TensorFlow Summarization
1.0.0
สาขานี้ใช้ TF.Contrib.seq2Seq API ใหม่ใน TensorFlow R1.1 สำหรับผู้ใช้ R1.0 โปรดตรวจสอบสาขา tf1.0
นี่คือการใช้แบบจำลองลำดับต่อลำดับโดยใช้ตัวเข้ารหัส GRU แบบสองทิศทางและตัวถอดรหัส GRU โครงการนี้มีวัตถุประสงค์เพื่อช่วยให้ผู้คนเริ่มทำงานกับ การสรุปข้อความสั้น ๆ ที่เป็นนามธรรม ทันที และหวังว่ามันอาจใช้งานได้กับงานการแปลของเครื่อง
โปรดตรวจสอบ Harvardnlp/Send-Summary
การดาวน์โหลด
หากคุณต้องการฝึกอบรมแบบจำลองและมี Nvidia GPU (เช่น GTX 1080, GTX Titan, ฯลฯ ) โปรดตั้งค่าสภาพแวดล้อม CUDA และติดตั้ง TensorFlow-GPU
> pip3 install -U tensorflow-gpu==1.1
คุณสามารถตรวจสอบว่า GPU ทำงานได้หรือไม่
> python3
>>> import tensorflow
>>>
และตรวจสอบให้แน่ใจว่าไม่มีข้อผิดพลาด
หากคุณไม่มี GPU คุณยังสามารถใช้โมเดลที่ผ่านการฝึกอบรมและสร้างบทสรุปโดยใช้ CPU ของคุณ
> pip3 install -U tensorflow==1.1
ควรจัดระเบียบไฟล์เช่นนี้
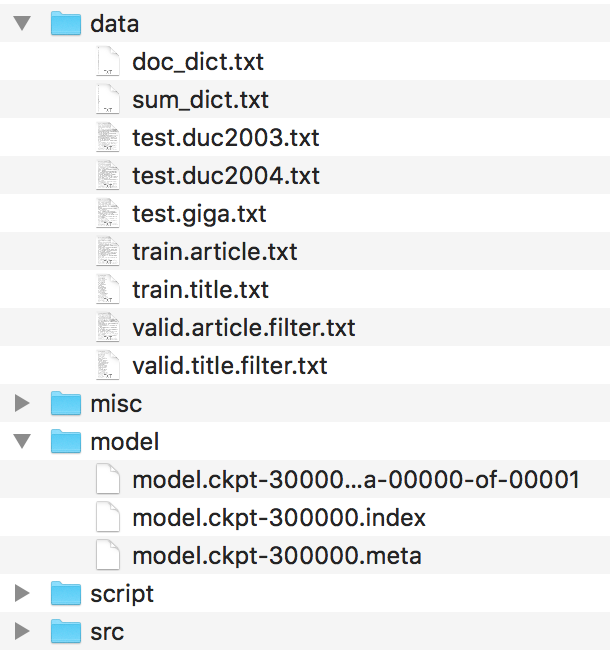
โปรดค้นหาไฟล์เหล่านี้ใน HarvardNLP/SUNT-SUMMARY และเปลี่ยนชื่อเป็น
duc2003/input.txt -> test.duc2003.txt
duc2004/input.txt -> test.duc2004.txt
Giga/input.txt -> test.giga.txt
> python3 script/train.py สามารถทำซ้ำการทดลองที่แสดงด้านล่าง
โดยการทำเช่นนั้นมันจะฝึกอบรมแบทช์ 200k ก่อน จากนั้นสร้างการสร้างบน [giga, duc2003, duc2004] ด้วย beam_size ใน [1, 10] ตามลำดับทุก ๆ 20k แบทช์ มันจะสิ้นสุดที่ 300k แบทช์ นอกจากนี้โมเดลจะถูกบันทึกทุก ๆ 20k แบทช์
> python3 script/test.py จะใช้โมเดลที่ได้รับการปรับปรุงมากที่สุดโดยอัตโนมัติเพื่อสร้างการสร้าง
หากต้องการทำการทดสอบที่กำหนดเองโปรดใส่ข้อมูลอินพุตเป็น
data/test.your_test_name.txt
เปลี่ยน script/test.py บรรทัด 13-14 จาก
datasets = ["giga", "duc2003", "duc2004"]
geneos = [True, False, False]
ถึง
datasets = ["your_test_name"]
geneos = [True]
สำหรับผู้ใช้ขั้นสูง python3 src/summarization.py -h สามารถพิมพ์ความช่วยเหลือได้ โปรดตรวจสอบรหัสสำหรับรายละเอียด
ใน Tensorflow R0.11 และก่อนหน้านี้แนะนำให้ใช้การเก็บข้อมูล R1.0 ให้กรอบ RNN SEQ2SEQ แบบไดนามิกซึ่งเข้าใจได้ง่ายกว่ากลไกการเก็บข้อมูลที่ยุ่งยาก
เราใช้ Dynamic RNN เพื่อสร้างกราฟการคำนวณ มีกราฟการคำนวณเพียงครั้งเดียวในการใช้งานของเรา อย่างไรก็ตามเรายังคงแยกชุดข้อมูลออกเป็นหลายถังและใช้ข้อมูลจากถังเดียวกันเพื่อสร้างแบทช์ ด้วยการทำเช่นนั้นเราสามารถเพิ่มช่องว่างภายในที่น้อยลงนำไปสู่ประสิทธิภาพที่ดีขึ้น
กลไกความสนใจเป็นไปตาม Bahdanau และ อัล
เราติดตามการใช้งานใน tf.contrib.seq2seq เราปรับแต่งฟังก์ชั่น Softmax ให้ความสนใจเพื่อให้ Paddings ได้รับ 0 เสมอ
เพื่อความเรียบง่ายและความยืดหยุ่นเราใช้อัลกอริทึมการค้นหาลำแสงใน Python ในขณะที่ออกจากส่วนเครือข่ายใน TensorFlow ในการทดสอบเราพิจารณา batch_size เป็น beam_size กราฟ Tensorflow จะสร้างเพียง 1 คำจากนั้นรหัส Python บางตัวจะสร้างแบทช์ใหม่ตามผลลัพธ์ โดยการทำซ้ำ ๆ ซ้ำผลการค้นหาลำแสงจะถูกสร้างขึ้น
ตรวจสอบ step_beam(...) ใน bigru_model.py สำหรับรายละเอียด
เราฝึกอบรมแบบจำลองสำหรับแบทช์ 300K ที่มีขนาดแบทช์ 80 เราคลิปสรุปทั้งหมดเป็น 75 ไบต์ สำหรับชุดข้อมูล DUC เรากำจัด EOS และสร้าง 12 คำ สำหรับชุดข้อมูล GIGA เราปล่อยให้โมเดลสร้าง EOS
| ชุดข้อมูล | ขนาดลำแสง | R1-R | R1-P | R1-F | R2-R | R2-P | R2-F | RL-R | RL-P | RL-F |
|---|---|---|---|---|---|---|---|---|---|---|
| DUC2003 | 1 | 0.25758 | 0.23003 | 0.24235 | 0.07511 | 0.06611 | 0.07009 | 0.22608 | 0.20174 | 0.21262 |
| DUC2003 | 10 | 0.27312 | 0.23864 | 0.25416 | 0.08977 | 0.07732 | 0.08286 | 0.24129 | 0.21074 | 0.22449 |
| DUC2004 | 1 | 0.27584 | 0.25971 | 0.26673 | 0.08328 | 0.07832 | 0.08046 | 0.24253 | 0.22853 | 0.23461 |
| DUC2004 | 10 | 0.28024 | 0.25987 | 0.26889 | 0.09377 | 0.08631 | 0.08959 | 0.24849 | 0.23048 | 0.23844 |
| Giga | 1 | 0.3185 | 0.38779 | 0.3391 | 0.14542 | 0.17537 | 0.15393 | 0.29925 | 0.363 | 0.3181 |
| Giga | 10 | 0.30179 | 0.41224 | 0.33635 | 0.14378 | 0.1951 | 0.15936 | 0.28447 | 0.38733 | 0.31664 |


