VoiceFlow TTS
1.0.0
นี่คือการใช้งานอย่างเป็นทางการของ ICASSP 2024 Paper Voiceflow ของเรา
repo นี้ได้รับการทดสอบบน Python 3.9 บน Linux คุณสามารถตั้งค่าสภาพแวดล้อมด้วย conda
# Install required packages
conda create -n vflow python==3.9 # or any name you like
conda activate vflow
pip install -r requirements.txt
# Then, set PATH
source path.sh # change the env name in it if you don't use "vflow"
# Install monotonic_align for MAS
cd model/monotonic_align
python setup.py build_ext --inplace โปรดทราบว่าเพื่อหลีกเลี่ยงปัญหาในการติดตั้ง Torchdyn เราคัดลอกเวอร์ชัน Torchdyn 1.0.6 โดยตรงที่นี่ที่ torchdyn/
กระบวนการต่อไปนี้อาจต้องใช้คำสั่ง bash และ perl ในสภาพแวดล้อมของคุณ
repo นี้ขึ้นอยู่กับการจัดระเบียบข้อมูลสไตล์ Kaldi ไฟล์คำอธิบายข้อมูลทั้งหมดควรใส่ในไดเรกทอรีย่อยใน data/ ดู data/ljspeech/example สำหรับตัวอย่างพื้นฐาน ในตัวอย่างนี้จำเป็นต้องมีไฟล์ข้อความธรรมดาต่อไปนี้:
wav.scp : จัดเป็น utt /path/to/wavutts.list : ทุกบรรทัดระบุคำพูด สามารถรับได้โดย cut -d ' ' -f 1 wav.scp > utts.listutt2spk : จัดเป็น utt spk_nametext และ phn_duration : ระบุลำดับฟอนิมและระยะเวลาจำนวนเต็มที่สอดคล้องกัน (ในเฟรม) นอกจากนี้ยังมีไฟล์ data/ljspeech/phones.txt เพื่อระบุโทรศัพท์ทั้งหมดพร้อมกับดัชนีในพจนานุกรม สำหรับ LJSpeech เราให้ไฟล์ที่ประมวลผลออนไลน์ คุณสามารถดาวน์โหลดและคลายซิปไปยัง data/ljspeech/{train,val} หากคุณต้องการฝึกอบรมในชุดข้อมูลของคุณเองคุณอาจต้องสร้างไฟล์เหล่านี้ด้วยตัวเอง (หรือเปลี่ยนกลยุทธ์การโหลดข้อมูล)
หลังจากมีไฟล์รายการเหล่านี้โปรดทำสิ่งต่อไปนี้เพื่อแยก mel-spectrogram สำหรับการฝึกอบรม:
bash extract_fbank.sh --stage 0 --stop_stage 2 --nj 16
# nj: number of parallel jobs.
# Have a look into the script if you need to change something
# Bash variables before "parse_options.sh" can be passed by CLI, e.g. "--key value". โปรดทราบว่าเราเริ่มต้นใช้ข้อมูล 16KHz ที่นี่ สิ่งนี้จะสร้าง feats/fbank และ feats/normed_fbank ที่ kaldi-style scp และไฟล์ Ark เก็บข้อมูล mel-spectrogram คุณสมบัติบรรทัดฐานจะใช้สำหรับการฝึกอบรม
หากคุณต้องการใช้ Speaker-Ids (เช่น LJSpeech แทนที่จะใช้ Embeddings ลำโพงที่ผ่านการฝึกอบรมเช่น XVectors) สำหรับการฝึกอบรมโปรดเรียกใช้:
make_utt2spk_id.py data/ljspeech/train/utt2spk data/ljspeech/val/utt2spk
# You can add more files in CLI. Will write utt2num_frames in the same directory to these files. การกำหนดค่าสำหรับการฝึกอบรมจะถูกเก็บไว้เป็นไฟล์ YAML ใน configs/ ข้อมูลที่ปรากฏและคุณสมบัติสำหรับการฝึกอบรมและชุดตรวจสอบจะถูกระบุในไฟล์ YAML เหล่านั้น คุณจะต้องเปลี่ยนเส้นทางไฟล์ที่ยกสองครั้งที่นั่นหากคุณต้องการฝึกอบรมข้อมูลของคุณเอง
จากนั้นการฝึกอบรมจะดำเนินการโดย
python train.py -c configs/ ${your_yaml} -m ${model_name}
# e.g. python train.py -c configs/lj_16k_gt_dur.yaml -m lj_16k_gt_dur มันจะสร้าง logs/${model_name} สำหรับการบันทึกและการตรวจสอบ
หมายเหตุหลายประการ:
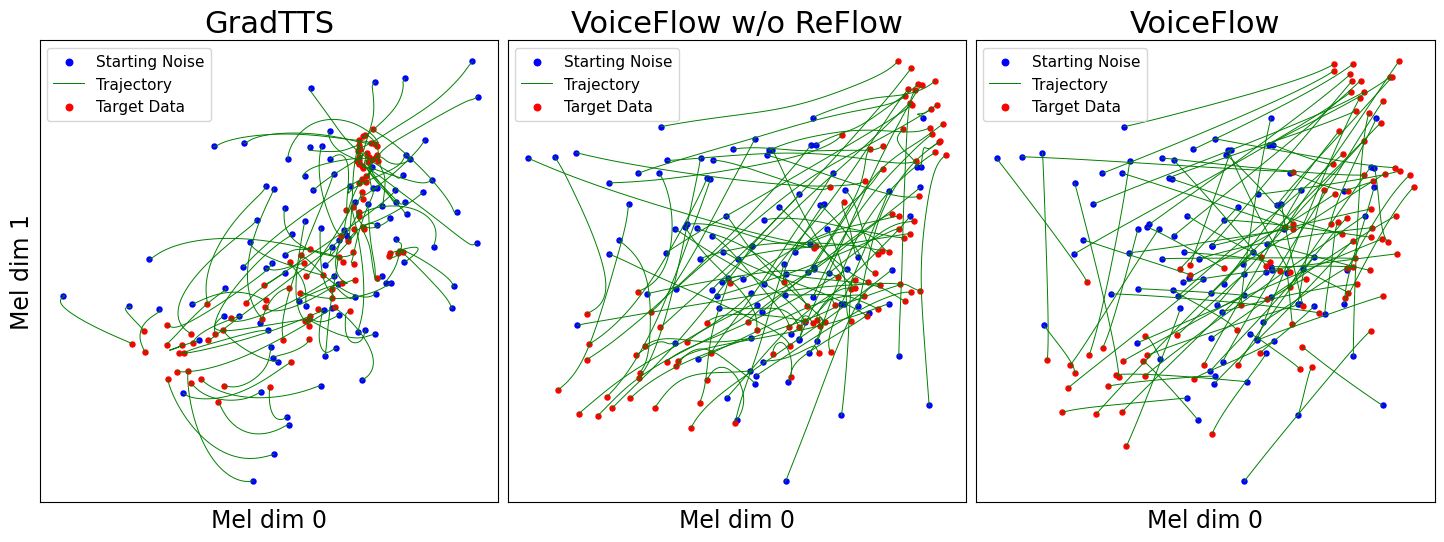
use_gt_dur เป็น false เพื่อเปิดอัลกอริทึม MAS ในการตั้งค่านี้จะเป็นการดีกว่าที่จะตั้ง add_blank เป็น true หลังจากฝึกอบรมแบบจำลองในระดับหนึ่งแล้วสามารถพร้อมสำหรับกระบวนการแก้ไขการไหล การแก้ไขการไหลจำเป็นต้องสร้างข้อมูลโดยใช้โมเดลที่ผ่านการฝึกอบรมและใช้คู่ (เสียง, ข้อมูล) เพื่อฝึกอบรมโมเดลอีกครั้ง เนื่องจากกระบวนการนี้ควรเกี่ยวข้องกับชุดข้อมูลการฝึกอบรมทั้งหมดจึงแนะนำให้ทำงานบน GPU หลายตัวสำหรับการถอดรหัสแบบขนาน เราให้สคริปต์เพื่อทำสิ่งนี้:
# Set CUDA_VISIBLE_DEVICES, or the program will use all available GPUs.
python generate_for_reflow.py -c configs/ ${your_yaml} -m ${model_name}
--EMA --max-utt-num 100000000
--dataset train
--solver euler -t 10
--gt-dur
# --EMA specifies to load EMA checkpoint (latest)
# --max-utt-num sets the number of utterances to decode (in this case, arbitrarily high)
# --solver euler -t 10 specifies the solver and timesteps. Could be adaptive solvers like dopri5.
# --gt-dur forces the model to use ground truth duration for decoding. สิ่งนี้จะสร้าง synthetic_wav/${model_name}/generate_for_reflow/train สำหรับการจัดเก็บ noise.scp พร้อมกับ feats.scp จะถูกเก็บไว้ หลังจากถอดรหัสชุดการฝึกอบรมคุณยังสามารถถอดรหัสการตรวจสอบความถูกต้องที่กำหนดโดย --dataset val
จากนั้นระบุเส้นทางไปยัง feats.scp และ noise.scp ในการกำหนดค่าใหม่ Yaml เช่นใน lj_16k_gt_dur_reflow.yaml :
perform_reflow : true
...
data :
train :
feats_scp : " synthetic_wav/lj_16k_gt_dur/train/feats.scp "
noise_scp : " synthetic_wav/lj_16k_gt_dur/train/noise.scp "
...ตอนนี้พร้อมสำหรับการฝึกอบรมอีกครั้งใน Reflow ด้วยสคริปต์เดียวกันในการฝึกอบรม แต่ไฟล์กำหนดค่า YAML ใหม่ อย่าลังเลที่จะคัดลอกรูปแบบที่ผ่านการฝึกอบรมไปยังบันทึกใหม่เพื่อกลับมาทำงานต่อ นอกจากนี้ยังเป็นไปได้ที่จะเปลี่ยนโครงสร้างแบบจำลองและฝึกอบรมจากศูนย์ข้อมูล Reflow
คล้ายกับ "สร้างข้อมูลสำหรับ reflow" การอนุมานแบบจำลองสามารถทำได้โดย
python inference_dataset.py -c configs/ ${your_yaml} -m ${model_name} --EMA
--solver euler -t 10 สิ่งนี้จะสังเคราะห์ mel-spectrograms สำหรับชุดการตรวจสอบในการกำหนดค่าของคุณจัดเก็บไว้ที่ synthetic_wav/${model_name}/tts_gt_spk/feats.scp สามารถระบุลำโพงความเร็วและอุณหภูมิได้ ดู tools.get_hparams_decode() ฟังก์ชั่นสำหรับชุดตัวเลือกที่สมบูรณ์
การอนุมานนั้นสามารถทำได้ใน hifigan/ ไดเรกทอรี โปรดดู readme ที่นั่น
ในระหว่างการพัฒนาที่เก็บต่อไปนี้ถูกอ้างถึง:
utils/ ที่เก็บนี้ยังมีฟังก์ชันการทดลองบางอย่าง
การแปลงด้วยเสียง ในขณะที่ Glowtts สามารถทำการแปลงเสียงผ่านคุณสมบัติ disentangling ของการไหลของการไหลเป็นปกติจึงมีเหตุผลที่การจับคู่การไหลสามารถดำเนินการได้ Method model.tts.GradTTS.voice_conversion ให้การลองเบื้องต้น
การประเมินความน่าจะเป็น แบบจำลองการกำเนิดที่อิงสมการเชิงอนุพันธ์มีความสามารถในการประเมินความน่าจะเป็นข้อมูลโดยสูตรการเปลี่ยนแปลงแบบทันทีของตัวแปร
ในทางปฏิบัติอินทิกรัลจะถูกแทนที่ด้วยการรวมและความแตกต่างจะถูกแทนที่ด้วยตัวประมาณค่าการติดตาม Skilling-Hutchinson ดูภาคผนวก D.2 ในเพลงและ อัลสำหรับรายละเอียดทางทฤษฎี ฉันใช้สิ่งนี้ใน model.tts.GradTTS.compute_likelihood
model.cfm.OTCFM แม้ว่าตอนนี้จะทำงานได้ไม่ดีนักGradLogPEstimator2d โดยการกำหนดค่า model.fm_net_type ปัจจุบันรองรับสถาปัตยกรรมของตัวประมาณของ Diffsinger คุณสามารถเพิ่มได้มากขึ้นเช่นที่แนะนำใน Matcha-TTSmodel.tts.GradTTS.forward สนับสนุน Beta Binomial ก่อนหน้าสำหรับแผนที่การจัดตำแหน่ง; และถ้าคุณต้องการคุณสามารถเปลี่ยนตัวแปร MAS_target เป็นอย่างอื่นเช่นเสียงที่เปลี่ยนรูปแบบการไหล!อย่าลังเลที่จะอ้างถึงงานนี้ถ้ามันช่วยได้?
@INPROCEEDINGS{guo2024voiceflow,
author={Guo, Yiwei and Du, Chenpeng and Ma, Ziyang and Chen, Xie and Yu, Kai},
booktitle={ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={{VoiceFlow}: Efficient Text-To-Speech with Rectified Flow Matching},
year={2024},
volume={},
number={},
pages={11121-11125},
keywords={Signal processing algorithms;Signal processing;Acoustics;Mathematical models;Vectors;Trajectory;Speech processing;Text-to-speech;flow matching;rectified flow;efficiency;speed-quality tradeoff},
doi={10.1109/ICASSP48485.2024.10445948}
}


