tianshou
v1.1.0

Tianshou (天授天授) เป็นห้องสมุดการเรียนรู้เสริมแรง (RL) โดยใช้ pytorch บริสุทธิ์และโรงยิม คุณสมบัติหลักของ Tianshou ได้อย่างรวดเร็วคือ:
ซึ่งแตกต่างจากห้องสมุดการเรียนรู้การเสริมแรงอื่น ๆ ซึ่งอาจมีรหัสฐานที่ซับซ้อน API ระดับสูงที่ไม่เป็นมิตรหรือไม่ได้รับการปรับให้เหมาะสมสำหรับความเร็ว Tianshou ให้เฟรมเวิร์กที่มีประสิทธิภาพสูงและเป็นโมดูลและอินเทอร์เฟซที่เป็นมิตรกับผู้ใช้สำหรับการสร้างตัวแทนการเรียนรู้เสริมแรง อีกแง่มุมหนึ่งที่ทำให้ Tianshou แตกต่างคือทั่วไป: รองรับ RL ออนไลน์และออฟไลน์, RL หลายตัวแทนและอัลกอริทึมตามรุ่น
Tianshou มีเป้าหมายที่จะเปิดใช้งานการใช้งานที่กระชับทั้งสำหรับนักวิจัยและผู้ปฏิบัติงานโดยไม่ต้องเสียสละความยืดหยุ่น
อัลกอริทึมที่รองรับ ได้แก่ :
คุณสมบัติที่สำคัญอื่น ๆ :
ในภาษาจีน Tianshou หมายถึงการบวชของพระเจ้าได้รับของประทานจากการเกิด Tianshou เป็นแพลตฟอร์มการเรียนรู้เสริมแรงและธรรมชาติของ RL ไม่ได้เรียนรู้จากมนุษย์ ดังนั้นการใช้ "tianshou" หมายความว่าไม่มีครูที่จะเรียนรู้จาก แต่การเรียนรู้ด้วยตนเองผ่านการมีปฏิสัมพันธ์กับสภาพแวดล้อมอย่างต่อเนื่อง
“ 天授” 意指上天所授, 引申为与生具有的天赋。天授是强化学习平台, 而强化学习算法并不是向人类学习的, 所以取“ 天授” 意思是没有老师来教, 而是自己通过跟环境不断交互来进行学习。而是自己通过跟环境不断交互来进行学习。
Tianshou เป็นเจ้าภาพใน PYPI และ Conda-Forge มันต้องใช้ Python> = 3.11
สำหรับการติดตั้ง Tianshou เวอร์ชันล่าสุดวิธีที่ดีที่สุดคือโคลนที่เก็บและติดตั้งด้วยบทกวี (ซึ่งคุณต้องติดตั้งในระบบของคุณก่อน)
git clone [email protected]:thu-ml/tianshou.git
cd tianshou
poetry install นอกจากนี้คุณยังสามารถติดตั้งข้อกำหนดของ DEV ได้โดยการเพิ่ม --with dev หรือ extras สำหรับ mujoco และการเร่งความเร็วโดย envpool โดยการเพิ่ม --extras "mujoco envpool"
หากคุณต้องการติดตั้งความพิเศษหลายรายการตรวจสอบให้แน่ใจว่าคุณรวมไว้ในคำสั่งเดียว การโทรตามลำดับไปยัง poetry install --extras xxx จะเขียนทับการติดตั้งก่อนหน้าโดยเหลือเฉพาะการติดตั้งพิเศษล่าสุดที่ติดตั้งเท่านั้น หรือคุณอาจติดตั้งสิ่งพิเศษทั้งหมดต่อไปนี้โดยเพิ่ม --all-extras
ความพิเศษที่มีอยู่คือ:
atari (สำหรับสภาพแวดล้อมของอาตาริ)box2d (สำหรับสภาพแวดล้อม Box2D)classic_control (สำหรับสภาพแวดล้อมการควบคุมแบบคลาสสิก (ไม่ต่อเนื่อง))mujoco (สำหรับสภาพแวดล้อม Mujoco)mujoco-py (สำหรับสภาพแวดล้อม MUJOCO-PY ดั้งเดิม 1 )pybullet (สำหรับสภาพแวดล้อม pybullet)robotics (สำหรับสภาพแวดล้อมโรงยิม-โรสvizdoom (สำหรับสภาพแวดล้อม Vizdoom)envpool (สำหรับการรวม Envpool)argparse (เพื่อให้สามารถเรียกใช้ตัวอย่าง API ระดับสูงได้)มิฉะนั้นคุณสามารถติดตั้งรีลีสล่าสุดจาก PYPI (ปัจจุบันอยู่ด้านหลังต้นแบบ) ด้วยคำสั่งต่อไปนี้:
$ pip install tianshouหากคุณใช้ Anaconda หรือ Miniconda คุณสามารถติดตั้ง Tianshou จาก Conda-Forge:
$ conda install tianshou -c conda-forgeอีกทางเลือกหนึ่งในการติดตั้งบทกวีคุณยังสามารถติดตั้งเวอร์ชันต้นฉบับล่าสุดผ่าน GitHub:
$ pip install git+https://github.com/thu-ml/tianshou.git@master --upgradeสุดท้ายคุณสามารถตรวจสอบการติดตั้งผ่านคอนโซล Python ของคุณดังนี้:
import tianshou
print ( tianshou . __version__ )หากไม่มีการรายงานข้อผิดพลาดคุณได้ติดตั้ง Tianshou สำเร็จแล้ว
เอกสารบทเรียนและ API จัดทำขึ้นบน tianshou.readthedocs.io
ค้นหาตัวอย่างสคริปต์ในการทดสอบ/ และตัวอย่าง/ โฟลเดอร์
| แพลตฟอร์ม RL | เอกสาร | ความครอบคลุมของรหัส | พิมพ์คำแนะนำ | อัปเดตล่าสุด |
|---|---|---|---|---|
| เสถียร -Baselines3 | ||||
| เรย์/rllib | ➖ (1) | |||
| การปั่น | ||||
| โดปามีน | ||||
| Acme | ➖ (1) | |||
| โรงงานตัวอย่าง | ||||
| Tianshou |
(1): มีการรวมอย่างต่อเนื่อง แต่อัตราความครอบคลุมไม่สามารถใช้ได้
Tianshou ได้รับการทดสอบอย่างเข้มงวด ตรงกันข้ามกับแพลตฟอร์ม RL อื่น ๆ การทดสอบของเรารวมถึงขั้นตอนการฝึกอบรมตัวแทนเต็มรูปแบบสำหรับอัลกอริทึมที่ดำเนินการทั้งหมด การทดสอบของเราจะล้มเหลวหนึ่งครั้งหากตัวแทนใด ๆ ล้มเหลวในการบรรลุระดับประสิทธิภาพที่สอดคล้องกันในยุคที่ จำกัด การทดสอบของเราทำให้มั่นใจได้ว่าจะทำซ้ำได้ ตรวจสอบหน้าการกระทำของ GitHub เพื่อดูรายละเอียดเพิ่มเติม
ผลการวัดค่ามาตรฐาน Atari และ Mujoco สามารถพบได้ในตัวอย่าง/ Atari/ และตัวอย่าง/ Mujoco/ Folders ตามลำดับ ผลลัพธ์ Mujoco ของเราเข้าถึงหรือเกินระดับประสิทธิภาพของเกณฑ์มาตรฐานที่มีอยู่ส่วนใหญ่
อัลกอริทึมทั้งหมดใช้ API ทั่วไปสูงต่อไปนี้:
__init__ : เริ่มต้นนโยบาย;forward : คำนวณการกระทำตามการสังเกตที่กำหนด;process_buffer : กระบวนการบัฟเฟอร์เริ่มต้นซึ่งมีประโยชน์สำหรับอัลกอริทึมการเรียนรู้ออฟไลน์บางอย่างprocess_fn : ข้อมูลประมวลผลล่วงหน้าจากบัฟเฟอร์การเล่นซ้ำ (เนื่องจากเราได้ปรับอัลกอริทึม ทั้งหมด เพื่อเล่นซ้ำอัลกอริทึมที่ใช้บัฟเฟอร์);learn : เรียนรู้จากชุดข้อมูลที่กำหนดpost_process_fn : อัปเดตบัฟเฟอร์การเล่นซ้ำจากกระบวนการเรียนรู้ (เช่นบัฟเฟอร์การเล่นซ้ำที่จัดลำดับความสำคัญจำเป็นต้องอัปเดตน้ำหนัก);update : อินเทอร์เฟซหลักสำหรับการฝึกอบรมเช่น process_fn -> learn -> post_process_fnการใช้งาน API นี้เพียงพอสำหรับอัลกอริทึมใหม่ที่จะนำไปใช้ภายใน Tianshou ทำการทดลองด้วยวิธีการใหม่โดยเฉพาะอย่างยิ่งตรงไปตรงมา
Tianshou ให้สองระดับ API:
ในต่อไปนี้ให้เราพิจารณาแอปพลิเคชันตัวอย่างโดยใช้สภาพแวดล้อม Cartpole Gymnasium เราจะใช้อัลกอริทึมการเรียนรู้เครือข่าย Deep Q (DQN) โดยใช้ API ทั้งสอง
ในการเริ่มต้นเราต้องการการนำเข้าบางอย่าง
from tianshou . highlevel . config import SamplingConfig
from tianshou . highlevel . env import (
EnvFactoryRegistered ,
VectorEnvType ,
)
from tianshou . highlevel . experiment import DQNExperimentBuilder , ExperimentConfig
from tianshou . highlevel . params . policy_params import DQNParams
from tianshou . highlevel . trainer import (
EpochTestCallbackDQNSetEps ,
EpochTrainCallbackDQNSetEps ,
EpochStopCallbackRewardThreshold
) ใน API ระดับสูงพื้นฐานสำหรับการทดลอง RL คือ ExperimentBuilder ที่เราสามารถสร้างการทดลองที่เราพยายามวิ่ง เนื่องจากเราต้องการใช้ DQN เราจึงใช้ความเชี่ยวชาญเฉพาะด้าน DQNExperimentBuilder การนำเข้าอื่น ๆ ให้บริการเพื่อให้ตัวเลือกการกำหนดค่าสำหรับการทดสอบของเรา
API ระดับสูงให้ความหมายที่ประกาศอย่างมากคือรหัสนั้นเกี่ยวข้องกับการกำหนดค่าที่ควบคุมสิ่งที่ต้องทำ (แทนที่จะทำอย่างไร)
experiment = (
DQNExperimentBuilder (
EnvFactoryRegistered ( task = "CartPole-v1" , train_seed = 0 , test_seed = 0 , venv_type = VectorEnvType . DUMMY ),
ExperimentConfig (
persistence_enabled = False ,
watch = True ,
watch_render = 1 / 35 ,
watch_num_episodes = 100 ,
),
SamplingConfig (
num_epochs = 10 ,
step_per_epoch = 10000 ,
batch_size = 64 ,
num_train_envs = 10 ,
num_test_envs = 100 ,
buffer_size = 20000 ,
step_per_collect = 10 ,
update_per_step = 1 / 10 ,
),
)
. with_dqn_params (
DQNParams (
lr = 1e-3 ,
discount_factor = 0.9 ,
estimation_step = 3 ,
target_update_freq = 320 ,
),
)
. with_model_factory_default ( hidden_sizes = ( 64 , 64 ))
. with_epoch_train_callback ( EpochTrainCallbackDQNSetEps ( 0.3 ))
. with_epoch_test_callback ( EpochTestCallbackDQNSetEps ( 0.0 ))
. with_epoch_stop_callback ( EpochStopCallbackRewardThreshold ( 195 ))
. build ()
)
experiment . run ()ตัวสร้างการทดลองใช้สามข้อโต้แย้ง:
watch=True ) สำหรับหลายตอน ( watch_num_episodes=100 ) เราได้ปิดการใช้งานการคงอยู่เนื่องจากเราไม่ต้องการบันทึกบันทึกการฝึกอบรมตัวแทนหรือการกำหนดค่าสำหรับการใช้งานในอนาคตnum_epochs=10 )step_per_epoch=10000 ) ทุกยุคสมัยประกอบด้วยขั้นตอนการรวบรวมข้อมูล (ขั้นตอนการฝึกอบรม) และขั้นตอนการฝึกอบรม พารามิเตอร์ step_per_collect จะควบคุมปริมาณข้อมูลที่รวบรวมในแต่ละขั้นตอนการรวบรวมและหลังจากแต่ละขั้นตอนการรวบรวมเราดำเนินการขั้นตอนการฝึกอบรมโดยใช้การอัปเดตตามการไล่ระดับสีตามตัวอย่างของข้อมูล ( batch_size=64 ) ที่นำมาจากบัฟเฟอร์ของข้อมูลที่รวบรวม สำหรับรายละเอียดเพิ่มเติมดูเอกสารประกอบของ SamplingConfigจากนั้นเราจะดำเนินการกำหนดค่าพารามิเตอร์บางอย่างของอัลกอริทึม DQN เองและของโมเดลเครือข่ายประสาทที่เราต้องการใช้ รายละเอียดเฉพาะ DQN คือการใช้การเรียกกลับเพื่อกำหนดค่าพารามิเตอร์ epsilon ของอัลกอริทึมสำหรับการสำรวจ เราต้องการใช้การสำรวจแบบสุ่มในระหว่างการเปิดตัว (การโทรกลับรถไฟ) แต่เราไม่ได้เมื่อประเมินประสิทธิภาพของตัวแทนในสภาพแวดล้อมการทดสอบ (ทดสอบการโทรกลับ)
ค้นหาสคริปต์ในตัวอย่าง/discrete/discrete_dqn_hl.py นี่คือการวิ่ง (ด้วยเวลาฝึกซ้อมสั้น ๆ ):
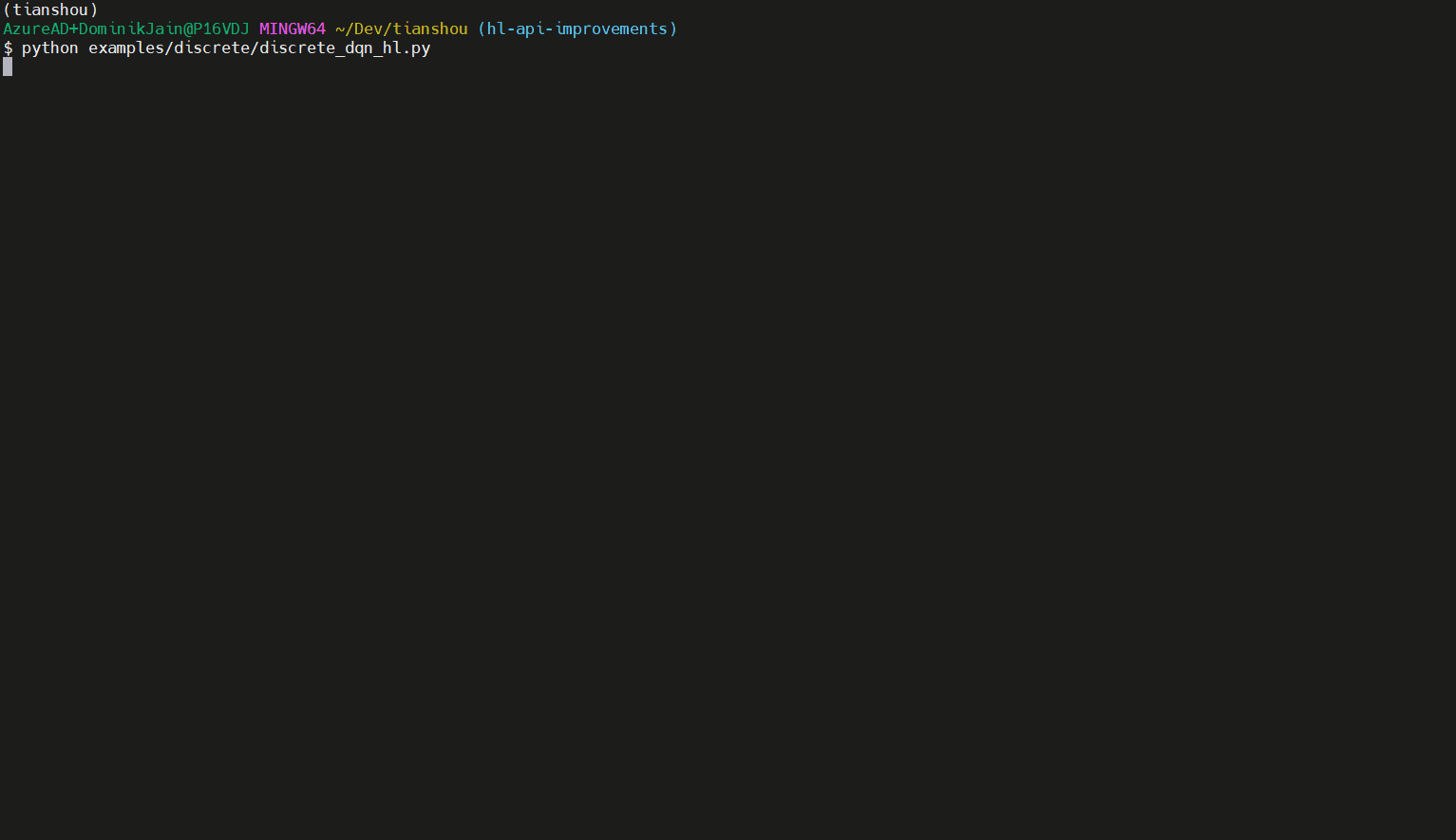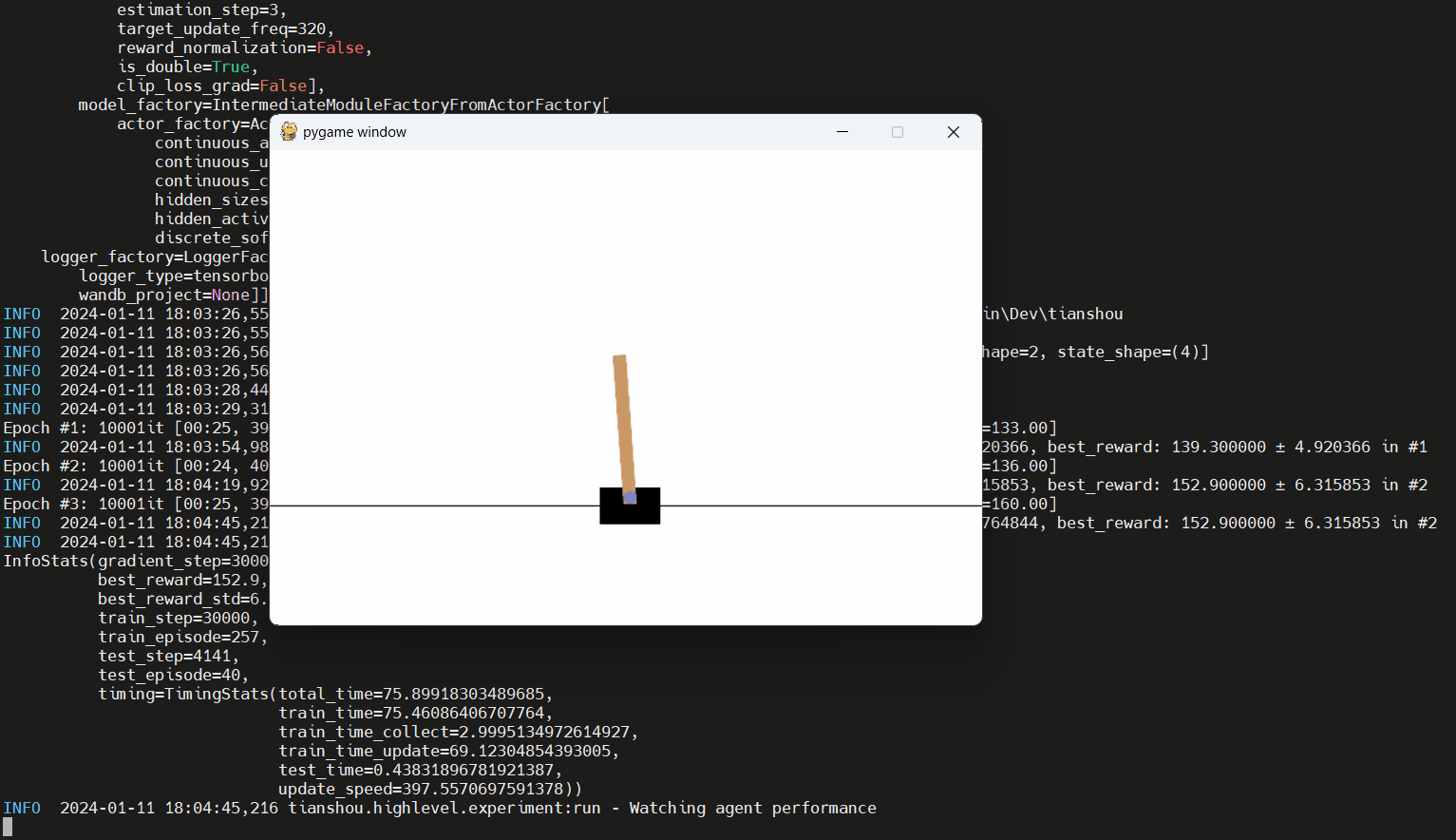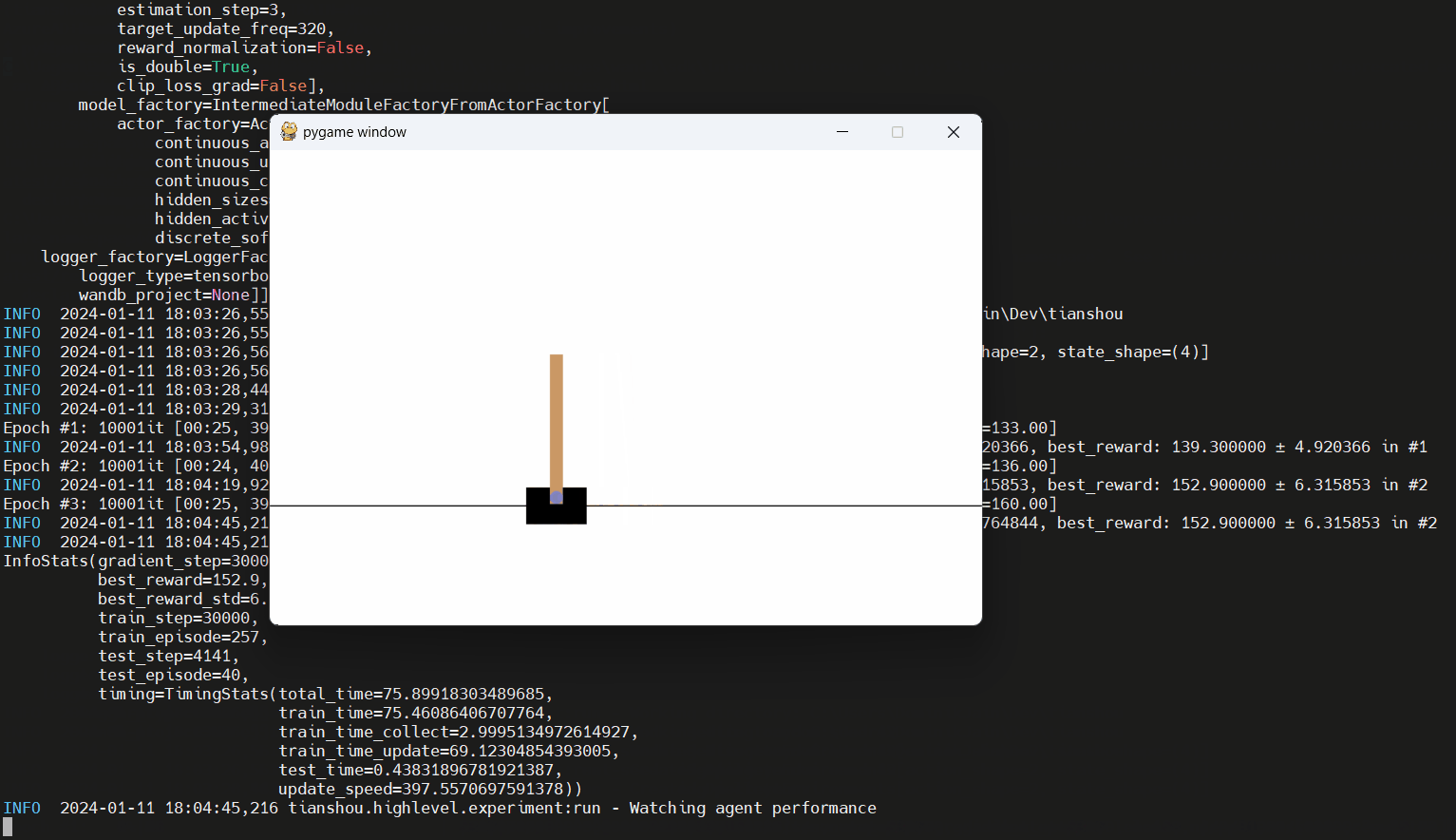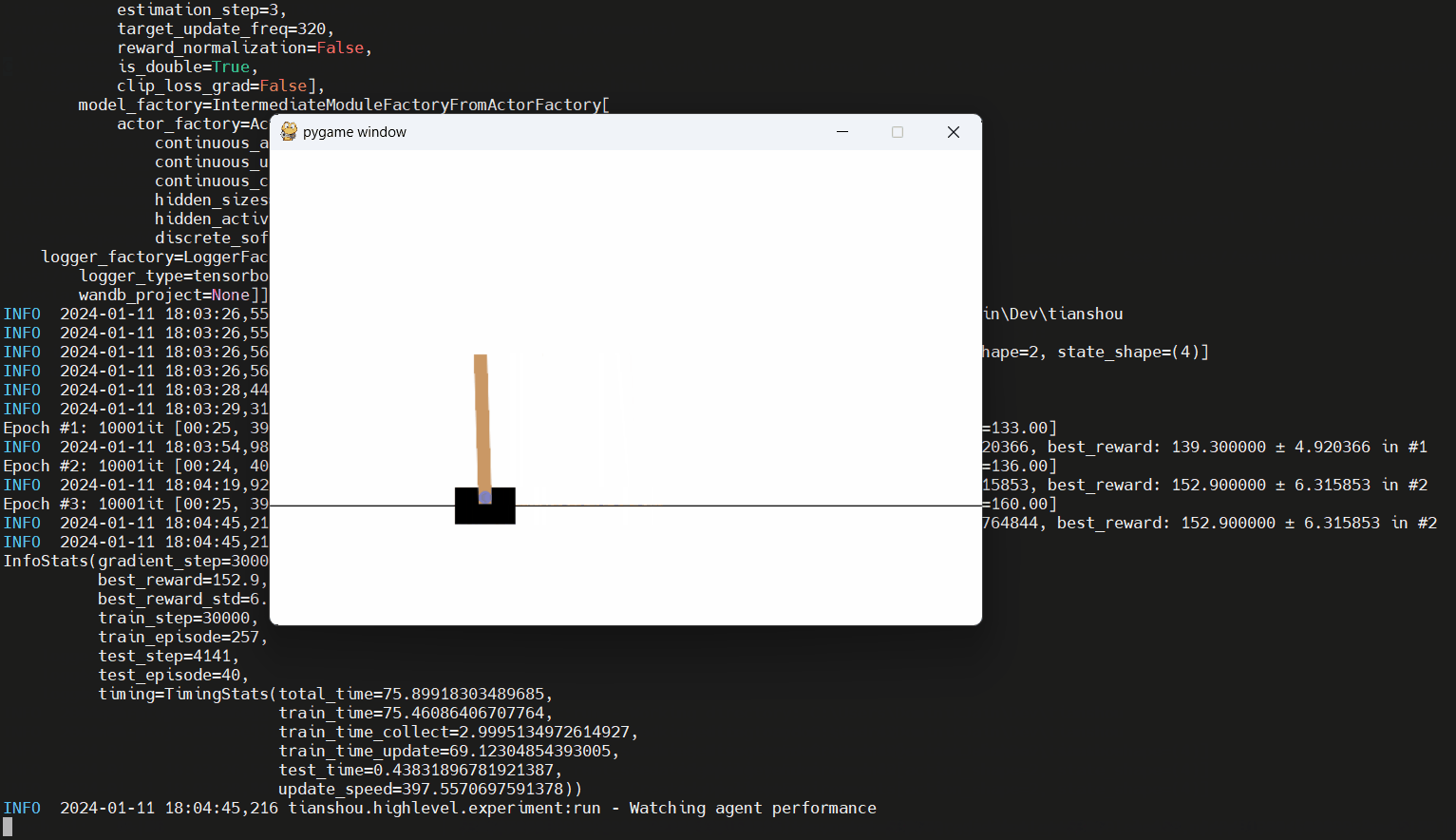
ค้นหาแอปพลิเคชั่นเพิ่มเติมของ API ระดับสูงใน examples/ โฟลเดอร์เพิ่มเติม มองหาสคริปต์ที่ลงท้ายด้วย _hl.py โปรดทราบว่าตัวอย่างเหล่านี้ส่วนใหญ่ต้องการแพ็คเกจพิเศษ argparse (ติดตั้งโดยการเพิ่ม --extras argparse เมื่อเรียกใช้บทกวี)
ให้เราพิจารณาตัวอย่างที่คล้ายคลึงกันใน API ขั้นตอน ค้นหาสคริปต์เต็มในตัวอย่าง/discrete/discrete_dqn.py
ขั้นแรกให้นำเข้าแพ็คเกจที่เกี่ยวข้อง:
import gymnasium as gym
import torch
from torch . utils . tensorboard import SummaryWriter
import tianshou as tsกำหนดพารามิเตอร์ไฮเปอร์:
task = 'CartPole-v1'
lr , epoch , batch_size = 1e-3 , 10 , 64
train_num , test_num = 10 , 100
gamma , n_step , target_freq = 0.9 , 3 , 320
buffer_size = 20000
eps_train , eps_test = 0.1 , 0.05
step_per_epoch , step_per_collect = 10000 , 10เริ่มต้นเครื่องบันทึก:
logger = ts . utils . TensorboardLogger ( SummaryWriter ( 'log/dqn' ))
# For other loggers, see https://tianshou.readthedocs.io/en/master/01_tutorials/05_logger.htmlสร้างสภาพแวดล้อม:
# You can also try SubprocVectorEnv, which will use parallelization
train_envs = ts . env . DummyVectorEnv ([ lambda : gym . make ( task ) for _ in range ( train_num )])
test_envs = ts . env . DummyVectorEnv ([ lambda : gym . make ( task ) for _ in range ( test_num )])สร้างเครือข่ายเช่นเดียวกับเครื่องมือเพิ่มประสิทธิภาพ:
from tianshou . utils . net . common import Net
# Note: You can easily define other networks.
# See https://tianshou.readthedocs.io/en/master/01_tutorials/00_dqn.html#build-the-network
env = gym . make ( task , render_mode = "human" )
state_shape = env . observation_space . shape or env . observation_space . n
action_shape = env . action_space . shape or env . action_space . n
net = Net ( state_shape = state_shape , action_shape = action_shape , hidden_sizes = [ 128 , 128 , 128 ])
optim = torch . optim . Adam ( net . parameters (), lr = lr )ตั้งค่านโยบายและนักสะสม:
policy = ts . policy . DQNPolicy (
model = net ,
optim = optim ,
discount_factor = gamma ,
action_space = env . action_space ,
estimation_step = n_step ,
target_update_freq = target_freq
)
train_collector = ts . data . Collector ( policy , train_envs , ts . data . VectorReplayBuffer ( buffer_size , train_num ), exploration_noise = True )
test_collector = ts . data . Collector ( policy , test_envs , exploration_noise = True ) # because DQN uses epsilon-greedy methodมาฝึกกันเถอะ:
result = ts . trainer . OffpolicyTrainer (
policy = policy ,
train_collector = train_collector ,
test_collector = test_collector ,
max_epoch = epoch ,
step_per_epoch = step_per_epoch ,
step_per_collect = step_per_collect ,
episode_per_test = test_num ,
batch_size = batch_size ,
update_per_step = 1 / step_per_collect ,
train_fn = lambda epoch , env_step : policy . set_eps ( eps_train ),
test_fn = lambda epoch , env_step : policy . set_eps ( eps_test ),
stop_fn = lambda mean_rewards : mean_rewards >= env . spec . reward_threshold ,
logger = logger ,
). run ()
print ( f"Finished training in { result . timing . total_time } seconds" ) บันทึก/โหลดนโยบายที่ผ่านการฝึกอบรม (มันเหมือนกับการโหลด torch.nn.module ):
torch . save ( policy . state_dict (), 'dqn.pth' )
policy . load_state_dict ( torch . load ( 'dqn.pth' ))ดูตัวแทนที่มี 35 fps:
policy . eval ()
policy . set_eps ( eps_test )
collector = ts . data . Collector ( policy , env , exploration_noise = True )
collector . collect ( n_episode = 1 , render = 1 / 35 )ตรวจสอบข้อมูลที่บันทึกไว้ใน Tensorboard:
$ tensorboard --logdir log/dqnโปรดอ่านเอกสารสำหรับการใช้งานขั้นสูง
Tianshou ยังอยู่ระหว่างการพัฒนา มีการเพิ่มอัลกอริทึมและคุณสมบัติเพิ่มเติมอย่างต่อเนื่องและเรายินดีต้อนรับการมีส่วนร่วมเพื่อช่วยให้ tianshou ดีขึ้น หากคุณต้องการมีส่วนร่วมโปรดตรวจสอบลิงค์นี้
หากคุณพบว่า tianshou มีประโยชน์โปรดอ้างอิงในสิ่งพิมพ์ของคุณ
@article{tianshou,
author = {Jiayi Weng and Huayu Chen and Dong Yan and Kaichao You and Alexis Duburcq and Minghao Zhang and Yi Su and Hang Su and Jun Zhu},
title = {Tianshou: A Highly Modularized Deep Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2022},
volume = {23},
number = {267},
pages = {1--6},
url = {http://jmlr.org/papers/v23/21-1127.html}
}Tianshou ได้รับการสนับสนุนจาก Appliedai Institute for Europe ซึ่งมุ่งมั่นที่จะให้การสนับสนุนและพัฒนาระยะยาว
ก่อนหน้านี้ Tianshou เคยเป็นแพลตฟอร์มการเรียนรู้เสริมแรงตาม TensorFlow คุณสามารถตรวจสอบรายละเอียดเพิ่มเติมของ Branch priv ขอบคุณมากสำหรับงานบุกเบิกของ Haosheng Zou สำหรับ Tianshou ก่อนเวอร์ชัน 0.1.1
เราขอขอบคุณ Tsail และสถาบันปัญญาประดิษฐ์มหาวิทยาลัย Tsinghua ที่จัดหาแพลตฟอร์มการวิจัย AI ที่ยอดเยี่ยม
mujoco-py เป็นแพ็คเกจดั้งเดิมและไม่แนะนำสำหรับโครงการใหม่ มันรวมอยู่ในความเข้ากันได้กับโครงการเก่าเท่านั้น โปรดทราบว่าอาจมีปัญหาความเข้ากันได้กับ MacOS ใหม่กว่า Monterey


