TensorFlow Summarization
1.0.0
Cabang ini menggunakan API TF.Contrib.seq2seq baru di TensorFlow R1.1. Untuk pengguna R1.0, silakan periksa cabang TF1.0
Ini adalah implementasi model urutan-ke-urutan menggunakan encoder Gru dua arah dan dekoder Gru. Proyek ini bertujuan untuk membantu orang mulai bekerja pada ringkasan teks pendek abstraktif segera. Dan mudah -mudahan, ini juga dapat mengerjakan tugas terjemahan mesin.
Silakan periksa Harvardnlp/Sents-Summary.
Unduh
Jika Anda ingin melatih model dan memiliki NVIDIA GPU (seperti GTX 1080, GTX Titan, dll), silakan siapkan lingkungan CUDA dan pasang TensorFlow-GPU.
> pip3 install -U tensorflow-gpu==1.1
Anda dapat memeriksa apakah GPU berfungsi
> python3
>>> import tensorflow
>>>
dan pastikan tidak ada output kesalahan.
Jika Anda tidak memiliki GPU, Anda masih dapat menggunakan model pretrained dan menghasilkan ringkasan menggunakan CPU Anda.
> pip3 install -U tensorflow==1.1
File harus diatur seperti ini.
Harap temukan file-file ini di Harvardnlp/Sent-Summary dan ganti nama sebagai
duc2003/input.txt -> test.duc2003.txt
duc2004/input.txt -> test.duc2004.txt
Giga/input.txt -> test.giga.txt
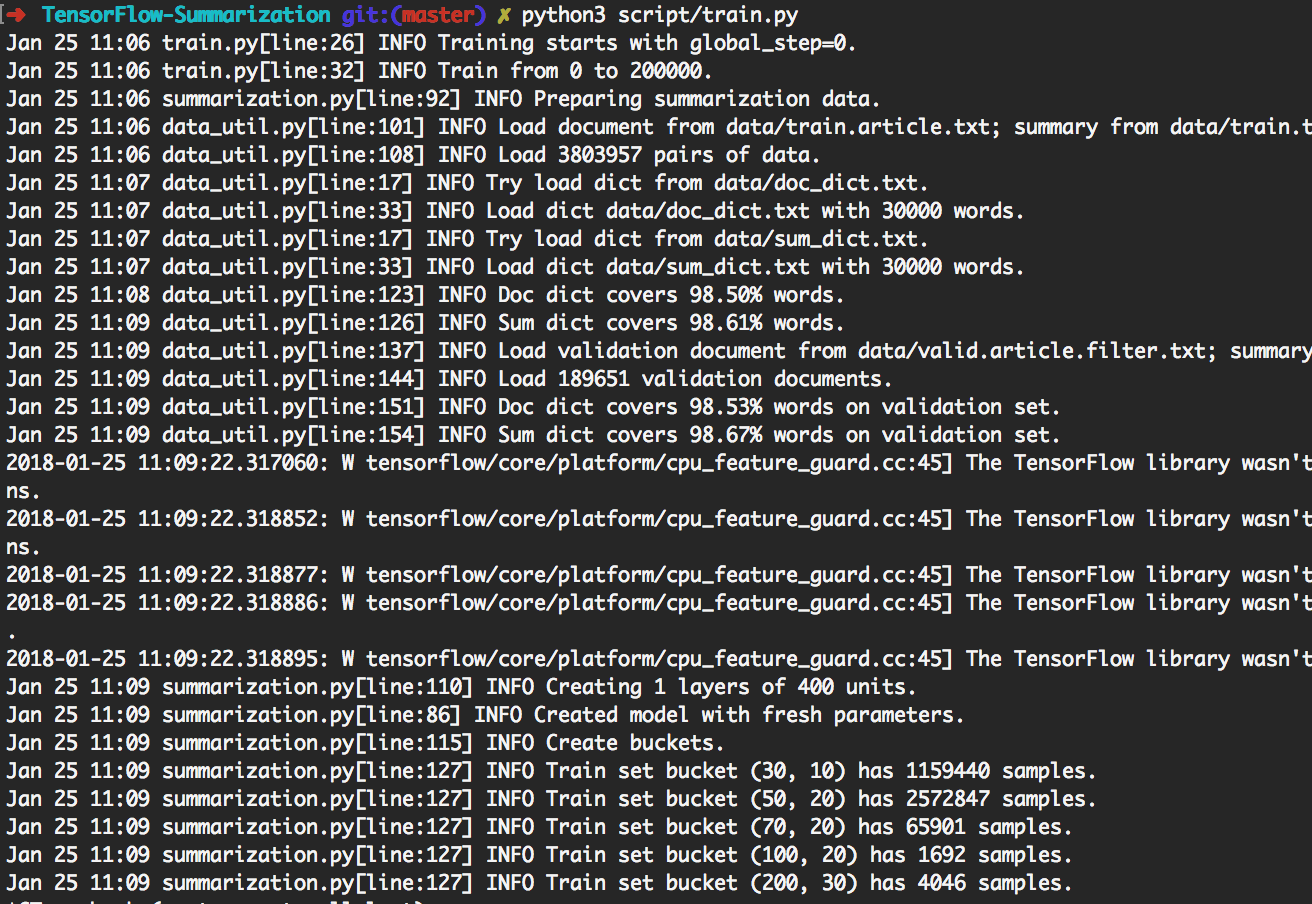
> python3 script/train.py dapat mereproduksi percobaan yang ditunjukkan di bawah ini.
Dengan melakukan itu, itu akan melatih batch 200k terlebih dahulu. Kemudian lakukan generasi pada [giga, duc2003, duc2004] dengan beam_size masing -masing di [1, 10] setiap 20k batch. Ini akan berakhir pada batch 300k. Juga, model akan disimpan setiap 20k batch.
> python3 script/test.py akan secara otomatis menggunakan model yang paling diperbarui untuk dilakukan.
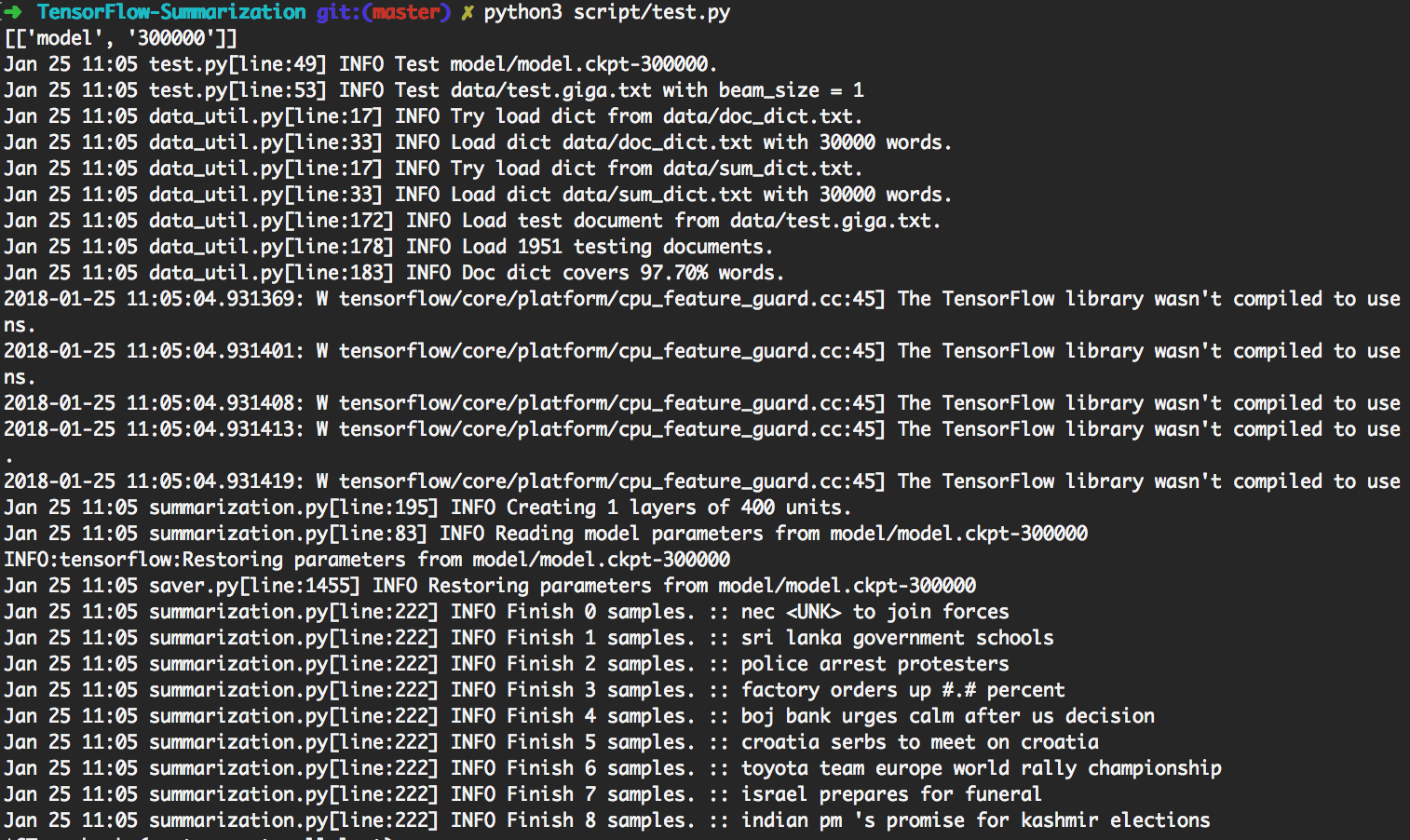
Untuk melakukan tes khusus, harap masukkan data input sebagai
data/test.your_test_name.txt
Ubah script/test.py line 13-14 dari
datasets = ["giga", "duc2003", "duc2004"]
geneos = [True, False, False]
ke
datasets = ["your_test_name"]
geneos = [True]
Untuk pengguna tingkat lanjut, python3 src/summarization.py -h dapat mencetak bantuan. Silakan periksa kode untuk detailnya.
Di TensorFlow R0.11 dan sebelumnya, menggunakan ember direkomendasikan. R1.0 menyediakan kerangka kerja RNN SEQ2SEQ yang dinamis yang jauh lebih mudah dipahami daripada mekanisme ucketing yang rumit.
Kami menggunakan RNN dinamis untuk menghasilkan grafik komputasi. Hanya ada satu grafik komputasi dalam implementasi kami. Namun, kami masih membagi dataset menjadi beberapa ember dan menggunakan data dari ember yang sama untuk membuat batch. Dengan melakukan itu, kita dapat menambahkan lebih sedikit bantalan, yang mengarah ke efisiensi yang lebih baik.
Mekanisme perhatian mengikuti Bahdanau et. al.
Kami mengikuti implementasi di tf.contrib.seq2seq. Kami memperbaiki fungsi softmax dalam perhatian sehingga bantalan selalu mendapatkan 0.
Untuk kesederhanaan dan fleksibilitas, kami mengimplementasikan algoritma pencarian balok di Python sambil meninggalkan bagian jaringan di TensorFlow. Dalam pengujian, kami menganggap Batch_Size sebagai beam_size. Grafik TensorFlow hanya akan menghasilkan 1 kata, maka beberapa kode Python akan membuat batch baru sesuai dengan hasilnya. Secara iteratif melakukannya, hasil pencarian balok dihasilkan.
Periksa step_beam(...) di bigru_model.py untuk detailnya.
Kami melatih model untuk batch 300k dengan ukuran batch 80. Kami klip semua ringkasan menjadi 75 byte. Untuk dataset DUC, kami menghilangkan EOS dan menghasilkan 12 kata. Untuk dataset Giga, kami membiarkan model menghasilkan EOS.
| Dataset | Ukuran balok | R1-R | R1-P | R1-F | R2-R | R2-P | R2-F | RL-R | RL-P | RL-F |
|---|---|---|---|---|---|---|---|---|---|---|
| DUC2003 | 1 | 0.25758 | 0.23003 | 0.24235 | 0,07511 | 0,06611 | 0.07009 | 0.22608 | 0.20174 | 0.21262 |
| DUC2003 | 10 | 0.27312 | 0.23864 | 0.25416 | 0.08977 | 0.07732 | 0.08286 | 0.24129 | 0.21074 | 0.22449 |
| DUC2004 | 1 | 0.27584 | 0.25971 | 0.26673 | 0.08328 | 0.07832 | 0,08046 | 0.24253 | 0.22853 | 0.23461 |
| DUC2004 | 10 | 0.28024 | 0.25987 | 0.26889 | 0.09377 | 0,08631 | 0,08959 | 0.24849 | 0.23048 | 0.23844 |
| Giga | 1 | 0.3185 | 0.38779 | 0.3391 | 0.14542 | 0.17537 | 0.15393 | 0.29925 | 0.363 | 0.3181 |
| Giga | 10 | 0.30179 | 0.41224 | 0.33635 | 0.14378 | 0.1951 | 0.15936 | 0.28447 | 0.38733 | 0.31664 |


