ml_things
v0.0.1:
Machine Learning Things ist eine leichte Python -Bibliothek, die Funktionen und Codeausschnitte enthält, die ich in meiner täglichen Forschung mit maschinellem Lernen, Deep Learning, NLP verwende.
Ich habe dieses Repo erstellt, weil ich es satt hatte, immer den gleichen Code aus älteren Projekten zu suchen, und ich wollte Erfahrung beim Aufbau einer Python -Bibliothek sammeln. Indem ich dies für alle zur Verfügung stellt, kann ich einen einfachen Zugriff auf Code haben, den ich häufig verwende, und kann anderen in ihrer maschinellen Lernen helfen. Wenn Sie Fehler finden oder etwas macht keinen Sinn, können Sie bitte ein Problem eröffnen.
Das ist nicht alles! Diese Bibliothek enthält auch Python -Code -Snippets und Notizbücher, die meinen Workflow für maschinelles Lernen beschleunigen.
Notiz:
Feb 5, 2022 Nochmals vielen Dank für Ihre Unterstützung und Freundlichkeit! Dieses Paket ist jetzt auf PYPI erhältlich! pip install ml-thingsJuly 16, 2021 Vielen Dank für Ihre Unterstützung und Freundlichkeit! Als ich versprach, werde ich dieses Repo in Pip -Installationsmodule bewegen.ML_Things :
Snippets : Kuratierte Liste von Python -Snippets, die ich häufig verwende.
Kommentare : Beispiel darüber, wie ich meinen Code kommentieren möchte. Es ist noch in Arbeit.
Notebooks Tutorials : Projekte für maschinelles Lernen, die ich in Tutorials umgewandelt und online veröffentlicht habe.
Letzter Anmerkung : dankbar sein.
Dieses Repo wird mit Python 3.6+ getestet.
Es ist immer eine gute Praxis, ml_things in einer virtuellen Umgebung zu installieren. Wenn Sie die virtuelle Umgebungen von Python verwenden, können Sie den Benutzerhandbuch hier überprüfen.
Sie können ml_things mit PIP von GitHub installieren:
pip install git+https://github.com/gmihaila/ml_thingsOder von pypi:
pip install ml-thingsAlle Funktionen im ML_THings -Modul implementiert.
Array -Manipulationsfunktion, die bei der Arbeit mit maschinellem Lernen nützlich sein kann.
PAD Variable Länge Array zu einem festen Numpy -Array. Es kann einzelne Arrays [1,2,3] oder verschachtelte Arrays [[1,2], [3]] verarbeiten.
Standardmäßig werden Nullen auf die maximale Länge der erkannten Zeile padd:
> >> from ml_things import pad_array
> >> pad_array ( variable_length_array = [[ 1 , 2 ],[ 3 ],[ 4 , 5 , 6 ]])
array ([[ 1. , 2. , 0. ],
[ 3. , 0. , 0. ],
[ 4. , 5. , 6. ]])Es kann auch zu einer benutzerdefinierten Größe und mit Cusotm -Werten padeln:
> >> pad_array ( variable_length_array = [[ 1 , 2 ],[ 3 ],[ 4 , 5 , 6 ]], fixed_length = 5 , pad_value = 99 )
array ([[ 1. , 2. , 99. , 99. , 99. ],
[ 3. , 99. , 99. , 99. , 99. ],
[ 4. , 5. , 6. , 99. , 99. ]])Teilen Sie eine Liste in Chargen/Stücke auf. Die letzte Stapelgröße verbleibt die Listenwerte. Hinweis: Dies wird auch als Chunking bezeichnet. Ich nenne es Stapel, da ich es in ML mehr benutze.
Die letzte Charge sind die Reiswerte:
> >> from ml_things import batch_array
> >> batch_array ( list_values = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 8 , 9 , 8 , 6 , 5 , 4 , 6 ], batch_size = 4 )
[[ 1 , 2 , 3 , 4 ], [ 5 , 6 , 7 , 8 ], [ 8 , 9 , 8 , 6 ], [ 5 , 4 , 6 ]]Plotbezogene Funktion, die bei der Arbeit mit maschinellem Lernen nützlich sein kann.
Erstellen Sie das Diagramm aus einem einzigen Wertearray.
Alle Argumente sind für schnelle Handlungen optimiert. Ändern Sie die magnify , um die Größe des Diagramms zu variieren:
> >> from ml_things import plot_array
> >> plot_array ([ 1 , 3 , 5 , 3 , 7 , 5 , 8 , 10 ], path = 'plot_array.png' , magnify = 0.1 , use_title = 'A Random Plot' , start_step = 0.3 , step_size = 0.1 , points_values = True , use_ylabel = 'Thid' , use_xlabel = 'This' )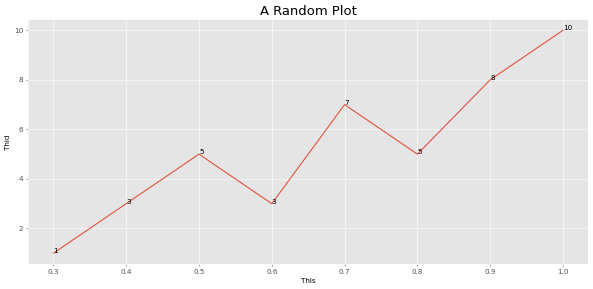
Erstellen Sie das Diagramm aus einem einzigen Wertearray.
Alle Argumente sind für schnelle Handlungen optimiert. Ändern Sie die magnify , um die Größe des Diagramms zu variieren:
> >> from ml_things import plot_dict
> >> plot_dict ({ 'train_acc' :[ 1 , 3 , 5 , 3 , 7 , 5 , 8 , 10 ],
'valid_acc' :[ 4 , 8 , 9 ]}, use_linestyles = [ '-' , '--' ], magnify = 0.1 ,
start_step = 0.3 , step_size = 0.1 , path = 'plot_dict.png' , points_values = [ True , False ], use_title = 'Title' )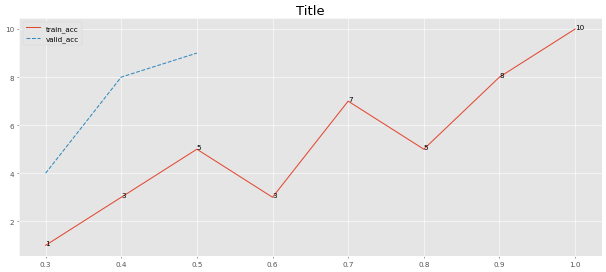
Diese Funktion druckt und plant die Verwirrungsmatrix. Die Normalisierung kann angewendet werden, indem normalize=True festgelegt wird.
Alle Argumente sind für schnelle Handlungen optimiert. Ändern Sie die magnify , um die Größe des Diagramms zu variieren:
> >> from ml_things import plot_confusion_matrix
> >> plot_confusion_matrix ( y_true = [ 1 , 0 , 1 , 1 , 0 , 1 ], y_pred = [ 0 , 1 , 1 , 1 , 0 , 1 ], magnify = 0.1 , use_title = 'My Confusion Matrix' , path = 'plot_confusion_matrix.png' );
Confusion matrix , without normalization
array ([[ 1 , 1 ],
[ 1 , 3 ]])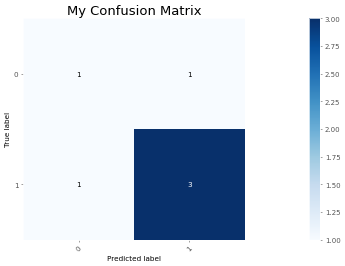
Textbezogene Funktion, die bei der Arbeit mit maschinellem Lernen nützlich sein kann.
Reinigen Sie den Text mit verschiedenen Techniken:
> >> from ml_things import clean_text
> >> clean_text ( "ThIs is $$$%. t t n \ so dirtyyy$$ text :'(. omg!!!" , full_clean = True )
'this is so dirtyyy text omg'Webbezogene Funktion, die bei der Arbeit mit maschinellem Lernen nützlich sein kann.
Datei von der URL herunterladen. Es gibt den Pfad der heruntergeladenen Datei zurück:
> >> from ml_things import download_from
> >> download_from ( url = 'https://raw.githubusercontent.com/gmihaila/ml_things/master/setup.py' , path = '.' )
'./setup.py'Dies ist eine sehr große Auswahl an Python -Snippets ohne ein bestimmtes Thema. Ich habe sie in die am häufigsten verwendeten gestellt, während ich eine logische Reihenfolge aufbewahre. Ich mag es, sie so einfach und effizient wie möglich zu haben.
| Name | Beschreibung |
|---|---|
| Datei lesen | Ein Liner zum Lesen einer Datei. |
| Datei schreiben | Ein Liner zum Schreiben einer Zeichenfolge in eine Datei. |
| Debuggen | Beginnen Sie nach dieser Linie debuggen. |
| PIP GitHub installieren | Installieren Sie die Bibliothek direkt mit pip aus GitHub. |
| Argument analysieren | Analysieren Sie Argumente beim Ausführen einer .py -Datei. |
| Doktor | So führen Sie ein einfaches Unittesc mit Funktionsdokumentaiton aus. Nützlich, wenn Sie in Notebook unittest machen müssen. |
| Text beheben | Da Textdaten immer unordentlich sind, benutze ich sie immer. Es ist großartig, einen schlechten Unicode zu beheben. |
| Aktuelles Datum | So erhalten Sie das aktuelle Datum in Python. Ich benutze dies, wenn ich Protokolldateien benenne. |
| Aktuelle Zeit | Holen Sie sich die aktuelle Zeit in Python. |
| Interpunktion entfernen | Der schnellste Weg, die Interpunktion in Python3 zu entfernen. |
| Pytorch-Datenet | Code Beispiel zum Erstellen eines Pytorch -Datensatzes. |
| Pytorch-Gerät | So richten Sie das Gerät in Pytorch ein, um festzustellen, ob GPU verfügbar ist. |
Dies sind ein paar Ausschnitte darüber, wie ich meinen Code gerne kommentieren möchte. Ich habe viele verschiedene Möglichkeiten gesehen, wie Menschen ihren Code kommentieren. Eines ist sicher: Ein Kommentar ist besser als kein Kommentar .
Ich versuche so viel wie möglich zu folgen.
Wenn ich eine Funktion oder Klasse kommentiere:
# required import for variables type declaration
from typing import List , Optional , Tuple , Dict
def my_function ( function_argument : str , another_argument : Optional [ List [ int ]] = None ,
another_argument_ : bool = True ) -> Dict [ str , int ]
r"""Function/Class main comment.
More details with enough spacing to make it easy to follow.
Arguments:
function_argument (:obj:`str`):
A function argument description.
another_argument (:obj:`List[int]`, `optional`):
This argument is optional and it will have a None value attributed inside the function.
another_argument_ (:obj:`bool`, `optional`, defaults to :obj:`True`):
This argument is optional and it has a default value.
The variable name has `_` to avoid conflict with similar name.
Returns:
:obj:`Dict[str: int]`: The function returns a dicitonary with string keys and int values.
A class will not have a return of course.
"""
# make sure we keep out promise and return the variable type we described.
return { 'argument' : function_argument }Hier behalte ich Notizbücher einiger früherer Projekte, die ich in kleine Tutorials gemacht habe. Oft benutze ich sie als Grundlage für die Start eines neuen Projekts.
Alle Notizbücher befinden sich in Google Colab . Noch nie von Google Colab gehört? ? Sie müssen sich den Überblick über Colaboratory, die Einführung in Colab und Python und einen großartigen mittelgroßen Artikel darüber ansehen, um Google Colab wie einen Profi zu konfigurieren.
Wenn Sie die /ml_things/notebooks/ viele von ihnen überprüfen, sind hier nicht aufgeführt, da sie noch nicht in einem „polierten“ Form sind. Dies sind die Notizbücher, die gut genug sind, um sie mit allen zu teilen:
| Name | Beschreibung | Links |
|---|---|---|
| ? Bessere Chargen mit Pytorchtext -Bucketiterator | So verwenden Sie PytorChtext Bucketiterator, um Textdaten für eine bessere Charge zu sortieren. | |
| ? Modelle in Pytorch mit umarmenden Gesichtstransformatoren in Pytorch | MODELLE auf den STRAIN 67 -Transformatoren in Ihrem benutzerdefinierten Datensatz. | |
| ? Fein-Tune-Transformatoren in Pytorch mit umarmenden Gesichtstransformatoren | Vollständige Tutorial zur Feinabstimmung von 73 Transformatormodellen für die Textklassifizierung-keine Codeänderungen erforderlich! | |
| Bert Innenarbeit in Pytorch mit umarmenden Gesichtstransformatoren | Vollständige Tutorial darüber, wie ein Eingang durch Bert fließt. | |
| ? GPT2 für die Textklassifizierung unter Verwendung von umarmtem Gesicht? Transformatoren | Vollständige Tutorial zur Verwendung von GPT2 für die Textklassifizierung. |
Danke, dass du mein Repo angesehen hast. Ich bin ein Perfektionist, also werde ich viele Änderungen vornehmen, wenn es um kleine Details geht.
Wenn Sie etwas falsch sehen, lassen Sie es mich bitte wissen, indem Sie ein Problem in meinem ML_Things Github -Repository öffnen!
Viele Tutorials sind meistens eine einmalige Sache und werden nicht aufrechterhalten. Ich habe vor, meine Tutorials so viel wie möglich auf dem neuesten Stand zu halten.
? Github: Gmihaila
Website: gmihaila.github.io
? LinkedIn: Mihailageorge
? E -Mail: [email protected]


