TensorFlow Summarization
1.0.0
Esta rama utiliza nuevas API TF.Contrib.SEQ2SEQ en TensorFlow R1.1. Para los usuarios de R1.0, consulte la rama TF1.0
Esta es una implementación del modelo de secuencia a secuencia utilizando un codificador GRU bidireccional y un decodificador de Gru. Este proyecto tiene como objetivo ayudar a las personas a comenzar a trabajar en el resumen de texto corto abstracto de inmediato. Y con suerte, también puede funcionar en tareas de traducción automática.
Por favor, consulte Harvardnlp/enviado-sumario.
Descargar
Si desea entrenar el modelo y tener GPU NVIDIA (como GTX 1080, GTX Titan, etc.), configure el entorno CUDA e instale tensorflow-gpu.
> pip3 install -U tensorflow-gpu==1.1
Puede verificar si la GPU funciona por
> python3
>>> import tensorflow
>>>
y asegúrese de que no haya salidas de error.
Si no tiene una GPU, aún puede usar los modelos previos a la aparición y generar resúmenes utilizando su CPU.
> pip3 install -U tensorflow==1.1
Los archivos deben organizarse así.
Encuentre estos archivos en el harvardnlp/enviado-resumen y cambie el nombre de
duc2003/input.txt -> test.duc2003.txt
duc2004/input.txt -> test.duc2004.txt
Giga/input.txt -> test.giga.txt
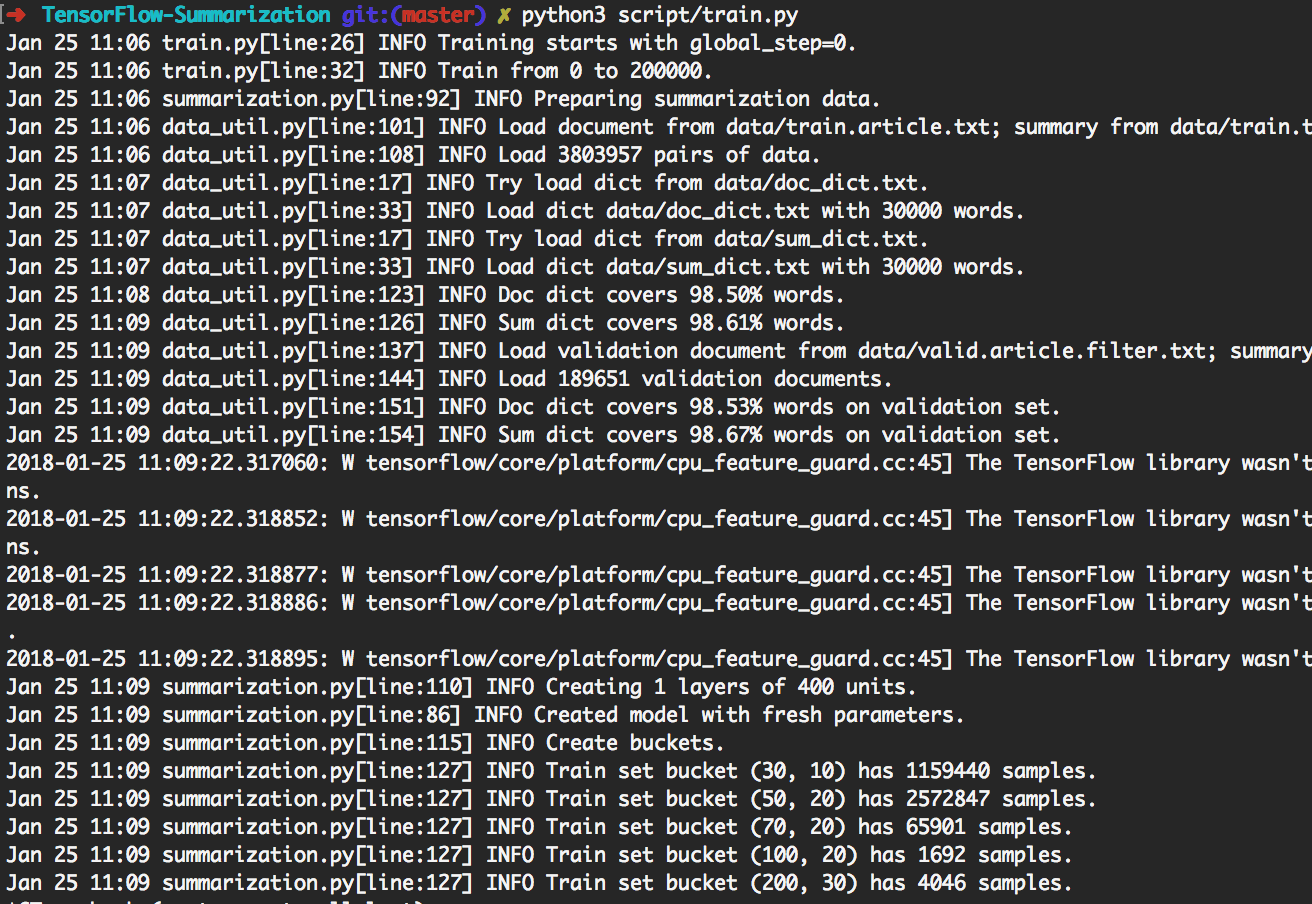
> python3 script/train.py puede reproducir los experimentos que se muestran a continuación.
Al hacerlo, entrenará primero 200k lotes. Luego realice generación en [giga, duc2003, duc2004] con Beam_Size en [1, 10] respectivamente cada 20k lotes. Terminará a 300k lotes. Además, el modelo se guardará cada 20k lotes.
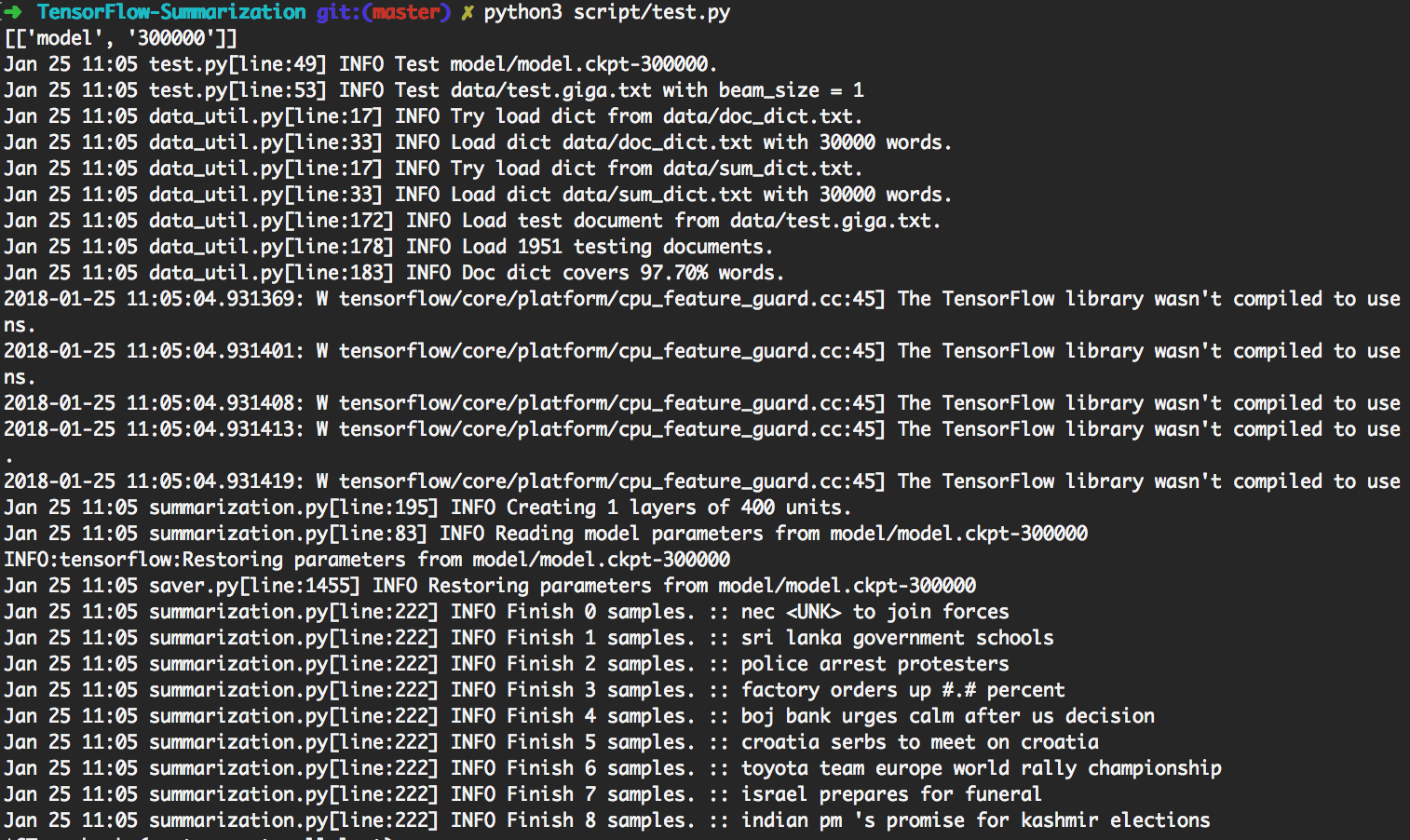
> python3 script/test.py usará automáticamente el modelo más actualizado para hacer la generación.
Para realizar pruebas personalizadas, coloque los datos de entrada como
data/test.your_test_name.txt
Cambiar script/test.py línea 13-14 desde
datasets = ["giga", "duc2003", "duc2004"]
geneos = [True, False, False]
a
datasets = ["your_test_name"]
geneos = [True]
Para usuarios avanzados, python3 src/summarization.py -h puede imprimir ayuda. Consulte el código para obtener más detalles.
En TensorFlow R0.11 y anteriormente, se recomienda el uso de bulleting. R1.0 proporciona el marco dinámico RNN SEQ2SEQ que es mucho más fácil de entender que el mecanismo de facturación difícil.
Utilizamos RNN dinámico para generar un gráfico de cómputo. Solo hay un gráfico informático en nuestra implementación. Sin embargo, todavía dividimos el conjunto de datos en varios cubos y usamos datos del mismo cubo para crear un lote. Al hacerlo, podemos agregar menos relleno, lo que lleva a una mejor eficiencia.
El mecanismo de atención sigue a Bahdanau et. Alabama.
Seguimos la implementación en tf.contrib.seq2seq. Refinamos la función Softmax en la atención para que los rellenos siempre obtengan 0.
Para simplificar y flexibilidad, implementamos el algoritmo de búsqueda de haz en Python mientras dejamos la parte de la red en TensorFlow. En las pruebas, consideramos Batch_Size como Beam_Size. El gráfico TensorFlow generará solo 1 palabra, luego algún código Python creará un nuevo lote de acuerdo con el resultado. Al hacerlo iterativamente, se genera el resultado de búsqueda de haz.
Verifique step_beam(...) en bigru_model.py para obtener más detalles.
Entrenamos el modelo para 300k lotes con el tamaño del lote 80. Recortamos todos los resúmenes a 75 bytes. Para los conjuntos de datos DUC, eliminamos EOS y generamos 12 palabras. Para el conjunto de datos GIGA, dejamos que el modelo genere EOS.
| Conjunto de datos | Tamaño del haz | R1-R | R1-P | R1-F | R2-R | R2-P | R2-F | RL-R | RL-P | RL-F |
|---|---|---|---|---|---|---|---|---|---|---|
| DUC2003 | 1 | 0.25758 | 0.23003 | 0.24235 | 0.07511 | 0.06611 | 0.07009 | 0.22608 | 0.20174 | 0.21262 |
| DUC2003 | 10 | 0.27312 | 0.23864 | 0.25416 | 0.08977 | 0.07732 | 0.08286 | 0.24129 | 0.21074 | 0.22449 |
| duc2004 | 1 | 0.27584 | 0.25971 | 0.26673 | 0.08328 | 0.07832 | 0.08046 | 0.24253 | 0.22853 | 0.23461 |
| duc2004 | 10 | 0.28024 | 0.25987 | 0.26889 | 0.09377 | 0.08631 | 0.08959 | 0.24849 | 0.23048 | 0.23844 |
| giga | 1 | 0.3185 | 0.38779 | 0.3391 | 0.14542 | 0.17537 | 0.15393 | 0.29925 | 0.363 | 0.3181 |
| giga | 10 | 0.30179 | 0.41224 | 0.33635 | 0.14378 | 0.1951 | 0.15936 | 0.28447 | 0.38733 | 0.31664 |


