tianshou
v1.1.0

TiAnshou (天授) es una biblioteca de aprendizaje de refuerzo (RL) basada en Pytorch puro y gimnasio. Las principales características de TiAnshou de un vistazo son:
A diferencia de otras bibliotecas de aprendizaje de refuerzo, que pueden tener bases de código complejas, API hostiles de alto nivel, o no están optimizadas para la velocidad, TiAnshou proporciona un marco modularizado de alto rendimiento e interfaces fáciles de usar para construir agentes de aprendizaje de refuerzo profundo. Un aspecto más que distingue a TiAnshou es su generalidad: admite RL en línea y fuera de línea, RL de múltiples agentes y algoritmos basados en modelos.
Tianshou tiene como objetivo habilitar implementaciones concisas, tanto para investigadores como para profesionales, sin sacrificar la flexibilidad.
Los algoritmos compatibles incluyen:
Otras características notables:
En chino, Tianshou significa divinamente ordenado, derivado del don de nacer. TiAnshou es una plataforma de aprendizaje de refuerzo, y la naturaleza de RL no es aprender de los humanos. Entonces, tomar "Tianshou" significa que no hay un maestro para aprender, sino que aprender por sí mismo a través de una interacción constante con el medio ambiente.
"天授" 意指上天所授 , 引申为与生具有的天赋。天授是强化学习平台 而强化学习算法并不是向人类学习的 , 所以取 所以取 “天授” 意思是没有老师来教 而是自己通过跟环境不断交互来进行学习。 而是自己通过跟环境不断交互来进行学习。
TiAnshou está actualmente presentado en Pypi y Conda-Forge. Requiere Python> = 3.11.
Para instalar la versión más reciente de TiAnshou, la mejor manera es clonar el repositorio e instalarlo con poesía (que debe instalar primero en su sistema)
git clone [email protected]:thu-ml/tianshou.git
cd tianshou
poetry install También puede instalar los requisitos de desarrollo agregando --with dev o los extras para decir Mujoco y aceleración por envpool agregando --extras "mujoco envpool"
Si desea instalar múltiples extras, asegúrese de incluirlos en un solo comando. Llamadas secuenciales a poetry install --extras xxx sobrescribirá las instalaciones anteriores, dejando solo los últimos extras especificados instalados. O puede instalar todos los siguientes extras agregando --all-extras .
Los extras disponibles son:
atari (para entornos Atari)box2d (para entornos Box2d)classic_control (para entornos de control clásico (discreto))mujoco (para entornos de Mujoco)mujoco-py (para los entornos heredados de Mujoco-py 1 )pybullet (para entornos de pybullet)robotics (para entornos de gimnasio-robótica)vizdoom (para entornos de Vizdoom)envpool (para la integración de envpool)argparse (para poder ejecutar los ejemplos de API de alto nivel)De lo contrario, puede instalar la última versión de Pypi (actualmente muy lejos del maestro) con el siguiente comando:
$ pip install tianshouSi está utilizando Anaconda o Miniconda, puede instalar TiAnshou de Conda-Forge:
$ conda install tianshou -c conda-forgeAlternativamente, a la instalación de poesía, también puede instalar la última versión de origen a través de GitHub:
$ pip install git+https://github.com/thu-ml/tianshou.git@master --upgradeFinalmente, puede verificar la instalación a través de su consola Python de la siguiente manera:
import tianshou
print ( tianshou . __version__ )Si no se informan errores, ha instalado con éxito TiAnshou.
Los tutoriales y la documentación de la API están alojados en tianshou.readthedocs.io.
Encuentre scripts de ejemplo en la prueba/ y ejemplos/ carpetas.
| Plataforma RL | Documentación | Cobertura de código | Tipo de sugerencias | Última actualización |
|---|---|---|---|---|
| Basquinas estables3 | ✔️ | |||
| Ray/rllib | ➖ (1) | ✔️ | ||
| Spinningup | ||||
| Dopamina | ||||
| CUMBRE | ➖ (1) | ✔️ | ||
| Muestra de fábrica | ➖ | |||
| Tianshou | ✔️ |
(1): Tiene integración continua, pero la tasa de cobertura no está disponible
Tianshou se prueba rigurosamente. A diferencia de otras plataformas RL, nuestras pruebas incluyen el procedimiento de capacitación de agente completo para todos los algoritmos implementados . Nuestras pruebas fallarían una vez si alguno de los agentes no lograra un nivel consistente de rendimiento en épocas limitadas. Nuestras pruebas aseguran así la reproducibilidad. Consulte la página de acciones de GitHub para obtener más detalles.
Los resultados de referencia de Atari y Mujoco se pueden encontrar en los ejemplos/ atari/ y ejemplos/ manjoco/ carpetas respectivamente. Nuestros resultados de Mujoco alcanzan o exceden el nivel de rendimiento de la mayoría de los puntos de referencia existentes.
Todos los algoritmos implementan la siguiente API altamente general:
__init__ : inicializar la política;forward : Calcule las acciones basadas en observaciones dadas;process_buffer : Buffer inicial de proceso, que es útil para algunos algoritmos de aprendizaje fuera de líneaprocess_fn : preprocesos de datos del búfer de reproducción (ya que hemos reformulado todos los algoritmos para reproducir algoritmos basados en búfer);learn : Aprenda de un lote de datos dado;post_process_fn : actualice el búfer de reproducción del proceso de aprendizaje (por ejemplo, el búfer de reproducción priorizado debe actualizar el peso);update : La interfaz principal para la capacitación, IE, process_fn -> learn -> post_process_fn .La implementación de esta API es suficiente para que un nuevo algoritmo sea aplicable dentro de TiAnshou, lo que hace que la experimentación con nuevos enfoques sea particularmente sencillo.
TiAnshou proporciona dos niveles de API:
A continuación, consideremos una aplicación de ejemplo utilizando el entorno Cartpole Gymnasium. Aplicaremos el algoritmo de aprendizaje de la red Q profunda (DQN) utilizando ambas API.
Para comenzar, necesitamos algunas importaciones.
from tianshou . highlevel . config import SamplingConfig
from tianshou . highlevel . env import (
EnvFactoryRegistered ,
VectorEnvType ,
)
from tianshou . highlevel . experiment import DQNExperimentBuilder , ExperimentConfig
from tianshou . highlevel . params . policy_params import DQNParams
from tianshou . highlevel . trainer import (
EpochTestCallbackDQNSetEps ,
EpochTrainCallbackDQNSetEps ,
EpochStopCallbackRewardThreshold
) En la API de alto nivel, la base para un experimento RL es un ExperimentBuilder con el que podemos construir el experimento que luego buscamos ejecutar. Como queremos usar DQN, utilizamos la especialización DQNExperimentBuilder . Las otras importaciones sirven para proporcionar opciones de configuración para nuestro experimento.
La API de alto nivel proporciona una semántica en gran medida declarativa, es decir, el código está casi exclusivamente preocupado por la configuración que controla qué hacer (en lugar de cómo hacerlo).
experiment = (
DQNExperimentBuilder (
EnvFactoryRegistered ( task = "CartPole-v1" , train_seed = 0 , test_seed = 0 , venv_type = VectorEnvType . DUMMY ),
ExperimentConfig (
persistence_enabled = False ,
watch = True ,
watch_render = 1 / 35 ,
watch_num_episodes = 100 ,
),
SamplingConfig (
num_epochs = 10 ,
step_per_epoch = 10000 ,
batch_size = 64 ,
num_train_envs = 10 ,
num_test_envs = 100 ,
buffer_size = 20000 ,
step_per_collect = 10 ,
update_per_step = 1 / 10 ,
),
)
. with_dqn_params (
DQNParams (
lr = 1e-3 ,
discount_factor = 0.9 ,
estimation_step = 3 ,
target_update_freq = 320 ,
),
)
. with_model_factory_default ( hidden_sizes = ( 64 , 64 ))
. with_epoch_train_callback ( EpochTrainCallbackDQNSetEps ( 0.3 ))
. with_epoch_test_callback ( EpochTestCallbackDQNSetEps ( 0.0 ))
. with_epoch_stop_callback ( EpochStopCallbackRewardThreshold ( 195 ))
. build ()
)
experiment . run ()El generador de experimentos toma tres argumentos:
watch=True ) para varios episodios ( watch_num_episodes=100 ). Hemos deshabilitado la persistencia, porque no queremos guardar registros de capacitación, el agente o su configuración para uso futuro.num_epochs=10 )step_per_epoch=10000 ). Cada época consiste en una serie de pasos de recopilación de datos (despliegue) y pasos de entrenamiento. El parámetro step_per_collect controla la cantidad de datos que se recopilan en cada paso de recolección y después de cada paso de recolección, realizamos un paso de entrenamiento, aplicando una actualización basada en gradiente basada en una muestra de datos ( batch_size=64 ) tomado del búfer de datos que se ha recopilado. Para obtener más detalles, consulte la documentación de SamplingConfig .Luego procedemos a configurar algunos de los parámetros del algoritmo DQN mismo y del modelo de red neuronal que queremos usar. Un detalle específico de DQN es el uso de devoluciones de llamada para configurar el parámetro Epsilon del algoritmo para la exploración. Queremos usar una exploración aleatoria durante los despliegos (devolución de llamada de tren), pero no lo hacemos al evaluar el rendimiento del agente en los entornos de prueba (devolución de llamada de prueba).
Encuentre el script en ejemplos/discret/discret_dqn_hl.py. Aquí hay una carrera (con el tiempo de entrenamiento cortado):
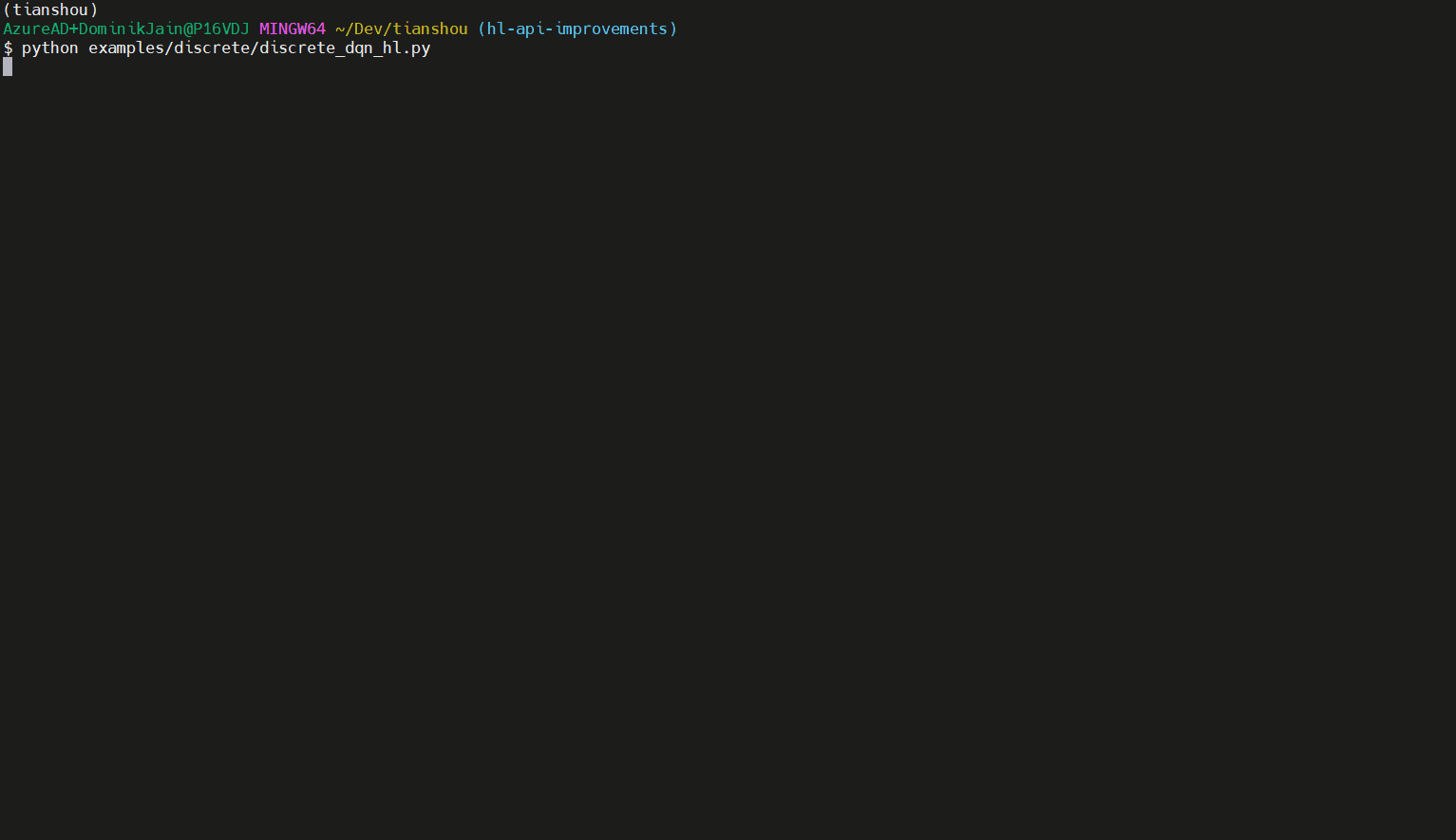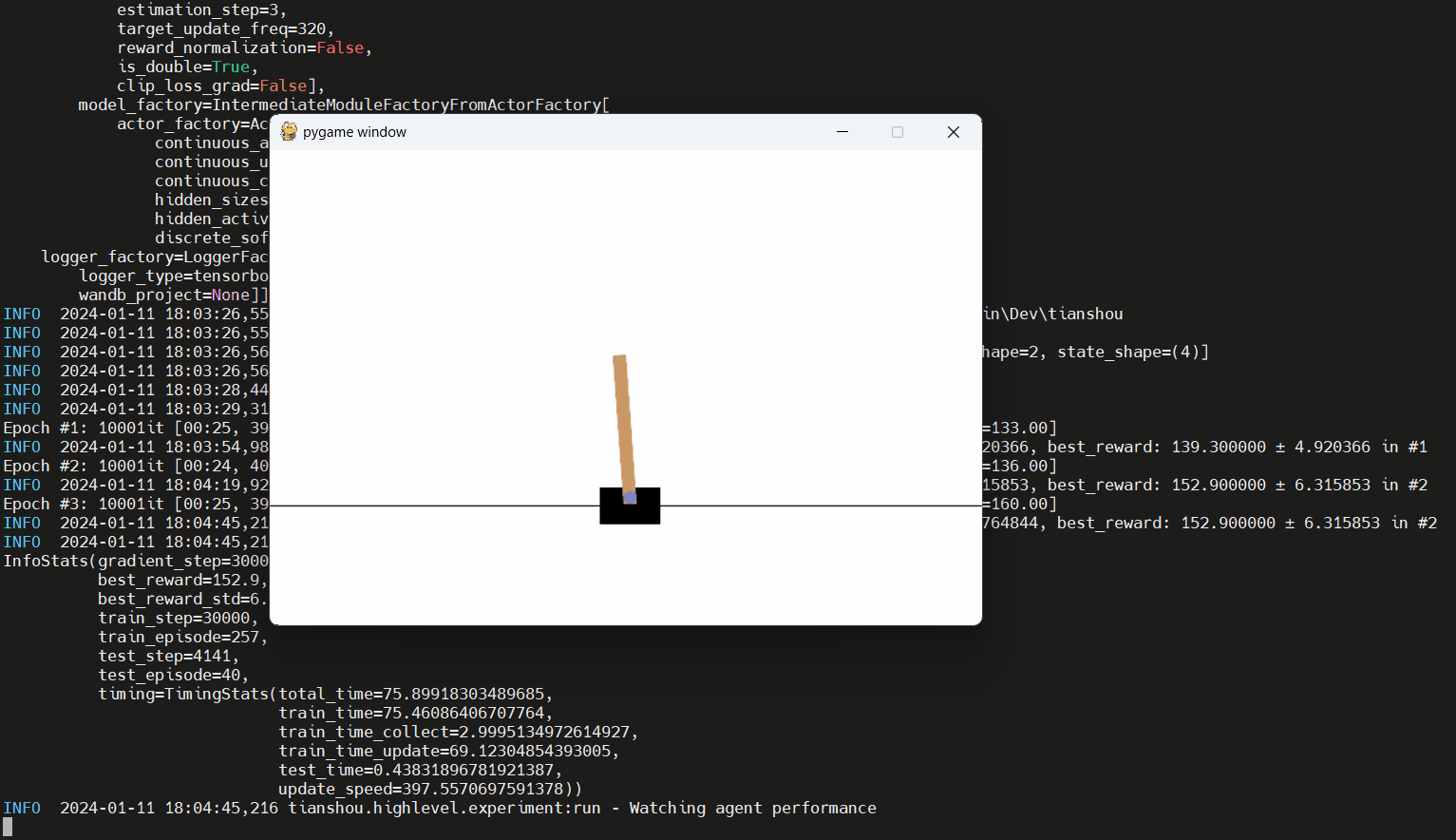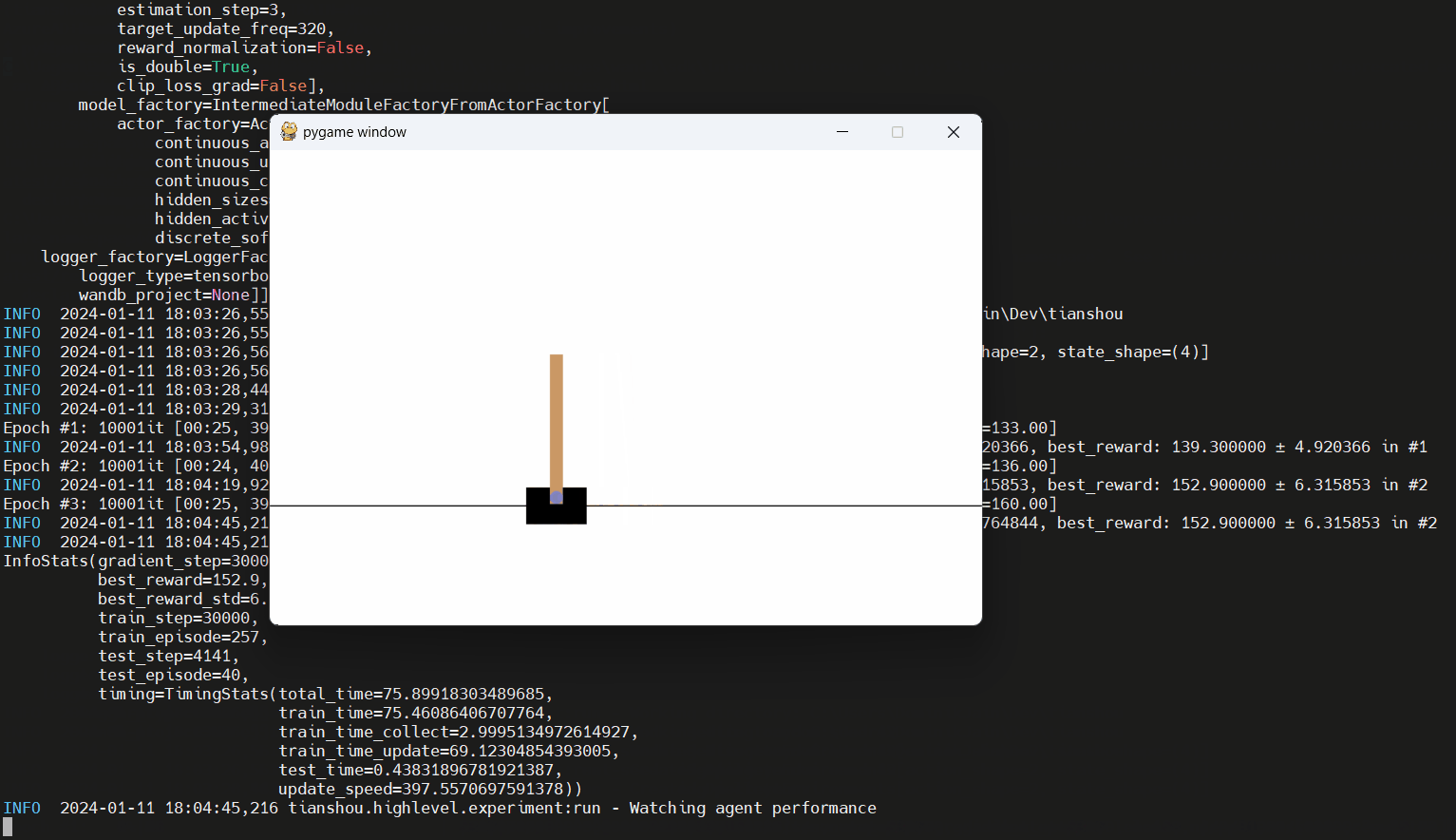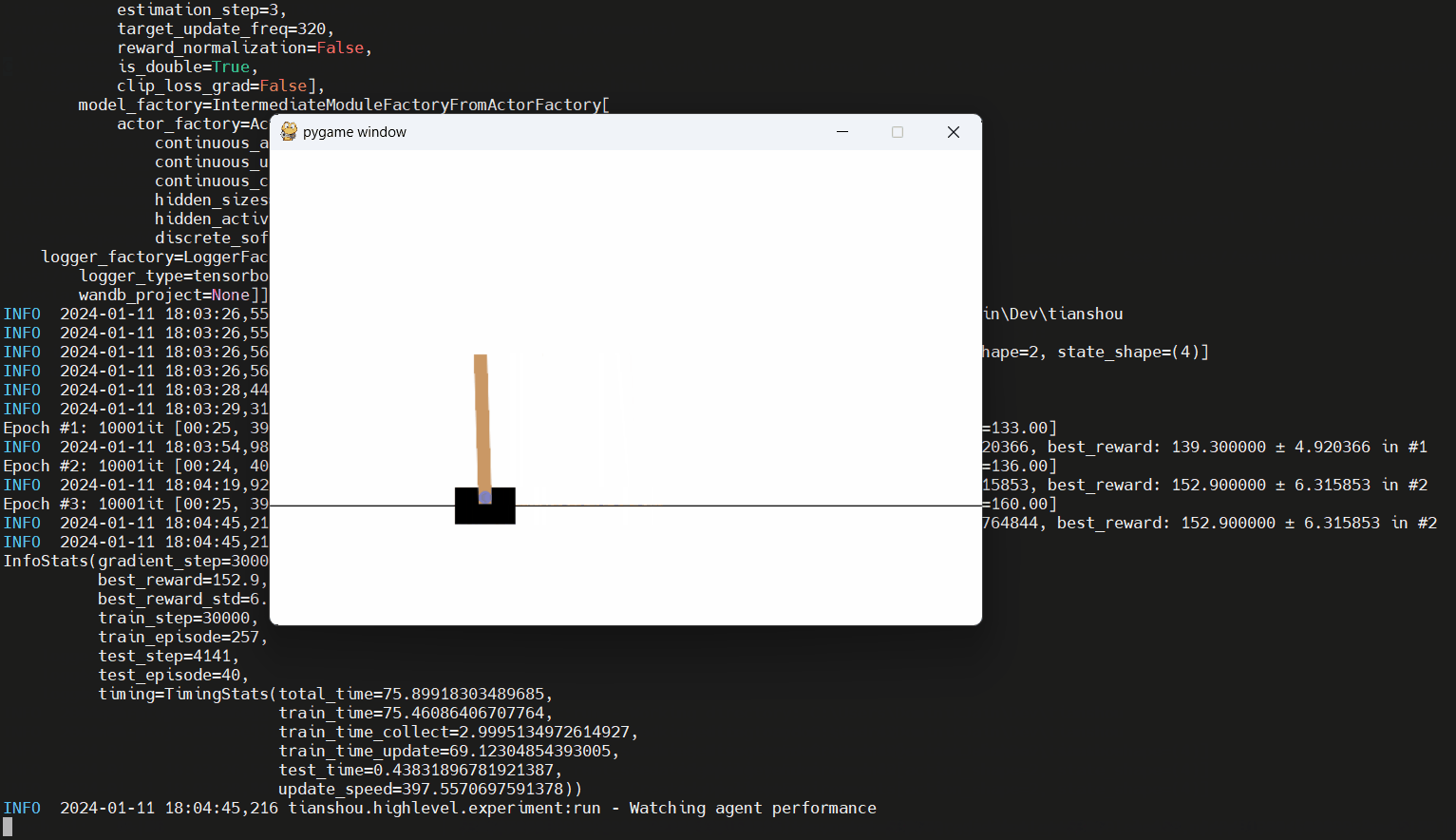
Encuentre muchas aplicaciones adicionales de la API de alto nivel en los examples/ carpeta; Busque scripts que terminen con _hl.py . Tenga en cuenta que la mayoría de estos ejemplos requieren el paquete adicional argparse (instálelo agregando --extras argparse al invocar poesía).
Consideremos ahora un ejemplo análogo en la API de procedimiento. Encuentre el script completo en ejemplos/discret/discret_dqn.py.
Primero, importe algunos paquetes relevantes:
import gymnasium as gym
import torch
from torch . utils . tensorboard import SummaryWriter
import tianshou as tsDefina algunos hiper-parametros:
task = 'CartPole-v1'
lr , epoch , batch_size = 1e-3 , 10 , 64
train_num , test_num = 10 , 100
gamma , n_step , target_freq = 0.9 , 3 , 320
buffer_size = 20000
eps_train , eps_test = 0.1 , 0.05
step_per_epoch , step_per_collect = 10000 , 10Inicializar el registrador:
logger = ts . utils . TensorboardLogger ( SummaryWriter ( 'log/dqn' ))
# For other loggers, see https://tianshou.readthedocs.io/en/master/01_tutorials/05_logger.htmlHacer entornos:
# You can also try SubprocVectorEnv, which will use parallelization
train_envs = ts . env . DummyVectorEnv ([ lambda : gym . make ( task ) for _ in range ( train_num )])
test_envs = ts . env . DummyVectorEnv ([ lambda : gym . make ( task ) for _ in range ( test_num )])Cree la red y su optimizador:
from tianshou . utils . net . common import Net
# Note: You can easily define other networks.
# See https://tianshou.readthedocs.io/en/master/01_tutorials/00_dqn.html#build-the-network
env = gym . make ( task , render_mode = "human" )
state_shape = env . observation_space . shape or env . observation_space . n
action_shape = env . action_space . shape or env . action_space . n
net = Net ( state_shape = state_shape , action_shape = action_shape , hidden_sizes = [ 128 , 128 , 128 ])
optim = torch . optim . Adam ( net . parameters (), lr = lr )Configure la política y los coleccionistas:
policy = ts . policy . DQNPolicy (
model = net ,
optim = optim ,
discount_factor = gamma ,
action_space = env . action_space ,
estimation_step = n_step ,
target_update_freq = target_freq
)
train_collector = ts . data . Collector ( policy , train_envs , ts . data . VectorReplayBuffer ( buffer_size , train_num ), exploration_noise = True )
test_collector = ts . data . Collector ( policy , test_envs , exploration_noise = True ) # because DQN uses epsilon-greedy methodVamos a entrenarlo:
result = ts . trainer . OffpolicyTrainer (
policy = policy ,
train_collector = train_collector ,
test_collector = test_collector ,
max_epoch = epoch ,
step_per_epoch = step_per_epoch ,
step_per_collect = step_per_collect ,
episode_per_test = test_num ,
batch_size = batch_size ,
update_per_step = 1 / step_per_collect ,
train_fn = lambda epoch , env_step : policy . set_eps ( eps_train ),
test_fn = lambda epoch , env_step : policy . set_eps ( eps_test ),
stop_fn = lambda mean_rewards : mean_rewards >= env . spec . reward_threshold ,
logger = logger ,
). run ()
print ( f"Finished training in { result . timing . total_time } seconds" ) Guardar/cargar la política capacitada (es exactamente lo mismo que cargar una torch.nn.module ):
torch . save ( policy . state_dict (), 'dqn.pth' )
policy . load_state_dict ( torch . load ( 'dqn.pth' ))Mira al agente con 35 fps:
policy . eval ()
policy . set_eps ( eps_test )
collector = ts . data . Collector ( policy , env , exploration_noise = True )
collector . collect ( n_episode = 1 , render = 1 / 35 )Inspeccione los datos guardados en TensorBoard:
$ tensorboard --logdir log/dqnLea la documentación para el uso avanzado.
Tianshou todavía está en desarrollo. Se agregan continuamente algoritmos y características continuamente, y siempre damos la bienvenida a las contribuciones para ayudar a mejorar a Tianshou. Si desea contribuir, consulte este enlace.
Si encuentra útil a Tianshou, cíquelo en sus publicaciones.
@article{tianshou,
author = {Jiayi Weng and Huayu Chen and Dong Yan and Kaichao You and Alexis Duburcq and Minghao Zhang and Yi Su and Hang Su and Jun Zhu},
title = {Tianshou: A Highly Modularized Deep Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2022},
volume = {23},
number = {267},
pages = {1--6},
url = {http://jmlr.org/papers/v23/21-1127.html}
}TiAnshou cuenta con el apoyo del Instituto de Europa de Aplicadai, quien se compromete a proporcionar apoyo y desarrollo a largo plazo.
Tianshou fue anteriormente una plataforma de aprendizaje de refuerzo basada en TensorFlow. Puede consultar la rama priv para obtener más detalles. Muchas gracias al trabajo pionero de Haosheng Zou para Tianshou antes de la versión 0.1.1.
Nos gustaría agradecer a Tsail y al Instituto de Inteligencia Artificial, Universidad de Tsinghua por proporcionar una excelente plataforma de investigación de IA.
mujoco-py es un paquete heredado y no se recomienda para nuevos proyectos. Solo se incluye para la compatibilidad con proyectos más antiguos. También tenga en cuenta que puede haber problemas de compatibilidad con MacOS más nuevos que Monterey. ↩


