VoiceFlow TTS
1.0.0
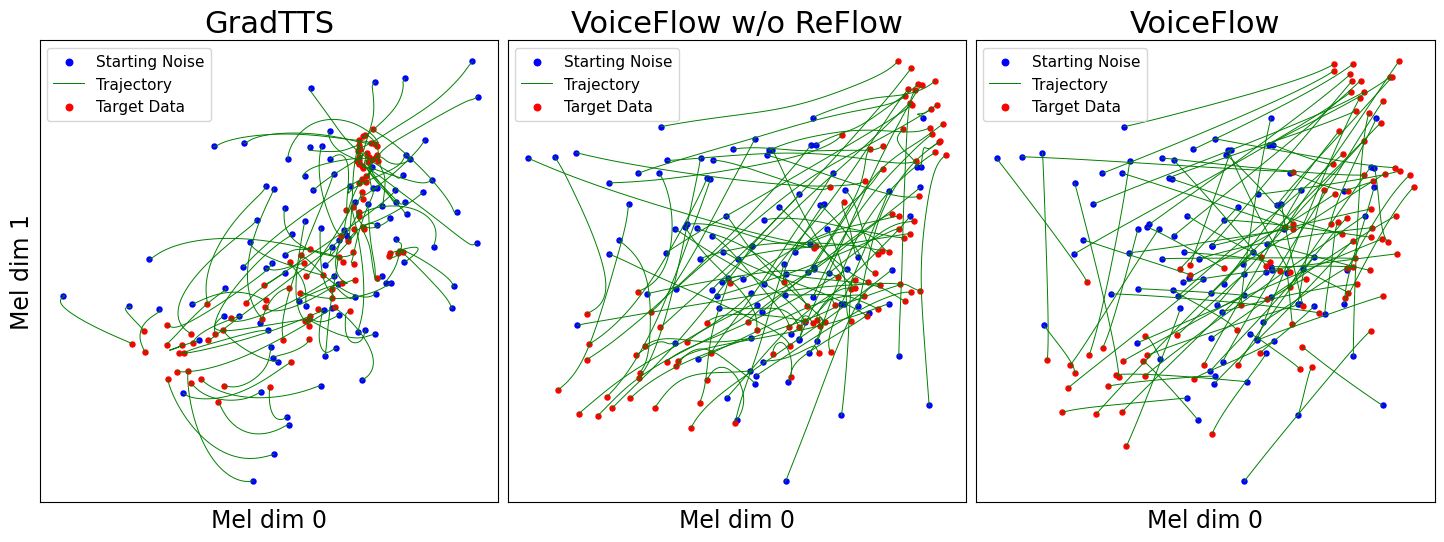
Ini adalah implementasi resmi dari voiceflow kertas ICASSP 2024 kami.
Repo ini diuji pada Python 3.9 di Linux. Anda dapat mengatur lingkungan dengan conda
# Install required packages
conda create -n vflow python==3.9 # or any name you like
conda activate vflow
pip install -r requirements.txt
# Then, set PATH
source path.sh # change the env name in it if you don't use "vflow"
# Install monotonic_align for MAS
cd model/monotonic_align
python setup.py build_ext --inplace Perhatikan bahwa untuk menghindari kesulitan menginstal Torchdyn, kami langsung menyalin versi Torchdyn 1.0.6 di sini secara lokal di torchdyn/ .
Proses berikut mungkin juga membutuhkan perintah bash dan perl di lingkungan Anda.
Repo ini bergantung pada organisasi data gaya Kaldi. Semua file deskripsi data harus dimasukkan ke dalam subdirektori dalam data/ . Lihat data/ljspeech/example untuk contoh dasar. Dalam contoh ini, file teks biasa berikut diperlukan:
wav.scp : Diorganisasikan sebagai utt /path/to/wav .utts.list : Setiap baris menentukan ucapan. Ini dapat diperoleh dengan cut -d ' ' -f 1 wav.scp > utts.list .utt2spk : Diorganisasikan sebagai utt spk_name .text dan phn_duration : Menentukan urutan fonem dan durasi integer yang sesuai (dalam bingkai). Juga, ada file data/ljspeech/phones.txt untuk menentukan semua ponsel bersama dengan indeks mereka dalam kamus. Untuk LJSPEECH, kami menyediakan file yang diproses secara online. Anda dapat mengunduhnya dan unzip ke data/ljspeech/{train,val} . Jika Anda ingin berlatih pada dataset Anda sendiri, Anda mungkin harus membuat file -file ini sendiri (atau mengubah strategi pemuatan data).
Setelah memiliki file manifes ini, silakan lakukan hal berikut untuk mengekstrak Mel-Spectrogram untuk pelatihan:
bash extract_fbank.sh --stage 0 --stop_stage 2 --nj 16
# nj: number of parallel jobs.
# Have a look into the script if you need to change something
# Bash variables before "parse_options.sh" can be passed by CLI, e.g. "--key value". Perhatikan bahwa kami default untuk menggunakan data 16kHz di sini. Ini akan membuat feats/fbank dan feats/normed_fbank , di mana file SCP dan ARK gaya Kaldi menyimpan data Mel-Spectrogram. Fitur normed akan digunakan untuk pelatihan.
Jika Anda ingin menggunakan speaker-id (seperti ljspeech, alih-alih menggunakan embeddings speaker pretrained seperti xvectors) untuk pelatihan, silakan jalankan:
make_utt2spk_id.py data/ljspeech/train/utt2spk data/ljspeech/val/utt2spk
# You can add more files in CLI. Will write utt2num_frames in the same directory to these files. Konfigurasi untuk pelatihan disimpan sebagai file YAML di configs/ . Data manifes dan fitur untuk pelatihan dan set validasi akan ditentukan dalam file YAML tersebut. Anda perlu mengubah jalur file yang dikutip ganda di sana jika Anda perlu berlatih di data Anda sendiri.
Kemudian, pelatihan dilakukan oleh
python train.py -c configs/ ${your_yaml} -m ${model_name}
# e.g. python train.py -c configs/lj_16k_gt_dur.yaml -m lj_16k_gt_dur Ini akan membuat logs/${model_name} untuk logging dan pos pemeriksaan.
Beberapa catatan:
use_gt_dur ke false untuk mengaktifkan algoritma MAS. Dalam pengaturan ini, lebih baik mengatur add_blank ke true . Setelah melatih model sampai taraf tertentu, itu bisa siap untuk proses perbaikan aliran. Perbaikan aliran memerlukan untuk menghasilkan data menggunakan model terlatih dan menggunakan pasangan (noise, data) untuk melatih model lagi. Karena proses ini harus selalu melibatkan seluruh dataset pelatihan, disarankan untuk berjalan pada beberapa GPU untuk decoding paralel. Kami menyediakan skrip untuk melakukan ini:
# Set CUDA_VISIBLE_DEVICES, or the program will use all available GPUs.
python generate_for_reflow.py -c configs/ ${your_yaml} -m ${model_name}
--EMA --max-utt-num 100000000
--dataset train
--solver euler -t 10
--gt-dur
# --EMA specifies to load EMA checkpoint (latest)
# --max-utt-num sets the number of utterances to decode (in this case, arbitrarily high)
# --solver euler -t 10 specifies the solver and timesteps. Could be adaptive solvers like dopri5.
# --gt-dur forces the model to use ground truth duration for decoding. Ini akan membuat synthetic_wav/${model_name}/generate_for_reflow/train untuk penyimpanan. noise.scp bersama dengan feats.scp akan disimpan. Setelah mendekode set pelatihan, Anda juga dapat memecahkan kode validasi yang ditetapkan oleh --dataset val .
Kemudian, tentukan jalur ke feats.scp dan noise.scp ini dalam konfigurasi baru YAML, seperti di lj_16k_gt_dur_reflow.yaml :
perform_reflow : true
...
data :
train :
feats_scp : " synthetic_wav/lj_16k_gt_dur/train/feats.scp "
noise_scp : " synthetic_wav/lj_16k_gt_dur/train/noise.scp "
...Sekarang siap untuk pelatihan lagi di Reflow, dengan skrip yang sama dalam pelatihan tetapi file konfigurasi YAML baru. Jangan ragu untuk menyalin model terlatih ke Dir Log baru untuk dilanjutkan. Juga, dimungkinkan untuk mengubah struktur model dan melatih dari awal pada data reflow.
Mirip dengan "menghasilkan data untuk reflow", inferensi model dapat dilakukan dengan
python inference_dataset.py -c configs/ ${your_yaml} -m ${model_name} --EMA
--solver euler -t 10 Ini akan mensintesis mel-spectrograms untuk validasi yang ditetapkan dalam konfigurasi Anda, menyimpannya di synthetic_wav/${model_name}/tts_gt_spk/feats.scp . Speaker, kecepatan dan suhu dapat ditentukan; Lihat Fungsi tools.get_hparams_decode() untuk set opsi lengkap.
Inferensi kemudian dapat dilakukan di hifigan/ direktori. Silakan merujuk ke readme di sana.
Selama pengembangan, repositori berikut dirujuk:
utils/ . Repositori ini juga berisi beberapa fungsi eksperimental.
Konversi suara . Karena GLOWTTS dapat melakukan konversi suara melalui properti pemasangan aliran normalisasi, masuk akal bahwa pencocokan aliran juga dapat melakukannya. Metode model.tts.GradTTS.voice_conversion memberikan percobaan awal.
Estimasi kemungkinan . Model generatif berbasis persamaan diferensial memiliki kemampuan untuk memperkirakan kemungkinan data dengan formula perubahan variabel instan
Dalam praktiknya, integral digantikan oleh penjumlahan, dan divergensi digantikan oleh penaksir Jejak Skilling-Hutchinson. Lihat Lampiran D.2 di Song, et. Al untuk detail teoretis. Saya menerapkan ini di model.tts.GradTTS.compute_likelihood
model.cfm.OTCFM , meskipun tidak berfungsi dengan baik untuk saat ini.GradLogPEstimator2d oleh konfigurasi model.fm_net_type . Saat ini arsitektur estimator Diffsinger juga didukung. Anda dapat menambahkan lebih banyak, misalnya yang diperkenalkan di Matcha-TTS.model.tts.GradTTS.forward sekarang mendukung beta binomial sebelumnya untuk peta penyelarasan; Dan jika Anda mau, Anda dapat mengubah variabel MAS_target menjadi sesuatu yang lain, misalnya noise transformed flow!Jangan ragu untuk mengutip pekerjaan ini jika membantu?
@INPROCEEDINGS{guo2024voiceflow,
author={Guo, Yiwei and Du, Chenpeng and Ma, Ziyang and Chen, Xie and Yu, Kai},
booktitle={ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={{VoiceFlow}: Efficient Text-To-Speech with Rectified Flow Matching},
year={2024},
volume={},
number={},
pages={11121-11125},
keywords={Signal processing algorithms;Signal processing;Acoustics;Mathematical models;Vectors;Trajectory;Speech processing;Text-to-speech;flow matching;rectified flow;efficiency;speed-quality tradeoff},
doi={10.1109/ICASSP48485.2024.10445948}
}


