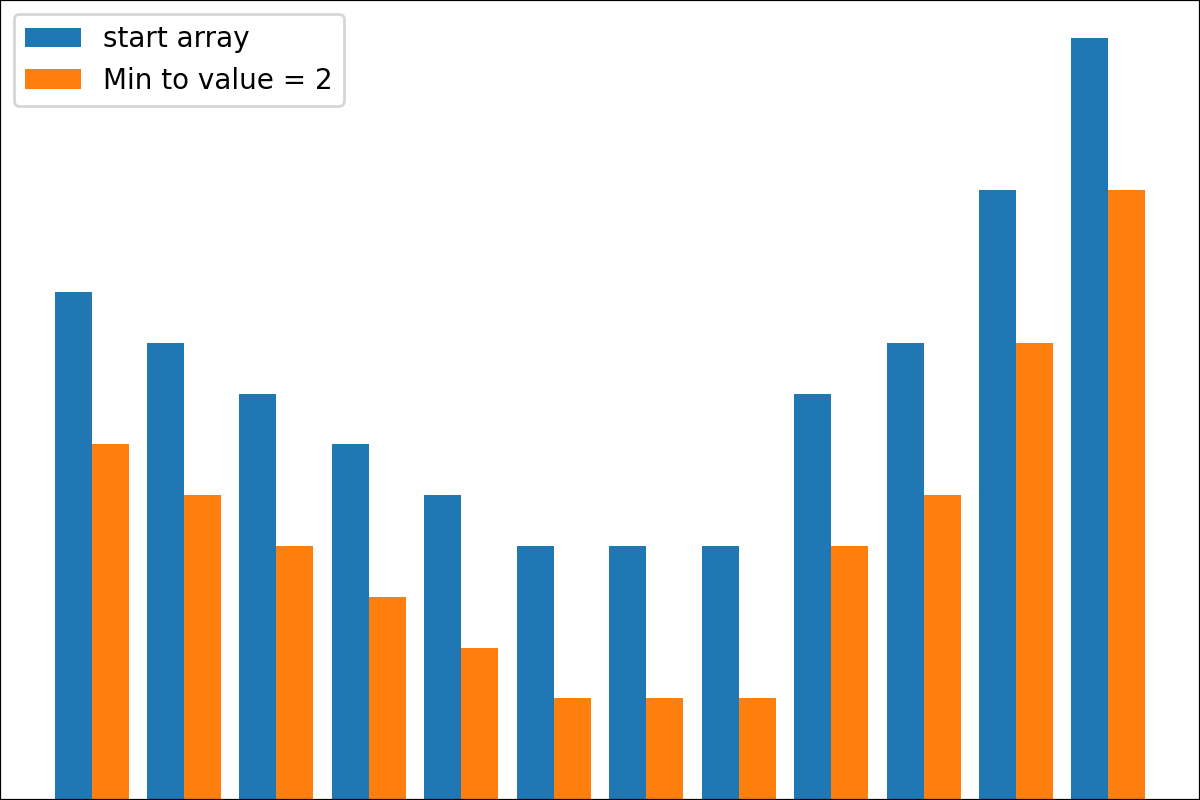
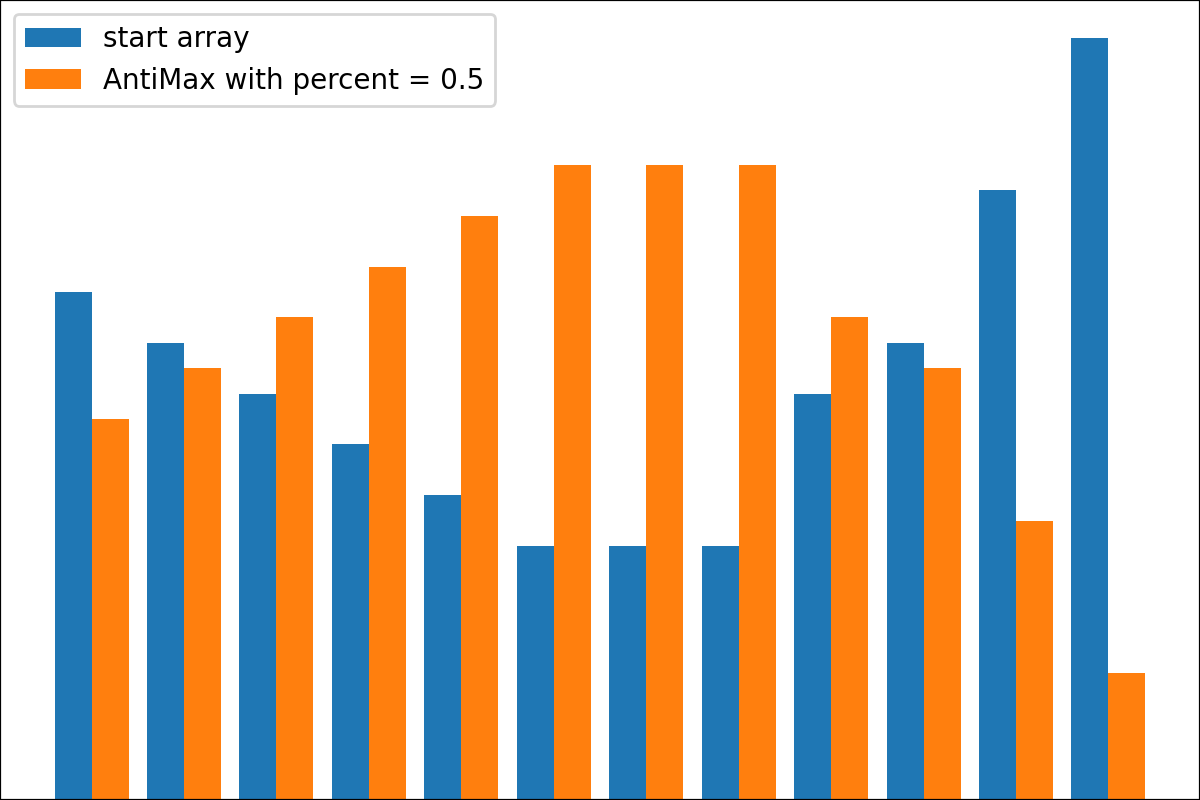
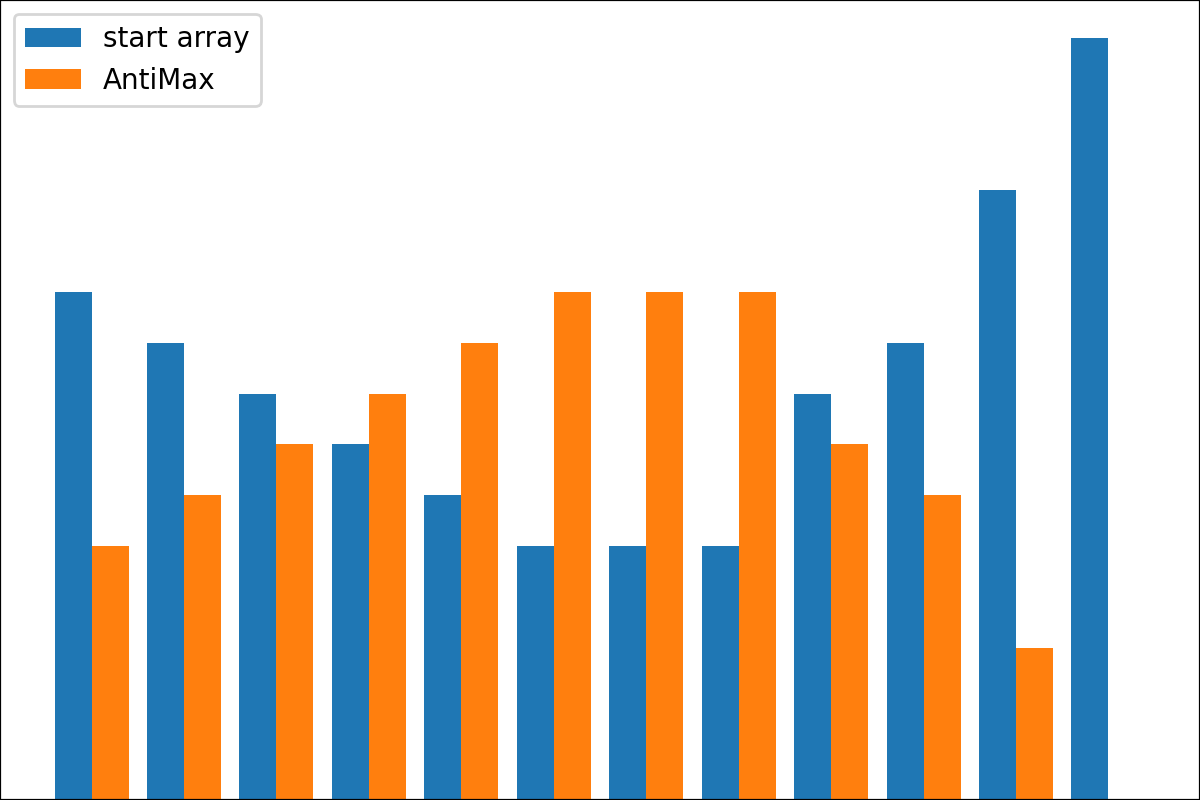
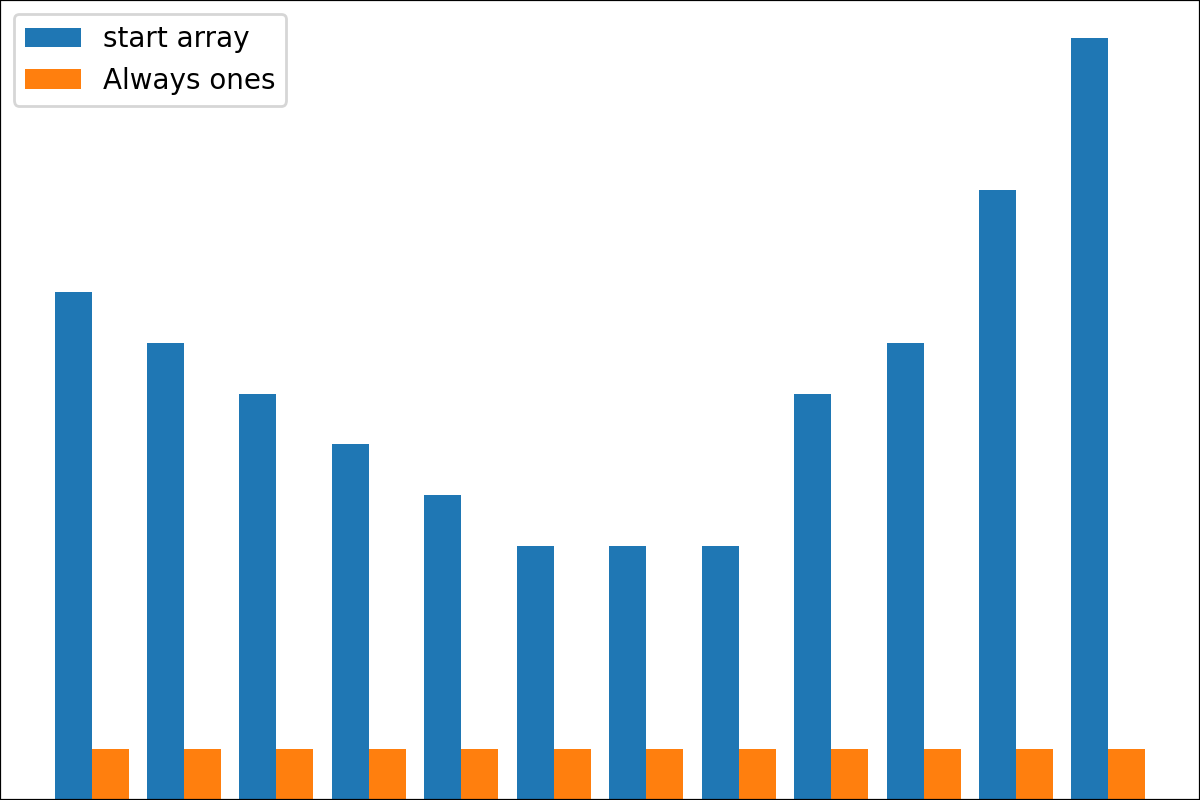
Code
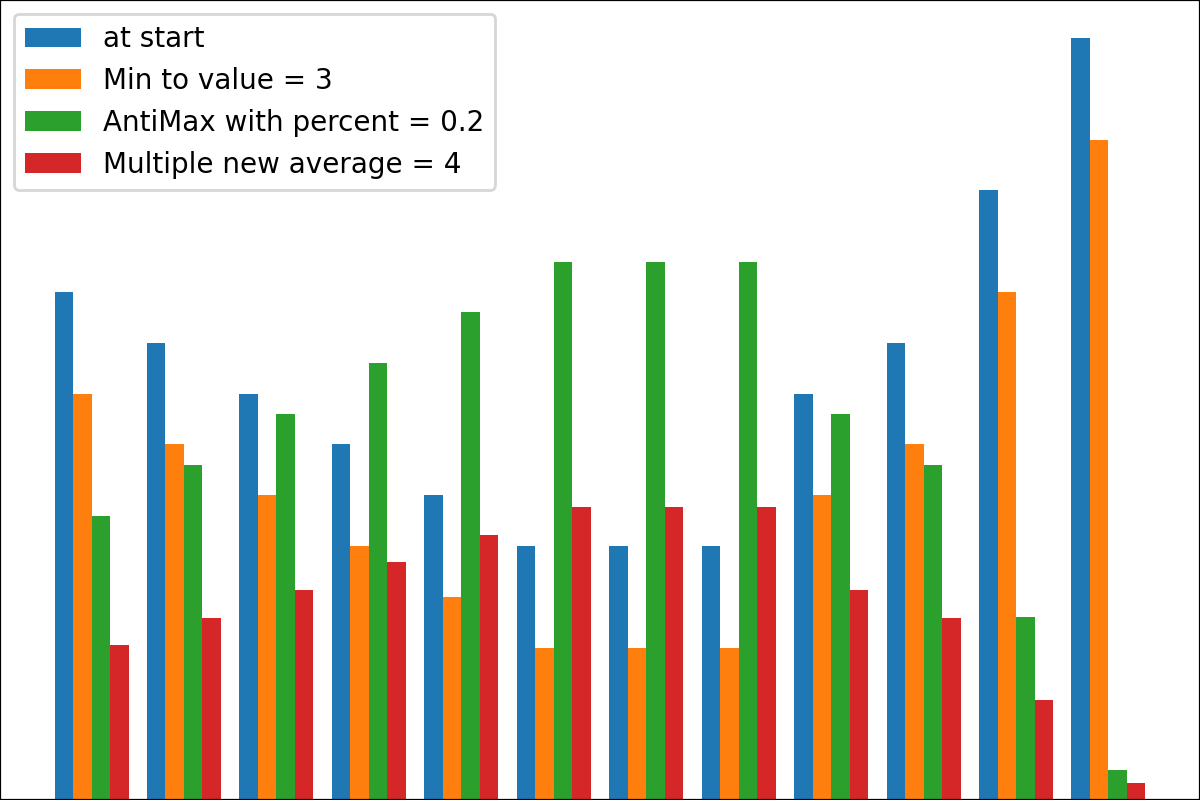
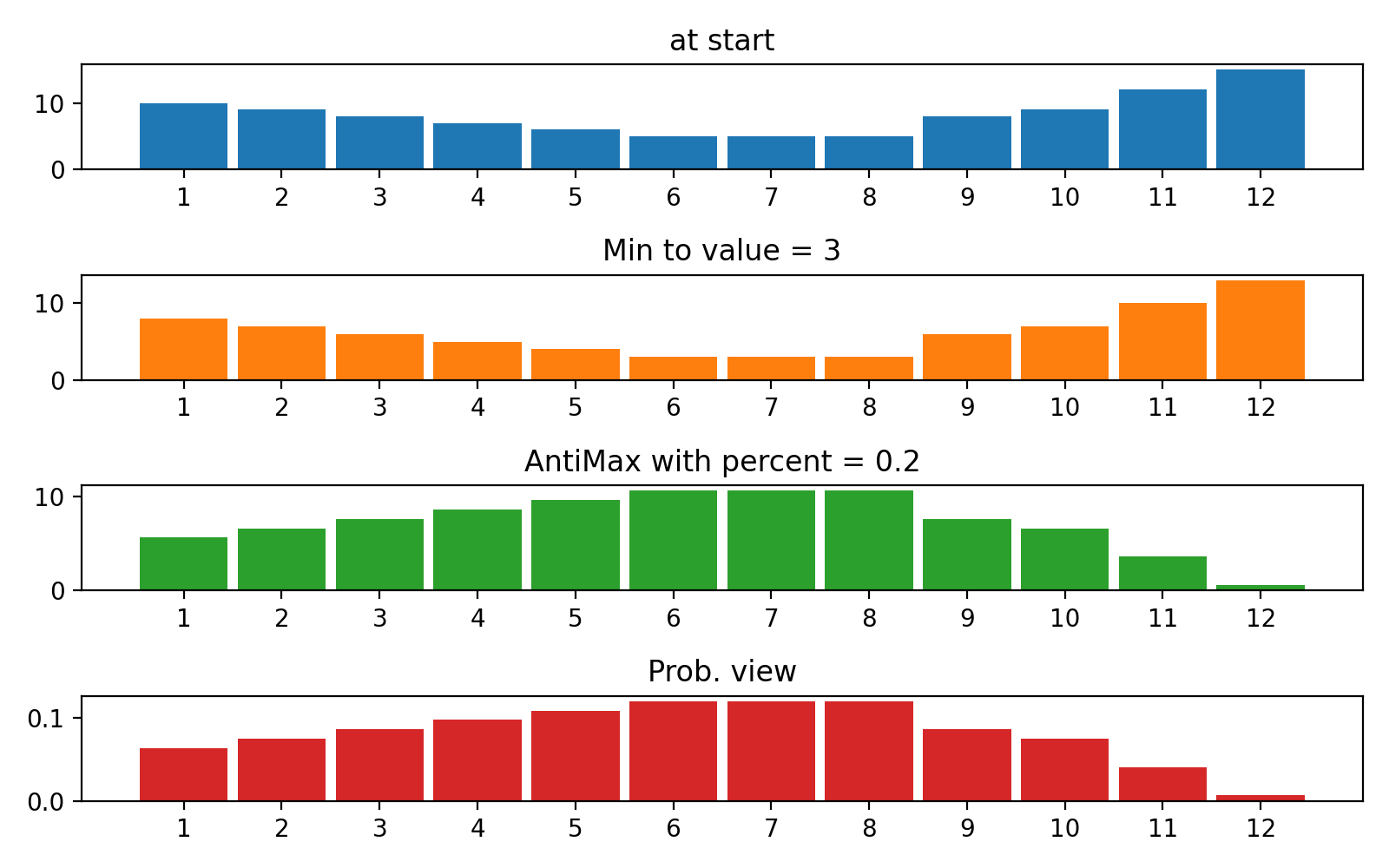
Ich habe hier grundlegende Tools für neuronale Netzwerke erstellt, da es sehr notwendig ist, einfache Netzwerke mit einigen Verstärkungslernaufgaben zu verwenden, aber gemeinsame Pakete wie Keras arbeiten extrem langsam, wenn Sie nur für eine Probe jedoch nur für eine Probe, aber viele Male Vorhersage (Vorwärtsverbreitung) benötigen. Daher wird es schneller sein, einfache Numpy-basierte Pakete für diese Fälle zu verwenden.
Es war nicht so schwierig, diese Transformatorenlogik für die Erstellung neuronaler Netzwerke zu verwenden. Dieses Paket hat also die nächsten neuronalen Netzwerkschichten als Transformatoren:
Aktivierungen :
SoftmaxReluLeakyRelu(alpha = 0.01)SigmoidTanhArcTanSwish(beta = 0.25)SoftplusSoftsignElu(alpha)Selu(alpha, scale)Dichte Schichtenwerkzeuge :
Bias(bias_len, bias_array = None) - Fügen Sie eine Verzerrung mit Länge bias_len hinzu. Wenn bias_array None ist, verwendet zufällige VerzerrungMatrixDot(from_size, to_size, matrix_array = None)NNStep(from_size, to_size, matrix_array = None, bias_array = None) - Es ist MatrixDot und Bias miteinander, wenn du sie schneller erstellen willst Und es gibt mehrere Helfermethoden für die Verwendung von pipeline -Objekten wie neuronalem Netzwerk (natürlich nur für die Vorwärtsverbreitung ):
pipeline -Objekt -Methoden :
get_shapes() - um eine Liste der Formen des erforderlichen Arrays für NN zu erhaltentotal_weights() - Gewichte für insgesamt nn erhaltenset_weights(weights) - Setzen Sie Gewichte (als Liste der Arrays mit benötigten Formen) für NNAllein Funktionen :
arr_to_weigths(arr, shapes) -konvertiert 1D-Array arr in die Auflistung von Arrays mit shapes , um es in die Methode set_weights zu setzenSiehe einfachste Beispiel


