tianshou
v1.1.0

Tianshou (()는 순수한 Pytorch 및 Gymnasium을 기반으로 한 RL (Rensforcement Learning) 라이브러리입니다. Tianshou의 주요 기능은 다음과 같습니다.
복잡한 코드베이스, 비우호적 인 고급 API를 가지고 있거나 속도에 최적화되지 않은 다른 강화 학습 라이브러리와 달리 Tianshou는 심층 강화 학습 에이전트를 구축하기위한 고성능, 모듈화 된 프레임 워크 및 사용자 친화적 인 인터페이스를 제공합니다. Tianshou를 차별화하는 한 가지 측면은 일반성입니다. 온라인 및 오프라인 RL, Multi-Agent RL 및 모델 기반 알고리즘을 지원합니다.
Tianshou는 유연성을 희생하지 않고 연구원과 실무자 모두를위한 간결한 구현을 가능하게하는 것을 목표로합니다.
지원되는 알고리즘에는 다음이 포함됩니다.
기타 주목할만한 기능 :
중국어에서 Tianshou는 신성하게 성임 된 것을 의미하며 태어난 선물에 파생된다. Tianshou는 강화 학습 플랫폼이며 RL의 본질은 인간에게서 배우지 않습니다. 따라서 "Tianshou"를 복용한다는 것은 배울 교사가 아니라 환경과의 끊임없는 상호 작용을 통해 스스로 배우는 것을 의미합니다.
“,”意指上天所授 意指上天所授 意指上天所授, 引申为与生具有的天赋。天授是强化学习平台 引申为与生具有的天赋。天授是强化学习平台, 而强化学习算法并不是向人类学习的, 所以取“天授”意思是没有老师来教 意思是没有老师来教, 而是自己通过跟环境不断交互来进行学习。
Tianshou는 현재 PYPI 및 Conda-Forge에서 호스팅됩니다. Python> = 3.11이 필요합니다.
최신 버전의 Tianshou를 설치하려면 가장 좋은 방법은 저장소를 복제하여 시로 설치하는 것입니다 (먼저 시스템에 설치해야합니다).
git clone [email protected]:thu-ml/tianshou.git
cd tianshou
poetry install 또한 --with dev 또는 extras의 extras를 추가하여 Dev 요구 사항을 설치하고 --extras "mujoco envpool" 추가하여 Envpool의 Acceleration을 추가 할 수 있습니다.
여러 엑스트라를 설치하려면 단일 명령에 포함시켜야합니다. poetry install --extras xxx 이전 설치를 덮어 쓸 수있게하여 마지막으로 지정된 추가 엑스트라 만 설치합니다. 또는 --all-extras 추가하여 다음 엑스트라를 모두 설치할 수 있습니다.
사용 가능한 엑스트라는 다음과 같습니다.
atari (Atari 환경)box2d (Box2d 환경)classic_control (클래식 제어 (이산) 환경)mujoco (Mujoco 환경)mujoco-py (레거시 Mujoco-Py 환경 1 )pybullet (Pybullet 환경)robotics (체육관-로보틱스 환경)vizdoom (Vizdoom 환경)envpool (Envpool 통합 용)argparse (높은 레벨 API 예제를 실행하려면)그렇지 않으면 다음 명령으로 PYPI (현재 마스터 뒤)에서 최신 릴리스를 설치할 수 있습니다.
$ pip install tianshouAnaconda 또는 Miniconda를 사용하는 경우 Conda-Forge에서 Tianshou를 설치할 수 있습니다.
$ conda install tianshou -c conda-forge또는시 설치를 위해 GitHub을 통해 최신 소스 버전을 설치할 수도 있습니다.
$ pip install git+https://github.com/thu-ml/tianshou.git@master --upgrade마지막으로, 당신은 다음과 같이 파이썬 콘솔을 통해 설치를 확인할 수 있습니다.
import tianshou
print ( tianshou . __version__ )오류가보고되지 않으면 Tianshou를 성공적으로 설치했습니다.
튜토리얼 및 API 문서는 tianshou.readthedocs.io에서 호스팅됩니다.
테스트/ 및 예제/ 폴더에서 예제 스크립트를 찾으십시오.
| RL 플랫폼 | 선적 서류 비치 | 코드 적용 범위 | 힌트를 입력하십시오 | 마지막 업데이트 |
|---|---|---|---|---|
| 안정된 바스 라인 3 | ✔️ | |||
| 광선/rllib | ➖ (1) | ✔️ | ||
| 회전 | ||||
| 도파민 | ||||
| 절정 | ➖ (1) | ✔️ | ||
| 샘플 공장 | ➖ | |||
| Tianshou | ✔️ |
(1) : 지속적인 통합이 있지만 적용 범위를 사용할 수 없습니다.
Tianshou는 엄격하게 테스트되었습니다. 다른 RL 플랫폼과 달리, 우리의 테스트에는 구현 된 모든 알고리즘에 대한 전체 에이전트 교육 절차가 포함됩니다 . 제한된 에포크에서 일관된 수준의 성능을 달성하지 못하면 에이전트가 일정한 수준의 성능을 달성하지 못하면 우리의 테스트가 실패 할 것입니다. 따라서 우리의 테스트는 재현성을 보장합니다. 자세한 내용은 Github 액션 페이지를 확인하십시오.
Atari 및 Mujoco 벤치 마크 결과는 각각 예/ Atari/ 및 예/ Mujoco/ 폴더에서 찾을 수 있습니다. 우리의 Mujoco 결과는 대부분의 기존 벤치 마크의 성능 수준에 도달하거나 초과합니다.
모든 알고리즘은 다음과 같은 일반적인 API를 구현합니다.
__init__ : 정책 초기화;forward : 주어진 관찰을 기반으로 조치를 계산합니다.process_buffer : 일부 오프라인 학습 알고리즘에 유용한 프로세스 초기 버퍼process_fn : 재생 버퍼의 전처리 데이터 (버퍼 기반 알고리즘을 재생하기 위해 모든 알고리즘을 재구성했기 때문에);learn : 주어진 데이터 배치에서 배우십시오.post_process_fn : 학습 프로세스에서 재생 버퍼를 업데이트합니다 (예 : 우선 순위가 정해진 재생 버퍼가 무게를 업데이트해야 함);update : 교육을위한 기본 인터페이스, 즉, process_fn -> learn -> post_process_fn .이 API의 구현은 새로운 알고리즘이 Tianshou 내에 적용 할 수있게하기 때문에 특히 새로운 접근 방식으로 실험을합니다.
Tianshou는 두 가지 API 레벨을 제공합니다.
다음에서는 Cartpole Gymnasium 환경을 사용하여 예제 응용 프로그램을 고려해 봅시다. 두 API를 사용하여 DEP Q 네트워크 (DQN) 학습 알고리즘을 적용합니다.
시작하려면 수입이 필요합니다.
from tianshou . highlevel . config import SamplingConfig
from tianshou . highlevel . env import (
EnvFactoryRegistered ,
VectorEnvType ,
)
from tianshou . highlevel . experiment import DQNExperimentBuilder , ExperimentConfig
from tianshou . highlevel . params . policy_params import DQNParams
from tianshou . highlevel . trainer import (
EpochTestCallbackDQNSetEps ,
EpochTrainCallbackDQNSetEps ,
EpochStopCallbackRewardThreshold
) 높은 수준의 API에서, RL 실험의 기초는 ExperimentBuilder 이며, 우리는 실험을 구축 한 다음 실행하려는 실험을 할 수 있습니다. DQN을 사용하려면 전문화 DQNExperimentBuilder 사용합니다. 다른 가져 오기는 실험에 대한 구성 옵션을 제공하는 역할을합니다.
높은 수준의 API는 크게 선언적 인 의미론을 제공합니다. 즉, 코드는 거의해야 할 일을 제어하는 구성과 거의 독점적으로 관련되어 있습니다.
experiment = (
DQNExperimentBuilder (
EnvFactoryRegistered ( task = "CartPole-v1" , train_seed = 0 , test_seed = 0 , venv_type = VectorEnvType . DUMMY ),
ExperimentConfig (
persistence_enabled = False ,
watch = True ,
watch_render = 1 / 35 ,
watch_num_episodes = 100 ,
),
SamplingConfig (
num_epochs = 10 ,
step_per_epoch = 10000 ,
batch_size = 64 ,
num_train_envs = 10 ,
num_test_envs = 100 ,
buffer_size = 20000 ,
step_per_collect = 10 ,
update_per_step = 1 / 10 ,
),
)
. with_dqn_params (
DQNParams (
lr = 1e-3 ,
discount_factor = 0.9 ,
estimation_step = 3 ,
target_update_freq = 320 ,
),
)
. with_model_factory_default ( hidden_sizes = ( 64 , 64 ))
. with_epoch_train_callback ( EpochTrainCallbackDQNSetEps ( 0.3 ))
. with_epoch_test_callback ( EpochTestCallbackDQNSetEps ( 0.0 ))
. with_epoch_stop_callback ( EpochStopCallbackRewardThreshold ( 195 ))
. build ()
)
experiment . run ()실험 빌더는 세 가지 인수를합니다.
watch_num_episodes=100 )에 대해 훈련 된 후 ( watch=True )에 대리인의 동작을 관찰하려고합니다. 우리는 훈련 로그, 에이전트 또는 향후 사용을 위해 구성을 저장하고 싶지 않기 때문에 지속성을 비활성화했습니다.num_epochs=10 )step_per_epoch=10000 )로 구성되어야한다. 모든 시대는 일련의 데이터 수집 (롤아웃) 단계 및 교육 단계로 구성됩니다. 매개 변수 step_per_collect 각 컬렉션 단계에서 수집 된 데이터의 양을 제어하고 각 컬렉션 단계 후에는 수집 된 데이터 버퍼에서 가져온 데이터 샘플 ( batch_size=64 )을 기반으로 그라디언트 기반 업데이트를 적용하여 교육 단계를 수행합니다. 자세한 내용은 SamplingConfig 의 문서를 참조하십시오.그런 다음 DQN 알고리즘 자체의 일부 매개 변수와 사용하려는 신경망 모델의 일부 매개 변수를 구성합니다. DQN- 특이 적 세부 사항은 탐색을 위해 알고리즘의 Epsilon 매개 변수를 구성하기 위해 콜백을 사용하는 것입니다. 우리는 롤아웃 중 (Train Callback) 동안 임의의 탐사를 사용하고 싶지만 테스트 환경에서 에이전트의 성능을 평가할 때 (테스트 콜백).
예제/distrete/distrete_dqn_hl.py에서 스크립트를 찾으십시오. 다음은 달리기입니다 (훈련 시간이 짧은 상태로) :
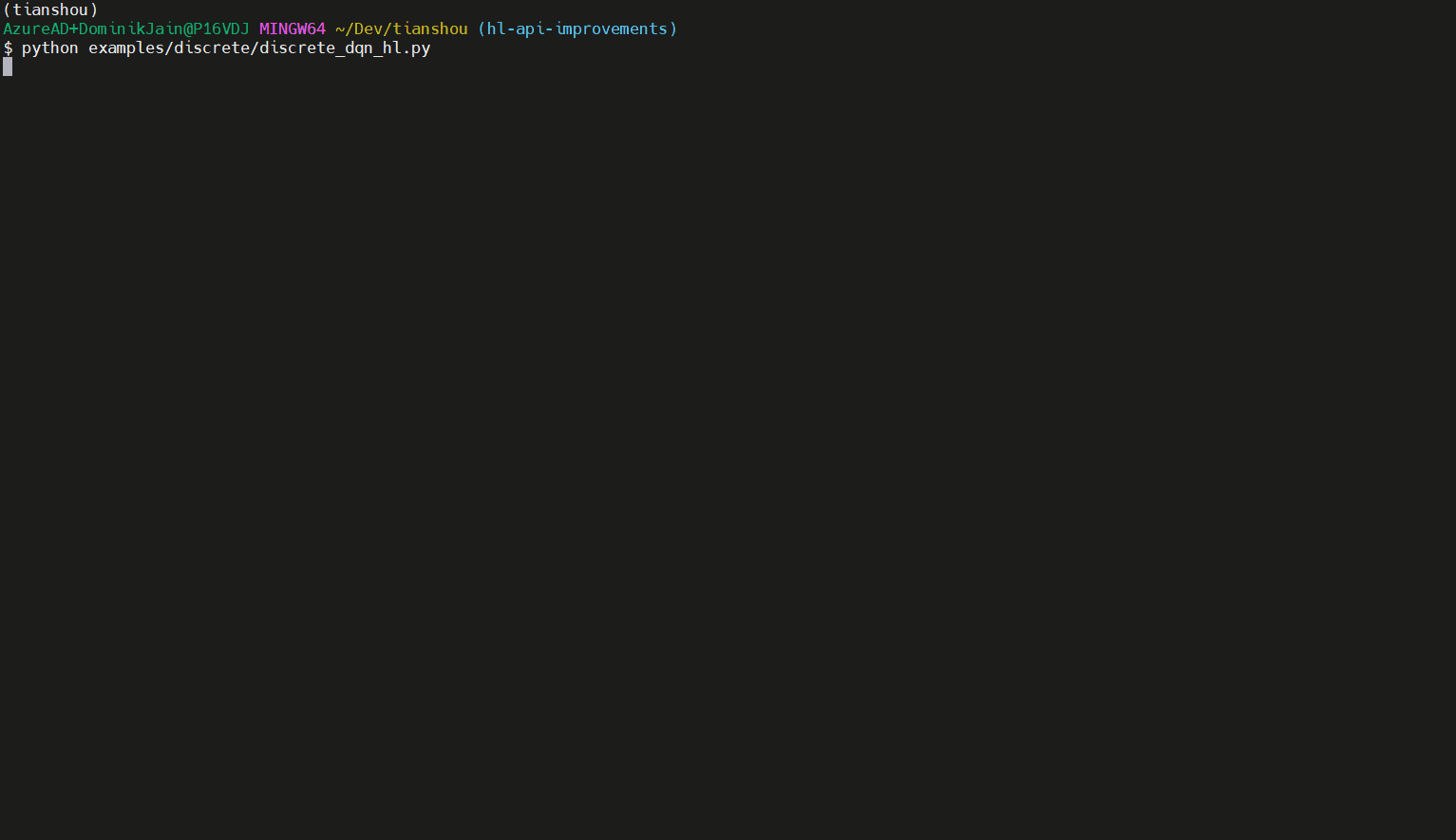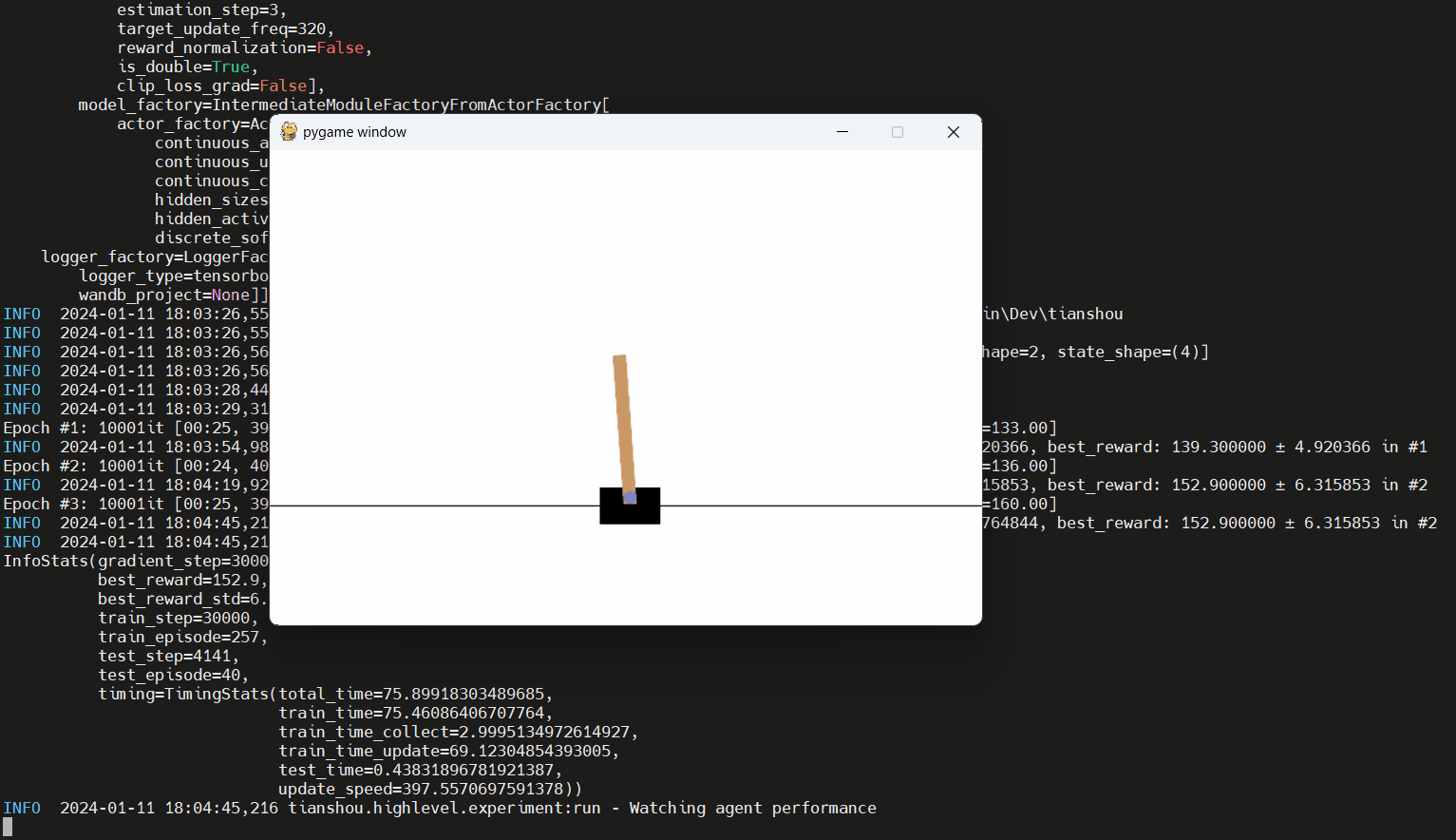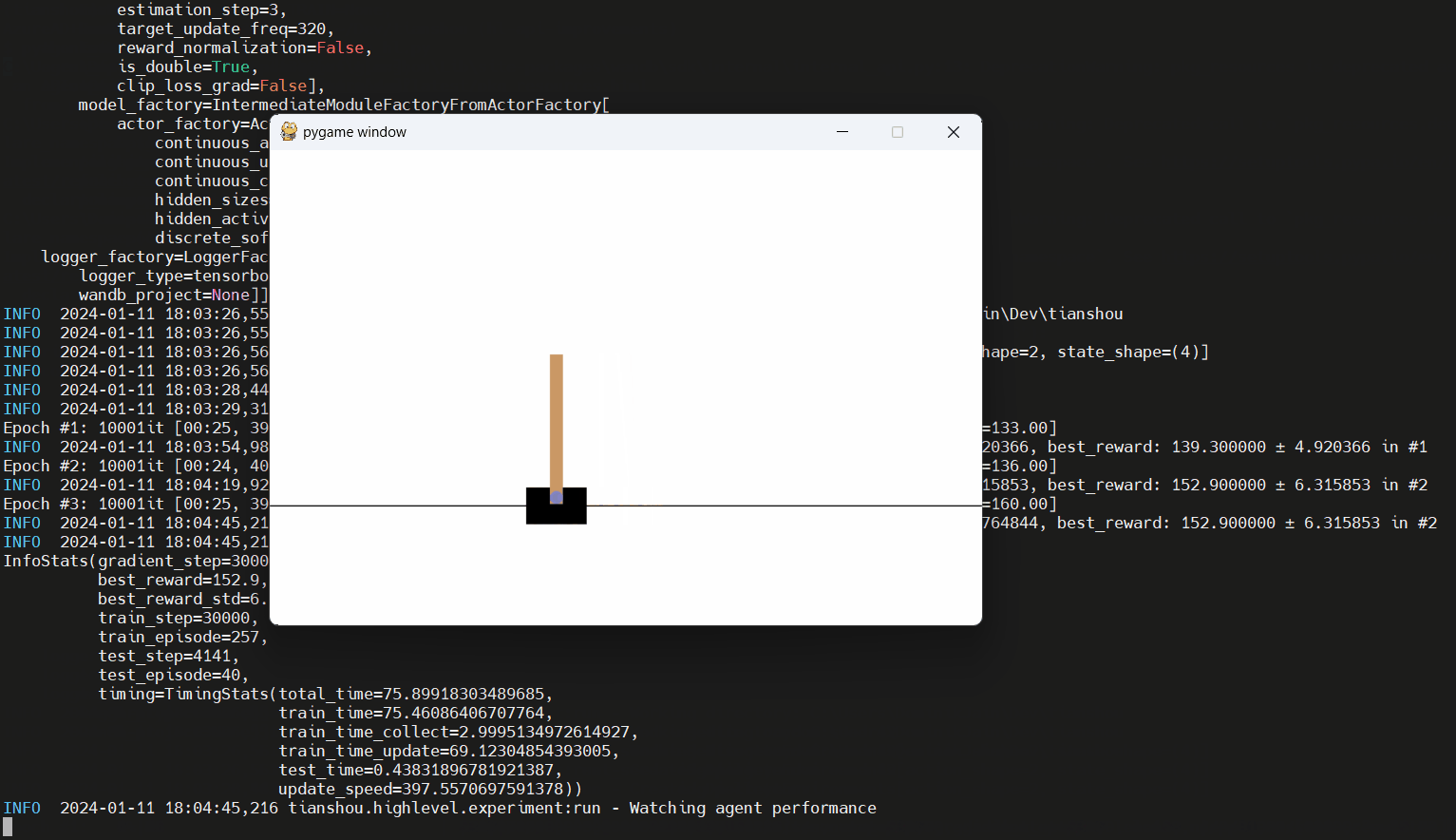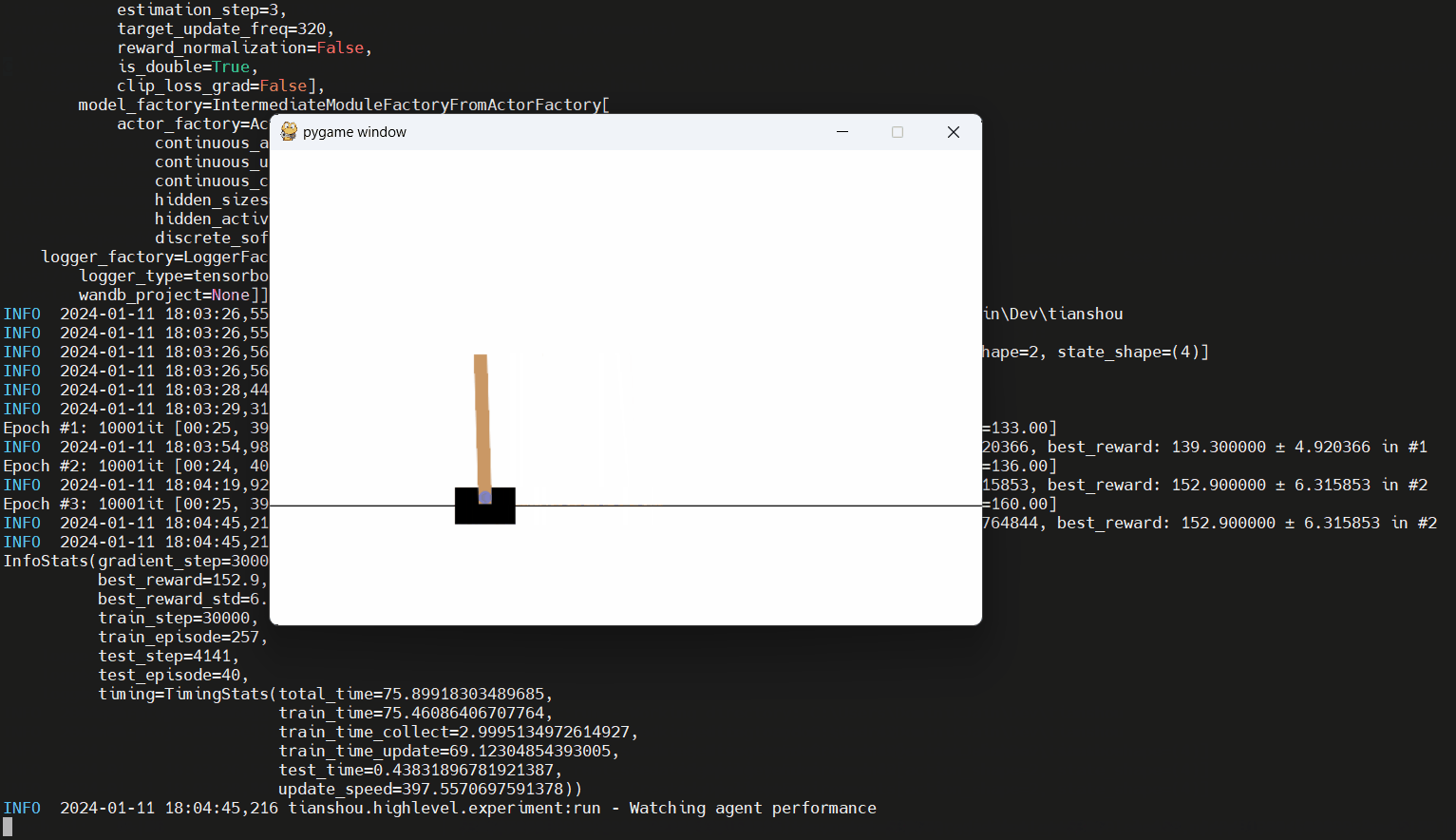
examples/ 폴더에서 고급 API의 많은 추가 응용 프로그램을 찾으십시오. _hl.py 로 끝나는 스크립트를 찾으십시오. 이 예제의 대부분은 추가 패키지 argparse 필요합니다 (시를 호출 할 때 --extras argparse 추가하여 설치).
이제 절차 적 API에서 유사한 예를 고려해 봅시다. 예제/distrete/distrete_dqn.py에서 전체 스크립트를 찾으십시오.
먼저 관련 패키지를 가져옵니다.
import gymnasium as gym
import torch
from torch . utils . tensorboard import SummaryWriter
import tianshou as ts일부 과변 변수를 정의하십시오.
task = 'CartPole-v1'
lr , epoch , batch_size = 1e-3 , 10 , 64
train_num , test_num = 10 , 100
gamma , n_step , target_freq = 0.9 , 3 , 320
buffer_size = 20000
eps_train , eps_test = 0.1 , 0.05
step_per_epoch , step_per_collect = 10000 , 10로거 초기화 :
logger = ts . utils . TensorboardLogger ( SummaryWriter ( 'log/dqn' ))
# For other loggers, see https://tianshou.readthedocs.io/en/master/01_tutorials/05_logger.html환경 만들기 :
# You can also try SubprocVectorEnv, which will use parallelization
train_envs = ts . env . DummyVectorEnv ([ lambda : gym . make ( task ) for _ in range ( train_num )])
test_envs = ts . env . DummyVectorEnv ([ lambda : gym . make ( task ) for _ in range ( test_num )])네트워크와 최적화기를 만듭니다.
from tianshou . utils . net . common import Net
# Note: You can easily define other networks.
# See https://tianshou.readthedocs.io/en/master/01_tutorials/00_dqn.html#build-the-network
env = gym . make ( task , render_mode = "human" )
state_shape = env . observation_space . shape or env . observation_space . n
action_shape = env . action_space . shape or env . action_space . n
net = Net ( state_shape = state_shape , action_shape = action_shape , hidden_sizes = [ 128 , 128 , 128 ])
optim = torch . optim . Adam ( net . parameters (), lr = lr )정책 및 수집가를 설정하십시오.
policy = ts . policy . DQNPolicy (
model = net ,
optim = optim ,
discount_factor = gamma ,
action_space = env . action_space ,
estimation_step = n_step ,
target_update_freq = target_freq
)
train_collector = ts . data . Collector ( policy , train_envs , ts . data . VectorReplayBuffer ( buffer_size , train_num ), exploration_noise = True )
test_collector = ts . data . Collector ( policy , test_envs , exploration_noise = True ) # because DQN uses epsilon-greedy method훈련합시다 :
result = ts . trainer . OffpolicyTrainer (
policy = policy ,
train_collector = train_collector ,
test_collector = test_collector ,
max_epoch = epoch ,
step_per_epoch = step_per_epoch ,
step_per_collect = step_per_collect ,
episode_per_test = test_num ,
batch_size = batch_size ,
update_per_step = 1 / step_per_collect ,
train_fn = lambda epoch , env_step : policy . set_eps ( eps_train ),
test_fn = lambda epoch , env_step : policy . set_eps ( eps_test ),
stop_fn = lambda mean_rewards : mean_rewards >= env . spec . reward_threshold ,
logger = logger ,
). run ()
print ( f"Finished training in { result . timing . total_time } seconds" ) 훈련 된 정책을 저장/로드합니다 ( torch.nn.module 로드하는 것과 정확히 동일) :
torch . save ( policy . state_dict (), 'dqn.pth' )
policy . load_state_dict ( torch . load ( 'dqn.pth' ))35fps의 에이전트를 시청하십시오.
policy . eval ()
policy . set_eps ( eps_test )
collector = ts . data . Collector ( policy , env , exploration_noise = True )
collector . collect ( n_episode = 1 , render = 1 / 35 )Tensorboard에 저장된 데이터를 검사하십시오.
$ tensorboard --logdir log/dqn고급 사용법은 문서를 읽으십시오.
Tianshou는 여전히 개발 중입니다. 추가 알고리즘과 기능이 지속적으로 추가되고 있으며, 우리는 항상 Tianshou를 개선하는 데 도움이되는 기여를 환영합니다. 기여하려면이 링크를 확인하십시오.
tianshou가 유용하다고 생각되면 출판물에서 인용하십시오.
@article{tianshou,
author = {Jiayi Weng and Huayu Chen and Dong Yan and Kaichao You and Alexis Duburcq and Minghao Zhang and Yi Su and Hang Su and Jun Zhu},
title = {Tianshou: A Highly Modularized Deep Reinforcement Learning Library},
journal = {Journal of Machine Learning Research},
year = {2022},
volume = {23},
number = {267},
pages = {1--6},
url = {http://jmlr.org/papers/v23/21-1127.html}
}Tianshou는 장기적인 지원 및 개발을 제공하기 위해 노력하는 Appliedai Institute for Europe의 지원을받습니다.
Tianshou는 이전에 Tensorflow를 기반으로 한 강화 학습 플랫폼이었습니다. 자세한 내용은 Branch priv 확인할 수 있습니다. 버전 0.1.1 이전의 Tianshou에 대한 Haosheng Zou의 선구적인 작업에 감사드립니다.
우리는 훌륭한 AI 연구 플랫폼을 제공해 주신 Tsinghua University의 Tsail과 Institute for Artificial Intelligence에게 감사의 말씀을 전합니다.
mujoco-py 는 레거시 패키지이며 새로운 프로젝트에는 권장되지 않습니다. 이전 프로젝트와의 호환성 만 포함됩니다. 또한 MACOS보다 MACOS보다 호환성 문제가있을 수 있습니다. ↩


