ml_things
v0.0.1:
การเรียนรู้ของเครื่องจักร เป็นไลบรารี Python ที่มีน้ำหนักเบาที่มีฟังก์ชั่นและตัวอย่างรหัสที่ฉันใช้ในการวิจัยประจำวันของฉันด้วยการเรียนรู้ของเครื่องการเรียนรู้ลึก NLP
ฉันสร้าง repo นี้เพราะฉันเบื่อที่จะค้นหารหัสเดียวกันจากโครงการเก่าและฉันต้องการได้รับประสบการณ์ในการสร้างห้องสมุด Python ด้วยการทำให้ทุกคนสามารถใช้รหัสได้ง่ายที่ฉันใช้บ่อยและสามารถช่วยผู้อื่นในงานการเรียนรู้ของเครื่องได้ หากคุณพบข้อบกพร่องใด ๆ หรือบางสิ่งบางอย่างไม่สมเหตุสมผลโปรดเปิดปัญหา
นั่นไม่ใช่ทั้งหมด! ไลบรารีนี้ยังมีตัวอย่างโค้ด Python และสมุดบันทึกที่เร่งเวิร์กโฟลว์การเรียนรู้ของเครื่องของฉัน
บันทึก:
Feb 5, 2022 ขอขอบคุณอีกครั้งสำหรับการสนับสนุนและความเมตตาของคุณ! แพ็คเกจนี้มีอยู่ใน PYPI แล้ว! pip install ml-thingsJuly 16, 2021 ขอบคุณทุกท่านสำหรับการสนับสนุนและความเมตตา! ตามที่ฉันสัญญาฉันจะย้าย repo นี้ไปยังโมดูลติดตั้ง PIPml_things :
ตัวอย่าง : รายการ CURATED ของตัวอย่าง Python ที่ฉันใช้บ่อย
ความคิดเห็น : ตัวอย่างเกี่ยวกับวิธีที่ฉันชอบแสดงความคิดเห็นรหัสของฉัน มันยังคงเป็นงานที่กำลังดำเนินอยู่
บทเรียนสมุดบันทึก : โครงการเรียนรู้ของเครื่องที่ฉันแปลงเป็นแบบฝึกหัดและโพสต์ออนไลน์
หมายเหตุสุดท้าย : รู้สึกขอบคุณ
repo นี้ได้รับการทดสอบด้วย Python 3.6+
การติดตั้ง ml_things ในสภาพแวดล้อมเสมือนจริงเป็นเรื่องดีเสมอ หากคุณแนะนำเกี่ยวกับการใช้สภาพแวดล้อมเสมือนจริงของ Python คุณสามารถตรวจสอบคู่มือผู้ใช้ได้ที่นี่
คุณสามารถติดตั้ง ml_things ด้วย pip จาก gitHub:
pip install git+https://github.com/gmihaila/ml_thingsหรือจาก PYPI:
pip install ml-thingsฟังก์ชั่นทั้งหมดที่ใช้ในโมดูล ML_THINGS
ฟังก์ชั่นที่เกี่ยวข้องกับการจัดการอาร์เรย์ที่มีประโยชน์เมื่อทำงานกับการเรียนรู้ของเครื่อง
PAD ความยาวตัวแปรอาร์เรย์ไปยังอาร์เรย์ numpy คงที่ มันสามารถจัดการอาร์เรย์เดี่ยว [1,2,3] หรืออาร์เรย์ซ้อนกัน [[1,2], [3]]
โดยค่าเริ่มต้นมันจะ padd zeros ถึงความยาวสูงสุดของแถวที่ตรวจพบ:
> >> from ml_things import pad_array
> >> pad_array ( variable_length_array = [[ 1 , 2 ],[ 3 ],[ 4 , 5 , 6 ]])
array ([[ 1. , 2. , 0. ],
[ 3. , 0. , 0. ],
[ 4. , 5. , 6. ]])นอกจากนี้ยังสามารถเพิ่มขนาดที่กำหนดเองและด้วยค่า CUSOTM:
> >> pad_array ( variable_length_array = [[ 1 , 2 ],[ 3 ],[ 4 , 5 , 6 ]], fixed_length = 5 , pad_value = 99 )
array ([[ 1. , 2. , 99. , 99. , 99. ],
[ 3. , 99. , 99. , 99. , 99. ],
[ 4. , 5. , 6. , 99. , 99. ]])แบ่งรายการออกเป็นแบทช์/ชิ้น ขนาดแบทช์ล่าสุดยังคงอยู่ในค่ารายการ หมายเหตุ: นี่เรียกอีกอย่างว่า chunking ฉันเรียกมันว่าแบทช์ตั้งแต่ฉันใช้มันมากขึ้นใน ML
ชุดสุดท้ายจะเป็นค่า reamining:
> >> from ml_things import batch_array
> >> batch_array ( list_values = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 8 , 9 , 8 , 6 , 5 , 4 , 6 ], batch_size = 4 )
[[ 1 , 2 , 3 , 4 ], [ 5 , 6 , 7 , 8 ], [ 8 , 9 , 8 , 6 ], [ 5 , 4 , 6 ]]ฟังก์ชั่นที่เกี่ยวข้องกับพล็อตที่มีประโยชน์เมื่อทำงานกับการเรียนรู้ของเครื่อง
สร้างพล็อตจากค่าอาร์เรย์เดียว
อาร์กิวเมนต์ทั้งหมดได้รับการปรับให้เหมาะสมสำหรับแปลงด่วน เปลี่ยนอาร์กิวเมนต์ magnify ให้แตกต่างกันขนาดของพล็อต:
> >> from ml_things import plot_array
> >> plot_array ([ 1 , 3 , 5 , 3 , 7 , 5 , 8 , 10 ], path = 'plot_array.png' , magnify = 0.1 , use_title = 'A Random Plot' , start_step = 0.3 , step_size = 0.1 , points_values = True , use_ylabel = 'Thid' , use_xlabel = 'This' )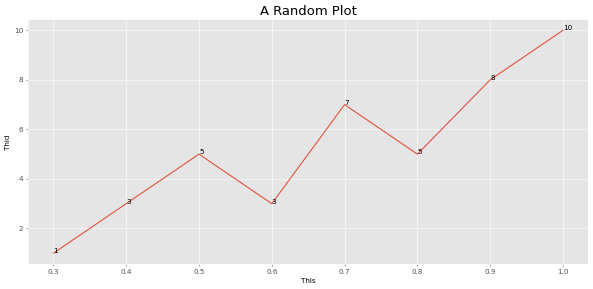
สร้างพล็อตจากค่าอาร์เรย์เดียว
อาร์กิวเมนต์ทั้งหมดได้รับการปรับให้เหมาะสมสำหรับแปลงด่วน เปลี่ยนอาร์กิวเมนต์ magnify ให้แตกต่างกันขนาดของพล็อต:
> >> from ml_things import plot_dict
> >> plot_dict ({ 'train_acc' :[ 1 , 3 , 5 , 3 , 7 , 5 , 8 , 10 ],
'valid_acc' :[ 4 , 8 , 9 ]}, use_linestyles = [ '-' , '--' ], magnify = 0.1 ,
start_step = 0.3 , step_size = 0.1 , path = 'plot_dict.png' , points_values = [ True , False ], use_title = 'Title' )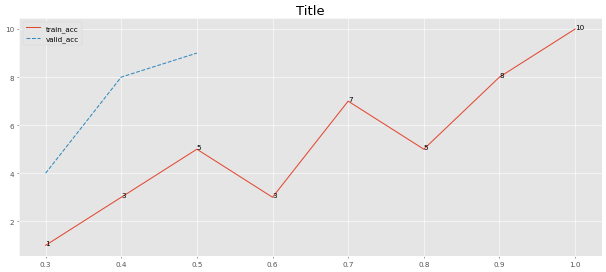
ฟังก์ชั่นนี้พิมพ์และแปลงเมทริกซ์ความสับสน การทำให้เป็นมาตรฐานสามารถนำไปใช้โดยการตั้ง normalize=True
อาร์กิวเมนต์ทั้งหมดได้รับการปรับให้เหมาะสมสำหรับแปลงด่วน เปลี่ยนอาร์กิวเมนต์ magnify ให้แตกต่างกันขนาดของพล็อต:
> >> from ml_things import plot_confusion_matrix
> >> plot_confusion_matrix ( y_true = [ 1 , 0 , 1 , 1 , 0 , 1 ], y_pred = [ 0 , 1 , 1 , 1 , 0 , 1 ], magnify = 0.1 , use_title = 'My Confusion Matrix' , path = 'plot_confusion_matrix.png' );
Confusion matrix , without normalization
array ([[ 1 , 1 ],
[ 1 , 3 ]])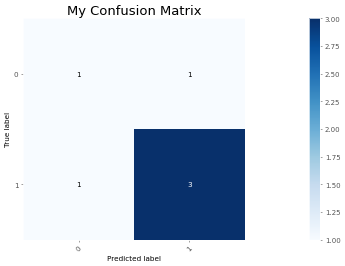
ฟังก์ชั่นที่เกี่ยวข้องกับข้อความที่มีประโยชน์เมื่อทำงานกับการเรียนรู้ของเครื่อง
ทำความสะอาดข้อความโดยใช้เทคนิคต่าง ๆ :
> >> from ml_things import clean_text
> >> clean_text ( "ThIs is $$$%. t t n \ so dirtyyy$$ text :'(. omg!!!" , full_clean = True )
'this is so dirtyyy text omg'ฟังก์ชั่นที่เกี่ยวข้องกับเว็บที่มีประโยชน์เมื่อทำงานกับการเรียนรู้ของเครื่อง
ดาวน์โหลดไฟล์จาก URL มันจะส่งคืนเส้นทางของไฟล์ที่ดาวน์โหลด:
> >> from ml_things import download_from
> >> download_from ( url = 'https://raw.githubusercontent.com/gmihaila/ml_things/master/setup.py' , path = '.' )
'./setup.py'นี่คือตัวอย่างงูหลามที่มีขนาดใหญ่มากโดยไม่มีธีมที่แน่นอน ฉันใส่ไว้ในสิ่งที่ใช้บ่อยที่สุดในขณะที่รักษาลำดับตรรกะ ฉันชอบที่จะให้พวกเขาง่ายและมีประสิทธิภาพมากที่สุด
| ชื่อ | คำอธิบาย |
|---|---|
| อ่านไฟล์ | หนึ่งซับในการอ่านไฟล์ใด ๆ |
| เขียนไฟล์ | หนึ่งซับในการเขียนสตริงลงในไฟล์ |
| การดีบัก | เริ่มการดีบักหลังจากบรรทัดนี้ |
| PIP ติดตั้ง gitHub | ติดตั้งไลบรารีโดยตรงจาก GitHub โดยใช้ pip |
| อาร์กิวเมนต์แยกวิเคราะห์ | การแยกวิเคราะห์ข้อโต้แย้งเมื่อเรียกใช้ไฟล์ .py |
| แพทย์ | วิธีเรียกใช้ Unittesc อย่างง่ายโดยใช้ฟังก์ชั่น DocumentaIn มีประโยชน์เมื่อต้องการทำสมุดบันทึกภายใน |
| แก้ไขข้อความ | เนื่องจากข้อมูลข้อความยุ่งอยู่เสมอฉันจึงใช้มันเสมอ มันยอดเยี่ยมในการแก้ไข Unicode ที่ไม่ดี |
| วันที่ปัจจุบัน | วิธีรับวันที่ปัจจุบันใน Python ฉันใช้สิ่งนี้เมื่อจำเป็นต้องตั้งชื่อไฟล์บันทึก |
| เวลาปัจจุบัน | รับเวลาปัจจุบันใน Python |
| ลบเครื่องหมายวรรคตอน | วิธีที่เร็วที่สุดในการลบเครื่องหมายวรรคตอนใน Python3 |
| Pytorch-Dataset | ตัวอย่างรหัสเกี่ยวกับวิธีการสร้างชุดข้อมูล Pytorch |
| อุปกรณ์การแข่งขัน Pytorch | วิธีการตั้งค่าอุปกรณ์ใน Pytorch เพื่อตรวจสอบว่ามี GPU หรือไม่ |
นี่คือตัวอย่างบางส่วนของวิธีที่ฉันชอบแสดงความคิดเห็นรหัสของฉัน ฉันเห็นวิธีการต่าง ๆ มากมายที่ผู้คนแสดงความคิดเห็นรหัสของพวกเขา สิ่งหนึ่งที่แน่นอนคือ ความคิดเห็นใด ๆ ดีกว่าไม่มีความคิดเห็น
ฉันพยายามติดตามให้มากที่สุดเท่าที่จะทำได้ Pep 8 - คู่มือสไตล์สำหรับรหัส Python
เมื่อฉันแสดงความคิดเห็นฟังก์ชั่นหรือคลาส:
# required import for variables type declaration
from typing import List , Optional , Tuple , Dict
def my_function ( function_argument : str , another_argument : Optional [ List [ int ]] = None ,
another_argument_ : bool = True ) -> Dict [ str , int ]
r"""Function/Class main comment.
More details with enough spacing to make it easy to follow.
Arguments:
function_argument (:obj:`str`):
A function argument description.
another_argument (:obj:`List[int]`, `optional`):
This argument is optional and it will have a None value attributed inside the function.
another_argument_ (:obj:`bool`, `optional`, defaults to :obj:`True`):
This argument is optional and it has a default value.
The variable name has `_` to avoid conflict with similar name.
Returns:
:obj:`Dict[str: int]`: The function returns a dicitonary with string keys and int values.
A class will not have a return of course.
"""
# make sure we keep out promise and return the variable type we described.
return { 'argument' : function_argument }นี่คือที่ที่ฉันเก็บสมุดบันทึกของโครงการก่อนหน้านี้ซึ่งฉันเปลี่ยนเป็นแบบฝึกหัดขนาดเล็ก หลายครั้งที่ฉันใช้เป็นพื้นฐานสำหรับการเริ่มต้นโครงการใหม่
สมุดบันทึกทั้งหมดอยู่ใน Google Colab ไม่เคยได้ยิน Google Colab? - คุณต้องตรวจสอบภาพรวมของ colaboratory บทนำสู่ Colab และ Python และสิ่งที่ฉันคิดว่าเป็นบทความสื่อที่ยอดเยี่ยมเกี่ยวกับเรื่องนี้เพื่อกำหนดค่า Google Colab เหมือนมืออาชีพ
หากคุณตรวจสอบ /ml_things/notebooks/ พวกเขาจำนวนมากยังไม่ได้อยู่ในรายการที่นี่เพราะพวกเขายังไม่ได้อยู่ในรูปแบบ 'ขัดเงา' นี่คือสมุดบันทึกที่ดีพอที่จะแบ่งปันกับทุกคน:
| ชื่อ | คำอธิบาย | ลิงค์ |
|---|---|---|
| - แบทช์ที่ดีกว่าด้วย pytorchtext bucketiterator | วิธีใช้ pytorchtext bucketiterator เพื่อเรียงลำดับข้อมูลข้อความเพื่อการแบตช์ที่ดีขึ้น | |
| - Pretrain Transformers โมเดลใน Pytorch โดยใช้ Transformers Hugging Face | Pretrain 67 Transformers รุ่นบนชุดข้อมูลที่กำหนดเองของคุณ | |
| - ปรับเปลี่ยนหม้อแปลงใน Pytorch โดยใช้ Transformers Hugging Face | ทำแบบฝึกหัดให้สมบูรณ์เกี่ยวกับวิธีการปรับแต่งโมเดลหม้อแปลง 73 สำหรับการจำแนกประเภทข้อความ-ไม่จำเป็นต้องเปลี่ยนรหัส! | |
| Bert Inner Workings ใน Pytorch โดยใช้ Transformers Hugging Face | ทำแบบฝึกหัดให้เสร็จเกี่ยวกับวิธีการไหลผ่าน Bert | |
| - GPT2 สำหรับการจำแนกข้อความโดยใช้ใบหน้ากอด? หม้อแปลงไฟฟ้า | ทำแบบฝึกหัดให้สมบูรณ์เกี่ยวกับวิธีใช้ GPT2 สำหรับการจำแนกข้อความ |
ขอบคุณสำหรับการตรวจสอบ repo ของฉัน ฉันเป็นคนชอบความสมบูรณ์แบบดังนั้นฉันจะทำการเปลี่ยนแปลงมากมายเมื่อพูดถึงรายละเอียดเล็ก ๆ น้อย ๆ
หากคุณเห็นสิ่งผิดปกติโปรดแจ้งให้เราทราบโดยเปิด ปัญหาเกี่ยวกับที่เก็บ ml_things gitHub ของฉัน !
บทเรียนจำนวนมากออกมาส่วนใหญ่มีสิ่งเดียวและไม่ได้รับการดูแล ฉันวางแผนที่จะรักษาบทเรียนให้ทันสมัยให้มากที่สุดเท่าที่จะทำได้
- GitHub: Gmihaila
เว็บไซต์: gmihaila.github.io
- LinkedIn: mihailageorge
- อีเมล: [email protected]


