spacy streamlit
v1.0.6
แพ็คเกจนี้มียูทิลิตี้สำหรับการแสดงรุ่น Spacy และการสร้างแอพที่ใช้พลังงาน Spacy แบบโต้ตอบด้วย Streamlit มันรวมถึงการสร้างบล็อกต่างๆที่คุณสามารถใช้ในแอพ Streamlit ของคุณเองเช่น Visualizers สำหรับ การพึ่งพาทางไวยากรณ์ , เอนทิตีที่มีชื่อ , การจำแนกข้อความ , ความคล้ายคลึงกันทางความหมาย ผ่านเวกเตอร์ Word, คุณลักษณะโทเค็นและอื่น ๆ
คุณสามารถติดตั้ง spacy-streamlit จาก PIP:
pip install spacy-streamlit แพ็คเกจรวมถึง การสร้างบล็อก ที่เรียกเข้าสู่ Streamlit และตั้งค่าองค์ประกอบที่จำเป็นทั้งหมดสำหรับคุณ คุณสามารถใช้ส่วนประกอบแต่ละตัวได้โดยตรงและรวมเข้ากับองค์ประกอบอื่น ๆ ในแอพของคุณหรือเรียกฟังก์ชัน visualize เพื่อฝังภาพทั้งหมด
ดาวน์โหลดโมเดลภาษาอังกฤษจาก Spacy เพื่อเริ่มต้น
python -m spacy download en_core_web_smจากนั้นใส่รหัสตัวอย่างต่อไปนี้ในไฟล์
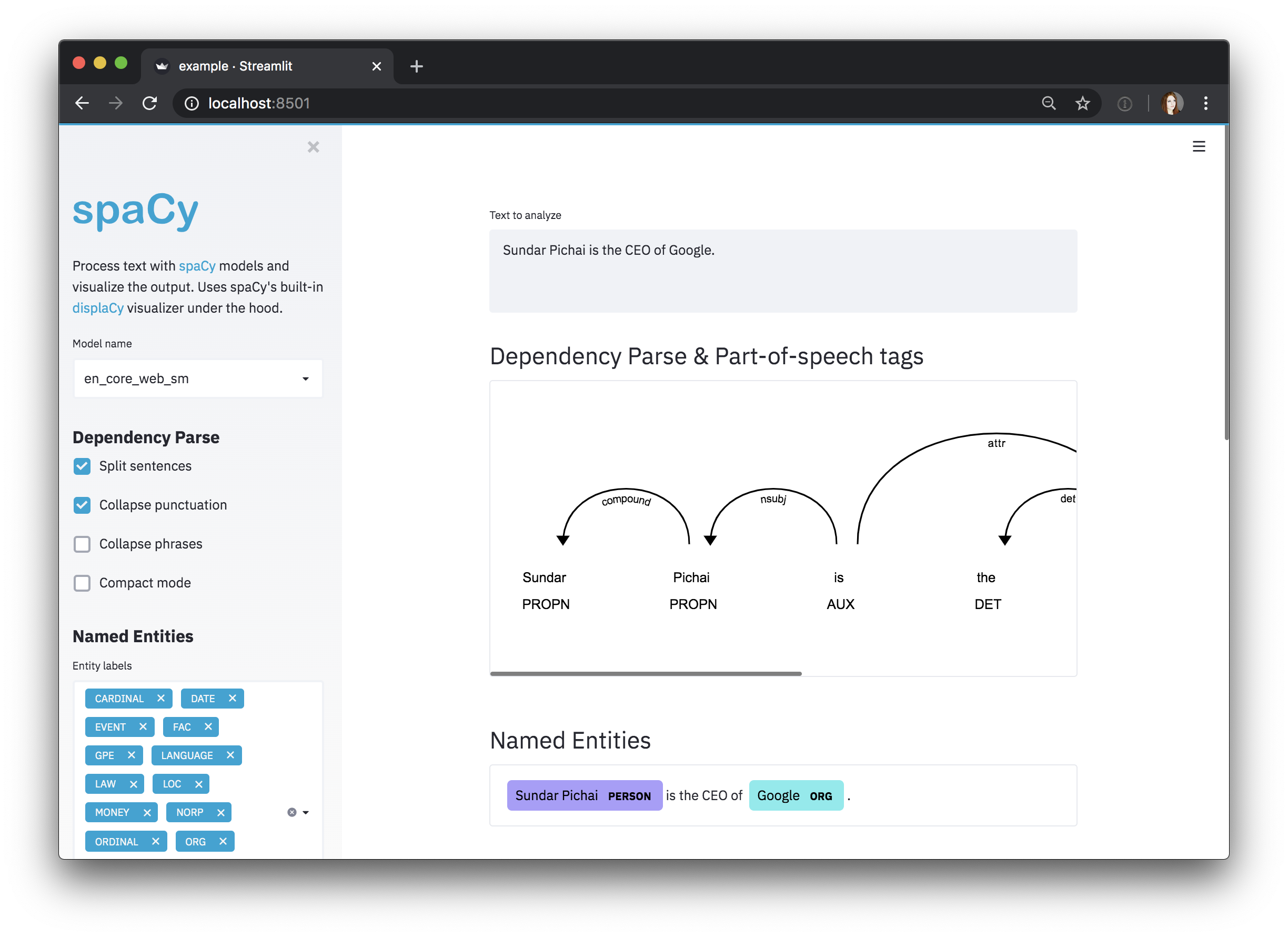
# streamlit_app.py
import spacy_streamlit
models = [ "en_core_web_sm" , "en_core_web_md" ]
default_text = "Sundar Pichai is the CEO of Google."
spacy_streamlit . visualize ( models , default_text ) จากนั้นคุณสามารถเรียกใช้แอปของคุณด้วย streamlit run streamlit_app.py แอพควรปรากฏขึ้นในเว็บเบราว์เซอร์ของคุณ -
01_out-of-the-box.pyใช้ Visualizer ฝังตัวพร้อมการตั้งค่าที่กำหนดเองนอกกรอบ
streamlit run https://raw.githubusercontent.com/explosion/spacy-streamlit/master/examples/01_out-of-the-box.py02_custom.pyใช้ส่วนประกอบแต่ละตัวในแอพที่มีอยู่ของคุณ
streamlit run https://raw.githubusercontent.com/explosion/spacy-streamlit/master/examples/02_custom.py ฟังก์ชั่นเหล่านี้สามารถใช้ในแอพ Streamlit ของคุณ พวกเขาเรียกร้องให้ streamlit ภายใต้ประทุนและตั้งค่าองค์ประกอบที่ต้องการ
visualizeฝังภาพเต็มด้วยส่วนประกอบที่เลือก
import spacy_streamlit
models = [ "en_core_web_sm" , "/path/to/model" ]
default_text = "Sundar Pichai is the CEO of Google."
visualizers = [ "ner" , "textcat" ]
spacy_streamlit . visualize ( models , default_text , visualizers )| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
models | รายการ [str] / dict [str, str] | ชื่อของโมเดล Spacy ที่โหลดได้ (เส้นทางหรือชื่อแพ็คเกจ) โมเดลสามารถเลือกได้ผ่านแบบเลื่อนลง สามารถเป็นรายชื่อชื่อหรือชื่อที่แมปกับคำอธิบายเพื่อแสดงในแบบเลื่อนลง |
default_text | str | ข้อความเริ่มต้นเพื่อวิเคราะห์การโหลด ค่าเริ่มต้นเป็น "" |
default_model | เสริม [STR] | ชื่อเสริมของรุ่นเริ่มต้น หากไม่ได้ตั้งค่าจะใช้รุ่นแรกในรายการของ models |
visualizers | รายการ [STR] | ชื่อของ Visualizers ที่จะแสดง ค่าเริ่มต้นเป็น ["parser", "ner", "textcat", "similarity", "tokens"] |
ner_labels | เป็นทางเลือก [รายการ [str]] | ป้ายกำกับที่จะรวม หากไม่ได้ตั้งค่าป้ายกำกับทั้งหมดที่มีอยู่ในส่วนประกอบท่อ "ner" จะถูกใช้ |
ner_attrs | รายการ [STR] | แอตทริบิวต์ Span ที่แสดงในตารางของเอนทิตีที่มีชื่อ ดู visualizer.py สำหรับค่าเริ่มต้น |
token_attrs | รายการ [STR] | คุณลักษณะโทเค็นที่จะแสดงในโทเค็น Visualizer ดู visualizer.py สำหรับค่าเริ่มต้น |
similarity_texts | tuple [str, str] | ข้อความเริ่มต้นที่จะเปรียบเทียบใน Visualizer ที่คล้ายคลึงกัน ค่าเริ่มต้นเป็น ("apple", "orange") |
show_json_doc | บูล | ปุ่มแสดงเพื่อสลับการแสดง JSON ของ Doc ค่าเริ่มต้นเป็น True |
show_meta | บูล | ปุ่มแสดงเพื่อสลับ meta.json ของไปป์ไลน์ปัจจุบัน ค่าเริ่มต้นเป็น True |
show_config | บูล | ปุ่มแสดงเพื่อสลับ config.cfg ของไปป์ไลน์ปัจจุบัน ค่าเริ่มต้นเป็น True |
show_visualizer_select | บูล | แสดง Dropdown แถบด้านข้างเพื่อเลือก Visualizers เพื่อแสดง (ขึ้นอยู่กับ Visualizers ที่เปิดใช้งาน) ค่าเริ่มต้นเป็น False |
sidebar_title | เสริม [STR] | ชื่อที่แสดงในแถบด้านข้าง ค่าเริ่มต้นถึง None |
sidebar_description | เสริม [STR] | คำอธิบายที่แสดงในแถบด้านข้าง ยอมรับข้อความที่จัดรูปแบบ Markdown |
show_logo | บูล | แสดงโลโก้ Spacy ในแถบด้านข้าง ค่าเริ่มต้นเป็น True |
color | เสริม [STR] | การทดลอง: สีหลักที่จะใช้สำหรับองค์ประกอบ UI หลักบางส่วน ( None การปิดการแฮ็ค) ค่าเริ่มต้นเป็น "#09A3D5" |
get_default_text | callable [[ภาษา], str] | สามารถเรียกได้ว่าเป็นตัวเลือกที่ใช้วัตถุ nlp ที่โหลดในปัจจุบันและส่งคืนข้อความเริ่มต้น สามารถใช้เพื่อให้ข้อความเริ่มต้นเฉพาะภาษา หากฟังก์ชั่นส่งคืน None ค่าของ default_text จะใช้ถ้ามี ค่าเริ่มต้นถึง None |
visualize_parser เห็นภาพการแยกวิเคราะห์การพึ่งพาและแท็กส่วนหนึ่งของคำพูดโดยใช้ Visualizer ของ displacy
import spacy
from spacy_streamlit import visualize_parser
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "This is a text" )
visualize_parser ( doc )| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
doc | Doc | วัตถุ Spacy Doc เพื่อให้เห็นภาพ |
| คำหลักเท่านั้น | ||
title | เสริม [STR] | ชื่อเรื่องของบล็อก Visualizer |
key | เสริม [STR] | คีย์ที่ใช้สำหรับส่วนประกอบ streamlit สำหรับการเลือกฉลาก |
manual | บูล | ธงแสดงว่าอาร์กิวเมนต์ DOC เป็นวัตถุ DOC หรือรายการคำสั่งที่มีข้อมูลแยกวิเคราะห์ |
displacy_options | เป็นทางเลือก [dict] | พจนานุกรมตัวเลือกที่จะส่งผ่านไปยังวิธีการแสดงผลที่ไม่เหมาะสมสำหรับการสร้าง HTML ที่จะแสดงผล ดู: https://spacy.io/api/top-level#options-dep |
visualize_ner เห็นภาพเอนทิตีที่มีชื่อใน Doc โดยใช้ Visualizer ของ displacy
import spacy
from spacy_streamlit import visualize_ner
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "Sundar Pichai is the CEO of Google." )
visualize_ner ( doc , labels = nlp . get_pipe ( "ner" ). labels )| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
doc | Doc | วัตถุ Spacy Doc เพื่อให้เห็นภาพ |
| คำหลักเท่านั้น | ||
labels | ลำดับ [STR] | ฉลากที่จะแสดงในฉลากแบบเลื่อนลง |
attrs | รายการ [STR] | แอตทริบิวต์ SPAN ที่จะแสดงในตารางเอนทิตี |
show_table | บูล | ไม่ว่าจะแสดงตารางเอนทิตีและคุณลักษณะของพวกเขา ค่าเริ่มต้นเป็น True |
title | เสริม [STR] | ชื่อเรื่องของบล็อก Visualizer |
colors | dict [str, str] | พจนานุกรมสีสำหรับเอนทิตีช่วงที่จะเห็นภาพโดยมีปุ่มเป็นป้ายกำกับและสีที่สอดคล้องกันเป็นค่า อาร์กิวเมนต์นี้จะเลิกใช้ในไม่ช้า ในอนาคตสี arg จะต้องส่งผ่านใน displacy_options arg ด้วยคีย์ "สี") |
key | เสริม [STR] | คีย์ที่ใช้สำหรับส่วนประกอบ streamlit สำหรับการเลือกฉลาก |
manual | บูล | การตั้งค่าสถานะหมายถึงว่าอาร์กิวเมนต์ DOC เป็นวัตถุ DOC หรือรายการของ dicts ที่มีช่วงเอนทิตี |
| ข้อมูล. | ||
displacy_options | เป็นทางเลือก [dict] | พจนานุกรมตัวเลือกที่จะส่งผ่านไปยังวิธีการแสดงผลที่ไม่เหมาะสมสำหรับการสร้าง HTML ที่จะแสดงผล ดู https://spacy.io/api/top-level#displacy_options-ent |
visualize_spans เห็นภาพช่วงใน Doc โดยใช้ Visualizer ของ displacy
import spacy
from spacy_streamlit import visualize_spans
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "Sundar Pichai is the CEO of Google." )
span = doc [ 4 : 7 ] # CEO of Google
span . label_ = "CEO"
doc . spans [ "job_role" ] = [ span ]
visualize_spans ( doc , spans_key = "job_role" , displacy_options = { "colors" : { "CEO" : "#09a3d5" }})| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
doc | Doc | วัตถุ Spacy Doc เพื่อให้เห็นภาพ |
| คำหลักเท่านั้น | ||
spans_key | ลำดับ [STR] | ซึ่งครอบคลุมกุญแจสำคัญในการแสดงผลจาก ค่าเริ่มต้นคือ "SC" |
attrs | รายการ [STR] | แอตทริบิวต์ในช่วงเอนทิตีที่จะติดป้าย แอตทริบิวต์จะปรากฏขึ้นเฉพาะเมื่ออาร์กิวเมนต์ show_table เป็นจริง |
show_table | บูล | ไม่ว่าจะแสดงตารางของช่วงและคุณลักษณะของพวกเขา ค่าเริ่มต้นเป็น True |
title | เสริม [STR] | ชื่อเรื่องของบล็อก Visualizer |
manual | บูล | ธงแสดงว่าอาร์กิวเมนต์ DOC เป็นวัตถุ DOC หรือรายการของ dicts ที่มีข้อมูลการขยายเอนทิตี |
displacy_options | เป็นทางเลือก [dict] | พจนานุกรมตัวเลือกที่จะส่งผ่านไปยังวิธีการแสดงผลที่ไม่เหมาะสมสำหรับการสร้าง HTML ที่จะแสดงผล ดู https://spacy.io/api/top-level#displacy_options-span |
visualize_textcatแสดงภาพหมวดหมู่ข้อความที่คาดการณ์โดยตัวจําแนกข้อความที่ผ่านการฝึกอบรม
import spacy
from spacy_streamlit import visualize_textcat
nlp = spacy . load ( "./my_textcat_model" )
doc = nlp ( "This is a text about a topic" )
visualize_textcat ( doc )| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
doc | Doc | วัตถุ Spacy Doc เพื่อให้เห็นภาพ |
| คำหลักเท่านั้น | ||
title | เสริม [STR] | ชื่อเรื่องของบล็อก Visualizer |
visualize_similarityเห็นภาพความคล้ายคลึงกันโดยใช้เวกเตอร์คำของโมเดล จะแสดงคำเตือนหากไม่มีเวกเตอร์อยู่ในแบบจำลอง
import spacy
from spacy_streamlit import visualize_similarity
nlp = spacy . load ( "en_core_web_lg" )
visualize_similarity ( nlp , ( "pizza" , "fries" ))| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
nlp | Language | วัตถุ nlp ที่โหลดพร้อมเวกเตอร์ |
default_texts | tuple [str, str] | ข้อความเริ่มต้นที่จะเปรียบเทียบกับโหลด ค่าเริ่มต้นเป็น ("apple", "orange") |
| คำหลักเท่านั้น | ||
threshold | ลอย | เกณฑ์สำหรับสิ่งที่ถือว่า "คล้ายกัน" หากคะแนนความคล้ายคลึงกันมากกว่าเกณฑ์ผลลัพธ์จะแสดงว่าคล้ายกัน ค่าเริ่มต้นถึง 0.5 |
title | เสริม [STR] | ชื่อเรื่องของบล็อก Visualizer |
visualize_tokens เห็นภาพโทเค็นใน Doc และคุณลักษณะของพวกเขา
import spacy
from spacy_streamlit import visualize_tokens
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "This is a text" )
visualize_tokens ( doc , attrs = [ "text" , "pos_" , "dep_" , "ent_type_" ])| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
doc | Doc | วัตถุ Spacy Doc เพื่อให้เห็นภาพ |
| คำหลักเท่านั้น | ||
attrs | รายการ [STR] | ชื่อของแอตทริบิวต์โทเค็นที่จะใช้ ดู visualizer.py สำหรับค่าเริ่มต้น |
title | เสริม [STR] | ชื่อเรื่องของบล็อก Visualizer |
ผู้ช่วยเหล่านี้พยายามแคชโมเดลที่โหลดและสร้างวัตถุ Doc
process_text ประมวลผลข้อความด้วยรูปแบบของชื่อที่กำหนดและสร้างวัตถุ Doc โทรเข้าสู่ตัวช่วย load_model เพื่อโหลดโมเดล
import streamlit as st
from spacy_streamlit import process_text
spacy_model = st . sidebar . selectbox ( "Model name" , [ "en_core_web_sm" , "en_core_web_md" ])
text = st . text_area ( "Text to analyze" , "This is a text" )
doc = process_text ( spacy_model , text )| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
model_name | str | ชื่อโมเดล Spacy ที่โหลดได้ สามารถเป็นเส้นทางหรือชื่อแพ็คเกจ |
text | str | ข้อความที่จะดำเนินการ |
| ผลตอบแทน | Doc | เอกสารที่ประมวลผล |
load_model โหลดโมเดล Spacy จากเส้นทางหรือแพ็คเกจที่ติดตั้งและส่งคืนวัตถุ nlp ที่โหลด
import streamlit as st
from spacy_streamlit import load_model
spacy_model = st . sidebar . selectbox ( "Model name" , [ "en_core_web_sm" , "en_core_web_md" ])
nlp = load_model ( spacy_model )| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
name | str | ชื่อโมเดล Spacy ที่โหลดได้ สามารถเป็นเส้นทางหรือชื่อแพ็คเกจ |
| ผลตอบแทน | Language | วัตถุ nlp ที่โหลด |


