VoiceFlow TTS
1.0.0
Il s'agit de la mise en œuvre officielle de notre flux de voix de papier ICASSP 2024.
Ce repo est testé sur Python 3.9 sur Linux. Vous pouvez configurer l'environnement avec conda
# Install required packages
conda create -n vflow python==3.9 # or any name you like
conda activate vflow
pip install -r requirements.txt
# Then, set PATH
source path.sh # change the env name in it if you don't use "vflow"
# Install monotonic_align for MAS
cd model/monotonic_align
python setup.py build_ext --inplace Notez que pour éviter le problème d'installer TorchDyn, nous copie directement la version TorchDyn 1.0.6 ici localement sur torchdyn/ .
Le processus suivant peut également nécessiter des commandes bash et perl dans votre environnement.
Ce repo s'appuie sur l'organisation de données de style Kaldi. Tous les fichiers de description de données doivent être placés dans des sous-répertoires dans data/ . Voir data/ljspeech/example pour un exemple de base. Dans cet exemple, les fichiers de texte brut suivant sont nécessaires:
wav.scp : organisé en utt /path/to/wav .utts.list : Chaque ligne spécifie un énoncé. Ceci peut être obtenu par cut -d ' ' -f 1 wav.scp > utts.list .utt2spk : organisé en tant que utt spk_name .text et phn_duration : Spécifie la séquence de phonèmes et les durées entières correspondantes (dans des cadres). En outre, il existe un fichier data/ljspeech/phones.txt pour spécifier tous les téléphones avec leurs index dans Dictionary. Pour LJSpeech, nous fournissons le fichier traité en ligne. Vous pouvez le télécharger et vous décompresser sur data/ljspeech/{train,val} . Si vous souhaitez vous entraîner sur votre propre ensemble de données, vous devrez peut-être créer ces fichiers vous-même (ou modifier la stratégie de chargement des données).
Après avoir eu ces fichiers manifestes, veuillez procéder à ce qui suit pour extraire le spectrogramme MEL pour la formation:
bash extract_fbank.sh --stage 0 --stop_stage 2 --nj 16
# nj: number of parallel jobs.
# Have a look into the script if you need to change something
# Bash variables before "parse_options.sh" can be passed by CLI, e.g. "--key value". Notez que nous utilisons par défaut d'utiliser des données 16KHz ici. Cela créera feats/fbank et feats/normed_fbank , où les fichiers SCP et ARK de style Kaldi-Style stockent les données de spectrogramme MEL. Les fonctionnalités normales seront utilisées pour la formation.
Si vous souhaitez utiliser Speaker-IDS (comme LJSpeech, au lieu d'utiliser des incorporations de haut-parleurs pré-entraînées telles que XVectors) pour la formation, veuillez exécuter:
make_utt2spk_id.py data/ljspeech/train/utt2spk data/ljspeech/val/utt2spk
# You can add more files in CLI. Will write utt2num_frames in the same directory to these files. Les configurations de formation sont stockées sous forme de fichier YAML dans configs/ . Les manifestes de données et les fonctionnalités pour la formation et le jeu de validation seront spécifiées dans ces fichiers YAML. Vous devrez y modifier des chemins de fichiers à double qualité si vous devez vous entraîner sur vos propres données.
Ensuite, la formation est effectuée par
python train.py -c configs/ ${your_yaml} -m ${model_name}
# e.g. python train.py -c configs/lj_16k_gt_dur.yaml -m lj_16k_gt_dur Il créera logs/${model_name} pour la journalisation et le point de contrôle.
Plusieurs notes:
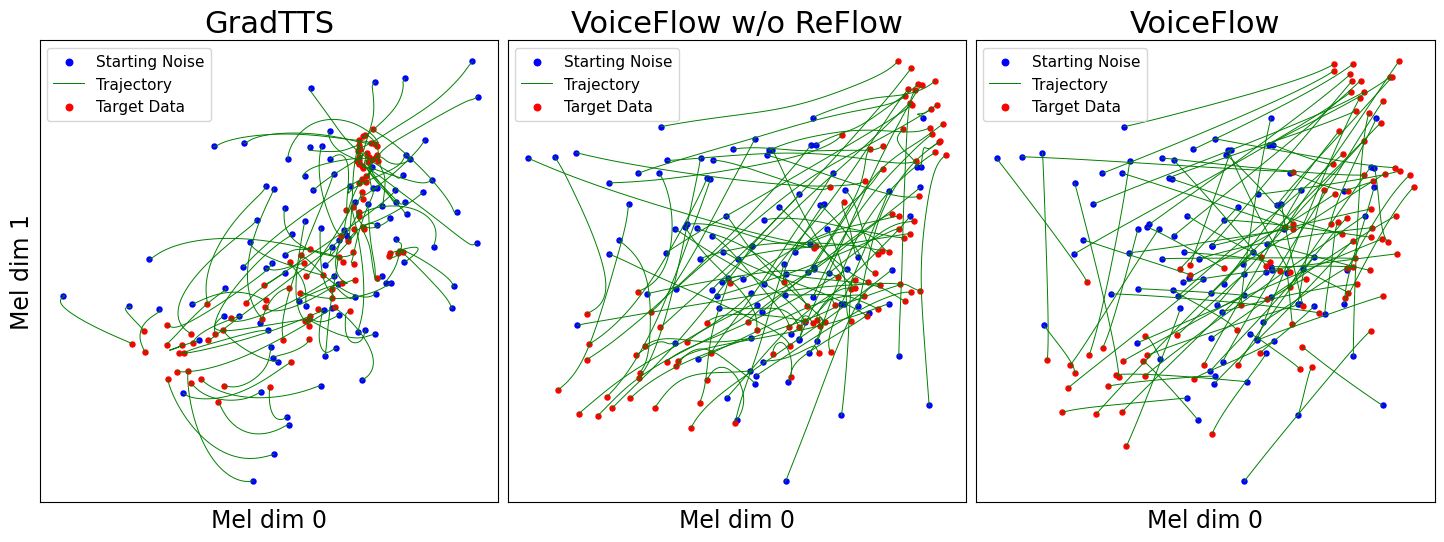
use_gt_dur sur false pour activer l'algorithme MAS. Dans ce paramètre, il est préférable de définir add_blank sur true . Après avoir entraîné le modèle dans une certaine mesure, il peut être prêt pour le processus de rectification de flux. La rectification de flux nécessite de générer des données à l'aide du modèle formé et d'utiliser la paire (bruit, données) pour former à nouveau le modèle. Comme ce processus doit toujours impliquer l'ensemble de données de formation, il est recommandé d'exécuter plusieurs GPU pour le décodage parallèle. Nous fournissons un script pour ce faire:
# Set CUDA_VISIBLE_DEVICES, or the program will use all available GPUs.
python generate_for_reflow.py -c configs/ ${your_yaml} -m ${model_name}
--EMA --max-utt-num 100000000
--dataset train
--solver euler -t 10
--gt-dur
# --EMA specifies to load EMA checkpoint (latest)
# --max-utt-num sets the number of utterances to decode (in this case, arbitrarily high)
# --solver euler -t 10 specifies the solver and timesteps. Could be adaptive solvers like dopri5.
# --gt-dur forces the model to use ground truth duration for decoding. Cela créera synthetic_wav/${model_name}/generate_for_reflow/train pour le stockage. noise.scp avec feats.scp sera stocké. Après le décodage de l'ensemble de formation, vous pouvez également décoder la validation définie par --dataset val .
Ensuite, spécifiez les chemins de ces feats.scp et noise.scp dans une nouvelle configuration YAML, comme dans le lj_16k_gt_dur_reflow.yaml :
perform_reflow : true
...
data :
train :
feats_scp : " synthetic_wav/lj_16k_gt_dur/train/feats.scp "
noise_scp : " synthetic_wav/lj_16k_gt_dur/train/noise.scp "
...Maintenant, il est à nouveau prêt pour la formation à Reflow, avec le même script en formation mais de nouveaux fichiers YAML Config. N'hésitez pas à copier un modèle formé au nouveau journal de journal pour reprendre. En outre, il est possible de modifier la structure du modèle et de s'entraîner à partir de zéro sur les données de reflux.
Semblable à "Générer des données pour reflux", l'inférence du modèle peut être effectuée par
python inference_dataset.py -c configs/ ${your_yaml} -m ${model_name} --EMA
--solver euler -t 10 Cela synthétisera les spectrogrammes de MEL pour l'ensemble de validation dans votre configuration, les stockant sur synthetic_wav/${model_name}/tts_gt_spk/feats.scp . Le haut-parleur, la vitesse et la température peuvent être spécifiés; Voir la fonction tools.get_hparams_decode() pour un ensemble complet d'options.
L'inférence peut alors être effectuée dans le hifigan/ RÉPERTOIRE. Veuillez vous référer à la lecture là-bas.
Au cours du développement, les référentiels suivants ont été mentionnés:
utils/ . Ce référentiel contient également certaines fonctionnalités expérimentales.
Conversion vocale . Comme GlowTTS peut effectuer une conversion vocale via la propriété de démontage des flux de normalisation, il est raisonnable que la correspondance du débit puisse également l'effectuer. Method model.tts.GradTTS.voice_conversion donne un essai préliminaire.
Estimation de vraisemblance . Les modèles génératifs basés sur l'équation différentielle ont la capacité d'estimer la probabilité des données par la formule de changement de variable instantanée
En pratique, l'intégrale est remplacée par la sommation et la divergence est remplacée par l'estimateur de trace de Skinling-Hutchinson. Voir l'annexe D.2 dans Song, et. Al pour les détails théoriques. J'ai implémenté cela dans model.tts.GradTTS.compute_likelihood .
model.cfm.OTCFM , bien qu'il ne fonctionne pas très bien pour l'instant.GradLogPEstimator2d par la configuration model.fm_net_type . Actuellement, l'architecture de l'estimateur du Diffsinger est également prise en charge. Vous pouvez en ajouter plus, par exemple qui a été introduit dans Matcha-TTS.model.tts.GradTTS.forward soutient désormais Beta Binomial Prior pour les cartes d'alignement; Et si vous le souhaitez, vous pouvez modifier la variable MAS_target en autre chose, par exemple, le bruit transformé en flux!N'hésitez pas à citer ce travail si cela aide?
@INPROCEEDINGS{guo2024voiceflow,
author={Guo, Yiwei and Du, Chenpeng and Ma, Ziyang and Chen, Xie and Yu, Kai},
booktitle={ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={{VoiceFlow}: Efficient Text-To-Speech with Rectified Flow Matching},
year={2024},
volume={},
number={},
pages={11121-11125},
keywords={Signal processing algorithms;Signal processing;Acoustics;Mathematical models;Vectors;Trajectory;Speech processing;Text-to-speech;flow matching;rectified flow;efficiency;speed-quality tradeoff},
doi={10.1109/ICASSP48485.2024.10445948}
}


