ml_things
v0.0.1:
머신 러닝 사물은 기계 학습, 딥 러닝, NLP에서 일상적인 연구에서 사용하는 기능 및 코드 스 니펫을 포함하는 가벼운 파이썬 라이브러리입니다.
나는 오래된 프로젝트에서 항상 같은 코드를 찾는 데 지쳤고 파이썬 라이브러리 구축에 대한 경험을 얻고 싶었 기 때문에이 저장소를 만들었습니다. 이를 모든 사람이 이용할 수있게함으로써 코드에 쉽게 액세스 할 수 있으며 자주 사용하면 기계 학습 작업에서 다른 사람들을 도울 수 있습니다. 버그가 있거나 무언가가 이해되지 않으면 자유롭게 문제를 열어주십시오.
그게 전부는 아닙니다! 이 라이브러리에는 기계 학습 워크 플로우 속도를 높이는 파이썬 코드 스 니펫 및 노트북도 포함되어 있습니다.
메모:
Feb 5, 2022 귀하의 지원과 친절에 다시 한번 감사드립니다! 이 패키지는 지금 PYPI에서 사용할 수 있습니다! pip install ml-thingsJuly 16, 2021 귀하의 지원과 친절에 감사드립니다! 내가 약속 했듯이이 repo를 설치 모듈로 옮길 것입니다.ML_THINGS :
스 니펫 : 자주 사용하는 파이썬 스 니펫의 선별 된 목록.
의견 : 코드를 댓글을 달리는 방법에 대한 샘플. 여전히 진행중인 작업입니다.
Notebooks Tutorials : 튜토리얼로 변환하고 온라인으로 게시 한 머신 러닝 프로젝트.
최종 참고 : 감사합니다.
이 repo는 Python 3.6+로 테스트됩니다.
가상 환경에 ml_things 설치하는 것은 항상 우연한 연습입니다. Python의 가상 환경 사용에 대한 지침이 있으면 여기에서 사용자 안내서를 확인할 수 있습니다.
GitHub에서 PIP를 사용하여 ml_things 설치할 수 있습니다.
pip install git+https://github.com/gmihaila/ml_things또는 pypi에서 :
pip install ml-thingsML_THINGS 모듈에서 구현 된 모든 기능.
기계 학습을 수행 할 때 유용 할 수있는 배열 조작 관련 기능.
PAD 가변 길이 배열 고정 Numpy 어레이에 대한 배열. 단일 배열 [1,2,3] 또는 중첩 어레이 [[1,2], [3]를 처리 할 수 있습니다.
기본적으로 제로가 감지 된 최대 행 길이로 패드했습니다.
> >> from ml_things import pad_array
> >> pad_array ( variable_length_array = [[ 1 , 2 ],[ 3 ],[ 4 , 5 , 6 ]])
array ([[ 1. , 2. , 0. ],
[ 3. , 0. , 0. ],
[ 4. , 5. , 6. ]])또한 사용자 정의 크기와 Cusotm 값으로 패드 할 수 있습니다.
> >> pad_array ( variable_length_array = [[ 1 , 2 ],[ 3 ],[ 4 , 5 , 6 ]], fixed_length = 5 , pad_value = 99 )
array ([[ 1. , 2. , 99. , 99. , 99. ],
[ 3. , 99. , 99. , 99. , 99. ],
[ 4. , 5. , 6. , 99. , 99. ]])목록을 배치/청크로 나눕니다. 마지막 배치 크기는 목록 값으로 남아 있습니다. 참고 : 이것을 청킹이라고도합니다. ML에서 더 많이 사용하기 때문에 배치라고합니다.
마지막 배치는 리밍 값입니다.
> >> from ml_things import batch_array
> >> batch_array ( list_values = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 8 , 9 , 8 , 6 , 5 , 4 , 6 ], batch_size = 4 )
[[ 1 , 2 , 3 , 4 ], [ 5 , 6 , 7 , 8 ], [ 8 , 9 , 8 , 6 ], [ 5 , 4 , 6 ]]머신 러닝을 할 때 유용 할 수있는 플롯 관련 기능.
단일 값 배열에서 플롯을 만듭니다.
모든 인수는 빠른 플롯에 최적화됩니다. 플롯의 크기에 따라 magnify 인수를 변경하십시오.
> >> from ml_things import plot_array
> >> plot_array ([ 1 , 3 , 5 , 3 , 7 , 5 , 8 , 10 ], path = 'plot_array.png' , magnify = 0.1 , use_title = 'A Random Plot' , start_step = 0.3 , step_size = 0.1 , points_values = True , use_ylabel = 'Thid' , use_xlabel = 'This' )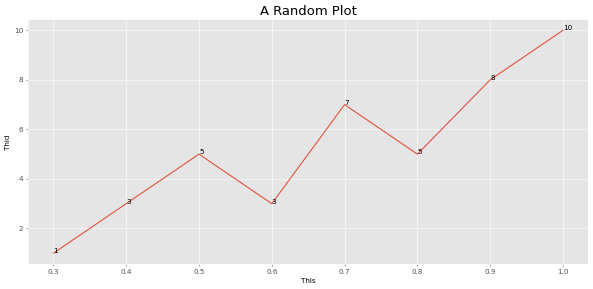
단일 값 배열에서 플롯을 만듭니다.
모든 인수는 빠른 플롯에 최적화됩니다. 플롯의 크기에 따라 magnify 인수를 변경하십시오.
> >> from ml_things import plot_dict
> >> plot_dict ({ 'train_acc' :[ 1 , 3 , 5 , 3 , 7 , 5 , 8 , 10 ],
'valid_acc' :[ 4 , 8 , 9 ]}, use_linestyles = [ '-' , '--' ], magnify = 0.1 ,
start_step = 0.3 , step_size = 0.1 , path = 'plot_dict.png' , points_values = [ True , False ], use_title = 'Title' )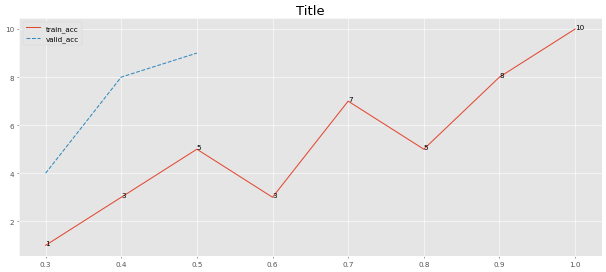
이 기능은 혼란 매트릭스를 인쇄하고 플롯합니다. normalize=True 설정하여 정규화를 적용 할 수 있습니다.
모든 인수는 빠른 플롯에 최적화됩니다. 플롯의 크기에 따라 magnify 인수를 변경하십시오.
> >> from ml_things import plot_confusion_matrix
> >> plot_confusion_matrix ( y_true = [ 1 , 0 , 1 , 1 , 0 , 1 ], y_pred = [ 0 , 1 , 1 , 1 , 0 , 1 ], magnify = 0.1 , use_title = 'My Confusion Matrix' , path = 'plot_confusion_matrix.png' );
Confusion matrix , without normalization
array ([[ 1 , 1 ],
[ 1 , 3 ]])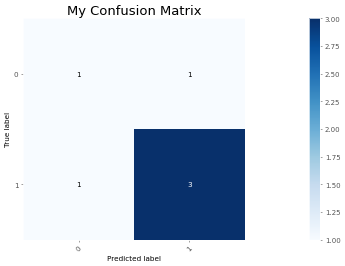
머신 러닝을 할 때 유용 할 수있는 텍스트 관련 기능.
다양한 기술을 사용하여 깨끗한 텍스트 :
> >> from ml_things import clean_text
> >> clean_text ( "ThIs is $$$%. t t n \ so dirtyyy$$ text :'(. omg!!!" , full_clean = True )
'this is so dirtyyy text omg'머신 러닝을 할 때 유용 할 수있는 웹 관련 기능.
URL에서 파일을 다운로드하십시오. 다운로드 된 파일의 경로를 반환합니다.
> >> from ml_things import download_from
> >> download_from ( url = 'https://raw.githubusercontent.com/gmihaila/ml_things/master/setup.py' , path = '.' )
'./setup.py'이것은 특정 테마가없는 매우 다양한 파이썬 스 니펫입니다. 논리적 순서를 유지하면서 가장 자주 사용되는 것들에 넣었습니다. 나는 그것들을 가능한 한 단순하고 효율적으로 갖고 싶어합니다.
| 이름 | 설명 |
|---|---|
| 파일 읽기 | 파일을 읽는 하나의 라이너. |
| 파일을 작성하십시오 | 문자열을 파일에 쓸 수있는 하나의 라이너. |
| 디버그 | 이 라인 후에 디버깅을 시작하십시오. |
| PIP 설치 Github | pip 사용하여 GitHub에서 직접 라이브러리를 설치하십시오. |
| 논쟁을 구문 분석합니다 | .py 파일을 실행할 때 주어진 인수를 구문 분석합니다. |
| DocTest | Function DocumentAiton을 사용하여 간단한 단위를 실행하는 방법. 노트북 내부에서 유닛 테스트를해야 할 때 유용합니다. |
| 텍스트 수정 | 텍스트 데이터는 항상 지저분하므로 항상 사용합니다. 나쁜 유니 코드를 고정시키는 데 좋습니다. |
| 현재 날짜 | 파이썬에서 현재 날짜를 얻는 방법. 로그 파일의 이름을 지정해야 할 때 이것을 사용합니다. |
| 현재 시간 | 파이썬에서 현재 시간을 얻으십시오. |
| 구두점을 제거하십시오 | Python3에서 구두점을 제거하는 가장 빠른 방법. |
| Pytorch-dataset | Pytorch 데이터 세트를 만드는 방법에 대한 코드 샘플. |
| Pytorch-Device | GPU를 사용할 수 있는지 감지하기 위해 Pytorch에서 장치를 설정하는 방법. |
이것들은 내가 코드에 댓글을 달고 싶어하는 몇 가지 스 니펫입니다. 사람들이 자신의 코드를 주석하는 방법에 대한 여러 가지 방법을 보았습니다. 한 가지 확실한 점은 다음과 같습니다. 어떤 의견은 댓글이없는 것보다 낫습니다 .
PETHON 코드의 스타일 가이드 인 PEP 8을 할 수있는 한 많이 따라야합니다.
함수 또는 클래스에 댓글을 달 때 :
# required import for variables type declaration
from typing import List , Optional , Tuple , Dict
def my_function ( function_argument : str , another_argument : Optional [ List [ int ]] = None ,
another_argument_ : bool = True ) -> Dict [ str , int ]
r"""Function/Class main comment.
More details with enough spacing to make it easy to follow.
Arguments:
function_argument (:obj:`str`):
A function argument description.
another_argument (:obj:`List[int]`, `optional`):
This argument is optional and it will have a None value attributed inside the function.
another_argument_ (:obj:`bool`, `optional`, defaults to :obj:`True`):
This argument is optional and it has a default value.
The variable name has `_` to avoid conflict with similar name.
Returns:
:obj:`Dict[str: int]`: The function returns a dicitonary with string keys and int values.
A class will not have a return of course.
"""
# make sure we keep out promise and return the variable type we described.
return { 'argument' : function_argument }이곳에서 나는 이전 프로젝트의 노트북을 보관하여 작은 자습서로 전환했습니다. 많은 시간에 나는 그것들을 새로운 프로젝트를 시작하기위한 기초로 사용합니다.
모든 노트북은 Google Colab 에 있습니다. Google Colab에 대해 들어 본 적이 없습니까? ? 공동 작업에 대한 개요, Colab 및 Python 소개 및 Google Colab을 Pro와 같은 구성하는 훌륭한 중간 기사라고 생각합니다.
/ml_things/notebooks/ 확인하면 아직 '연마 된'형태가 아니기 때문에 여기에 나열되지 않습니다. 이들은 모든 사람과 공유하기에 충분한 노트북입니다.
| 이름 | 설명 | 모래밭 |
|---|---|---|
| ? pytorchtext bucketiterator를 사용한 더 나은 배치 | PytorchText Bucketiterator를 사용하여 더 나은 배치를 위해 텍스트 데이터를 정렬하는 방법. | |
| ? 포옹 페이스 트랜스포머를 사용하여 Pytorch의 프리 트레인 변압기 모델 | 사용자 정의 데이터 세트의 프리 트레인 67 변압기 모델. | |
| ? 포옹 페이스 트랜스포머를 사용하여 Pytorch의 미세 조정 변압기 | 텍스트 분류를위한 73 변압기 모델을 미세 조정하는 방법에 대한 완전한 자습서-코드 변경이 필요하지 않습니다! | |
| 포옹 페이스 트랜스포머를 사용하여 Pytorch의 Bert 내부 작업 | 입력이 Bert를 통해 어떻게 흐르는 지에 대한 튜토리얼. | |
| ? 포옹 얼굴을 사용한 텍스트 분류를위한 GPT2? 변압기 | 텍스트 분류에 GPT2를 사용하는 방법에 대한 튜토리얼. |
내 repo를 확인해 주셔서 감사합니다. 나는 완벽 주의자이므로 작은 세부 사항에 관해서는 많은 변화를 할 것입니다.
당신이 뭔가 잘못 되었다면 내 ml_things github 리포지토리에서 문제를 열어 알려주십시오!
많은 튜토리얼이 주로 일회성이며 유지되지 않습니다. 튜토리얼을 최대한 최신 상태로 유지할 계획입니다.
? Github : Gmihaila
웹 사이트 : gmihaila.github.io
? LinkedIn : Mihailageorge
? 이메일 : [email protected]


